Pensamiento Matemático
proceptual-simbólico
Eduardo Ochoa Hernández
Nicolás Zamudio Hernández
Filo Enrique Borjas García
Rogelio Ochoa Barragán

Lección 19: Estadística
La estadística, un poeta diría, “es la que nos permite mirar través de la niebla bizarra del mundo sobre nosotros”. Para comprender la realidad subyacente del significado de los datos, la estadística es una tecnología de métodos que nos permiten extracción del significado dentro de esa niebla. La estadística es esa tecnología para el manejo de la incertidumbre, ese anhelo del hombre de predecir los eventos futuros. Las inferencias acerca de esa neblina, esas que nos arroja datos de lo desconocido para tomar decisiones, previsiones, análisis de la dinámica de la realidad, son la tarea de las estadísticas. Pero porque llamarla tecnología y no una disciplina científica. Una tecnología es la aplicación de los conocimientos científicos, la estadística es la aplicación del conocimiento del cómo refiere a complementar e inferir la información en los datos de la neblina y realizar inferencias sobre sus significados. Una estadística es un hecho numérico o resumen de análisis de datos. Así que de cierta manera un resumen de datos es el que incluye: tamaño, tasas, desviaciones, tendencias y el cómo se recopiló, manipuló, analizó y se dedujo sobre los hechos numéricos. La neblina puede ser una nube de partículas, una sociedad, el espacio climatológico, reacciones químicas, biológicas o el comportamiento de enjambres, parvadas o corrientes moleculares en un recipiente.
Los datos, es una palabra que hace énfasis en la “referencia”, significa algo dado sobre alguna parcela de la realidad. Frases como: los datos nos indican; los datos demuestran; los datos muestran; los datos corroboran la teoría. Los datos son señales de algún tipo sobre algo que está fuera de nuestra mente, ese algo está allí, con independencia y las matemáticas buscan dotarnos de un significado racional sobre eso llamado realidad. El dato tiene significado gracias al cobijo de los hechos. Un hecho es un concepto frontera entre nuestro lenguaje y la realidad, estos conceptos dan el sentido necesario a los datos, que bajo esa semántica categorizan las señales de la realidad. Cuando los datos son procesados por la estadística, se genera un producto estructurado conocido como información. La información es el paso necesario para realizar inferencias (acciones de razonamiento) que eventualmente agrupando inferencias, se produce el pensamiento abstracto que da origen al conocimiento.
Las señales de esa neblina llamada realidad, son comúnmente datos numéricos, producto de realizar ensayos de medición. En teoría si pudiéramos realizar mediciones infinitas sobre un algo, los datos significarían una versión precisa de lo que estamos observando. Mediciones infinitas, no es posible realizarlas, ya sea por cuestiones de tiempo, costo, recursos humanos y tecnológicos. Lo que representan los datos no es la imagen perfecta, no solo por estar impedidos a realizar mediciones infinitas, sino por la propia calidad del dato, toda medición se enfrenta con el error, el ruido e incertidumbre. Sin embargo, los logros asombrosos de la estadística para generar nuevo conocimiento están por todos lados en la vida moderna. Los datos en un principio antes de ser números fueron señales de palabras, colores, sabores, emociones, sonidos, texturas, concentraciones de químicos, movimiento de partículas en el viento. El control de calidad de fármacos, refrescos, automóviles,…, en general todo producto industrial se traduce a números para expresarlo en término de estructuras de información, es decir, en forma de gráficos, ecuaciones, señales de alerta, frases ,…
La controversia sobre las estadísticas, radica no en sus procesos de datos, sino en cómo se utilizan las deducciones para sacar juicios a conveniencia. El papel moderno de la educación es reducir la desconfianza mediante el entendimiento del rigor de la estadística, y justamente advertir que es en la interpretación del resumen estadístico donde hay que poner atención para reconocer si hay justificación para tales inferencias. En muchos casos reportes de investigación sustentan que comer ciertos alimentos son dañinos para la salud humana, basados en juicios estadísticos. Pero el avance científico a nivel de mayor detalle dentro de la complejidad biológica pronto desmiente tales aseveraciones, no a la estadística, sino a las inferencias sobre el resumen estadístico. No es de extrañar que este oficio de las inferencias sobre resúmenes estadísticos, genere conflictos de contradicción.
Datos
Hemos expresado que los datos son la materia prima de la construcción de estructuras de información, son la base objetiva del resumen estadístico que normalmente se expresa en números. Los datos son el resultado de los hechos, son más que números, son el fruto del análisis conceptual de la teoría, es decir, los números deben asociarse con el significado de los hechos. No hay datos posibles que sean precisos y válidos en su calidad, si estos no están respaldados por conceptos sólidos que se justifican en el marco teórico. Además, los datos deben ser en muchos casos vigentes, confiables en el aspecto tecnológico de la medición y el instrumento de registro de su valor verdadero. Otra manera de mirar los datos, es considerarlos como pruebas o evidencias que dan fundamento a ideas y teorías sobre el mundo que nos rodea. Los datos son la conexión con las afirmaciones de nuestras ideas, son los que resquebrajan las viejas ideas e impulsan a las nuevas. Además, los datos no son inmunes a fallas de equipos y límites tecnológicos de los rangos de operación de instrumentos de medición, sin embargo, los datos nos dan certidumbre y tranquilidad sobre nuestras ideas que intentan ser referencia a la verdad en la realidad.
Esto implica que, para ser significativos nuestras ideas y discursos argumentales deben pasar por la verificación objetiva de referencia a los datos. Al comparar nuestros datos con las predicciones podemos confiar o razonablemente abandonar alguna teoría al demostrar su sesgo. Los datos son el camino de exploración a través de este mundo complejo, ellos guían nuestras decisiones sobre los mejores y más prometedores nichos de oportunidad. Dado el papel de los datos para justificar las ideas y la compresión del mundo.
El origen de la estadística es relativamente reciente, unos docientos años. La Royal Statistical Society 1834, sin embargo, antes de su reconocimiento académico, las primeras estadísticas nacieron en el cálculo de probabilidades en juegos de azar, por necesidad de extraer significado razonable de ellos. Otro camino surge al intentar responder a la necesidad de datos estadísticos para tomar decisiones de gobierno en materia militar, económica y cultural. Y es de esta última necesidad que surgió el nombre de estadística: “datos sobre el estado”. Todos los países modernos tienen a ahora alguna institución para realizar estudios estadísticos. En el siglo XIX la estadística era un discurso de exploración sobre los datos sociales. Pero es principios del siglo XX con la pujante Mecánica Cuántica que su cuerpo de conocimiento se desarrolló matemáticamente. Y es en los años 70’s que la estadística se vuelve emocionante al emplear en tiempo real computadoras, potenciando como nadie imagino una gran cantidad de cálculos de manipulación aritmética que previamente hubiera llevado años, ahora se realiza en minutos. A finales del Siglo XX también se observó la aparición de analistas de datos sobre patrones en grandes volúmenes de datos. Aprender de los datos es sin duda el objetivo de la estadística, es decir, se trata de investigar dentro de lo más complejo de la neblina que llamamos realidad.
Empresas pequeñas y grandes se basan en el control de calidad y en la proyección del futuro de su desempeño, todo a partir del análisis de sus datos y de otros competidores. Estas personas no manipulan símbolos matemáticos y fórmulas, pero están usando herramientas informáticas estadísticas y métodos para obtener conocimiento y entendimiento de la evidencia de los datos. Al hacerlo, necesitan considerar una amplia gama de variables de cuestiones intrínsecamente no matemáticas, tales como la calidad de los datos, cómo fueron recogidos, definir el problema, identificar el objetivo más amplio del análisis y determinar cuánta incertidumbre se asocia con la conclusión.
La estadística es ubicua, se aplica en todos los ámbitos de la vida, esto motivó el desarrollo de métodos nuevos y herramientas estadísticas más especificas. El procesamiento de datos del ADN, partículas subatómicas y redes sociales es solo un ejemplo de estos nuevos horizontes de la estadística. Los métodos estadísticos están en la esencia de la investigación científica, en las operaciones industriales, en la administración pública, en la industria, la medicina y otros aspectos de la vida social humana. El desarrollo de alimentos y medicamentos deben pasar por exhaustivas pruebas estadísticas antes de estar en el mercado. Dado este papel fundamental, claramente es importante para los ciudadanos educados de esta era, para ser conscientes de los instrumentos de toma de decisiones y exploración de lo complejo. Además, la estadística moderna hace uso intensivo de software para procesar los datos, no debe vérsele como manipulación aritmética tediosa de números, este objetivo es fundamental para el interés de las jóvenes generaciones.
El problema con este punto de vista es que puede verse a la estadística como una disciplina de colección de métodos, todos ellos desconectados en la manipulación de números. Por contrario, es un todo conectado, construido en principios profundamente filosóficos, tal como muchas ciencias lo son. Las herramientas de análisis de datos están vinculadas y relacionadas, algunas pueden incluir a otras herramientas como parte de su estructura.
Todo comenzó con la definición de dato. Piezas numéricas que describen al universo que estudiamos. Un universo es una parcela de la realidad que es inagotable en su información potencial. Podría ser una mezcla química, un sistema térmico, un sistema mecánico, transacciones de tarjetas de crédito, desempeño de lectura de estudiantes, productividad intelectual de docentes o simples lanzamientos de dados. En ellos no hay nada de particular que modifique la idea de dato. Por supuesto una colección finita de datos no puede agotar la información contenida sobre algo que es infinito para su descripción. Eso significa que debemos ser cautos de posibles deficiencias o lagunas de los datos. Al capturar los datos debemos además de cuidar su calidad, asegurar que representan los aspectos que deseamos sacar alguna conclusión. Al capturar datos nos vemos en la necesidad eliminar los que son irrelevantes o claramente erróneos. Producir datos está dirigido a objetivos de conocimiento y los aspectos que definen los atributos, características, funciones o aspectos técnicos del objeto de estudio que se les suele llamar variables. No solamente se interesa por un objeto de estudio, sino además por las relaciones entre objetos distintos. Muchos no ven los datos como la belleza del mundo, sienten que es como eliminar su poética. Pero los números tienen el potencial para poder percibir esa belleza, esa estética profunda más allá de nuestros sentidos sensoriales. Sin duda, la estadística es una forma objetiva de revelar lo profundo de sistemas altamente complejos, en los que por pereza intelectual se les suele evadir con salidas como: allí no hay más que desorden, además los números son solo un valor de magnitud. Hemos visto que los números nos dan una interfaz más directa e inmediata a los fenómenos estudiados que el discurso de palabras, porque los datos numéricos normalmente son producidos por instrumentos con más confiabilidad que nuestras palabras. Los números proceden de la cosa estudiada, mientras las palabras son imaginación, los datos son una ventana a través de la lente de instrumentos muy sofisticados de medición. La propia historia de la tecnología es evidencia del arte de representar la realidad con números referidos a datos. En resumen, mientras simples números constituyen los datos, mirar sus raciones entre ellos y quizá combinarlos es donde surge la estadística. El análisis estadístico revela la forma en que están distribuidos estos valores. El valor representativo de media estadística es un primer indicador de la distribución de datos.
Media estadística
Es uno de los tipos más básicos de la descripción de datos. Es una medida de tendencia central sobre un conjunto de números. Es decir, es el promedio de una lista de números, y sea hace más útil si la lista es muy grande. Para fines de calificación, edad o estaturas nos ayuda a tomar decisiones en dónde está el grueso de los datos. Qué entenderemos por media estadística o media aritmética. Imagine una tabla con un millón de datos, todos ellos son el mismo número, la media aritmética se calcula más fácilmente sumando el total de los números y dividiendo este resultado entre cuantos son.
Por ejemplo, las calificaciones de un estudiante en el semestre fueron 7+9+6+4+9+10, suman 45. La media aritmética de un número de un conjunto de números, que se encuentra dividiendo a 45 entre en número total de datos, en este caso es 6. Es 7 1/2. Obtendríamos el mismo resultado si cada una de las 6 evaluaciones fueran 7 1/2, esto serie una distribución de media estadística.
![]()
Donde n es igual al número de datos, y las ![]() son cada uno de los datos.
son cada uno de los datos.
La media aritmética siempre toma un valor entre los valores mayor y menor del conjunto de datos. Por otra parte, equilibra los números en el conjunto, en el sentido de que la suma de las diferencias entre la media aritmética y los valores más grandes, es exactamente igual a la suma de las diferencias entre la media aritmética y los valores más pequeños. En este sentido, es un valor central. La media es la distancia de un tablón desde el extremo a un pivote colocado allí y que perfectamente equilibraría el tablón. La media aritmética es una estadística. Esta resume el conjunto de valores en nuestra colección de datos eso la hace importante.
La mediana equilibra el conjunto de otra manera, es el valor tal que la mitad de los números en el conjunto de datos son más grandes y la mitad son menores. Por ejemplo, colocamos los datos en forma creciente del ejemplo anterior 4,5,7,9,9,10;
![]()
la mediana es el promedio de los dos valores centrales =8.
![]()
Si n es impar la mediana es el valor que ocupa la posición (n+1)/2
Si n es par la mediana es la media aritmética de los dos valores centrales.
La mediana es un valor estadístico representativo distinto al valor de la media. Obviamente es más fácil de calcular que la media. Pero en realidad esta ventaja si usamos una computadora, se vuelve irrelevante dado que ella absorbe el tedio de realizar los procesos aritméticos. Para elegir la utilidad de la mediana o la media, dependerá de la precisión de detalle sobre la colección de datos que estemos buscando. Si queremos precisión de la medida central usamos la media.
La media y la mediana, no son los únicos dos resúmenes estadísticos, otro importante es la moda. Es el valor tomado con mayor frecuencia en una muestra. Por ejemplo para la colección de datos 4,5,7,9,9,10; la moda es 9.
Dispersión
Los promedios, como la media y la mediana, proporcionan un resumen estadístico de un solo número sobre la colección total de los datos. Son útiles porque nos dan los valores numéricos de una tendencia central. Pero esto nos puede ser engañoso, en particular estos valores individuales pueden diferir sustancialmente de los valores individuales en un conjunto de datos en términos de las distancias respecto a la centralidad media. Es decir, es necesario dar cuenta de lo disperso de los datos alrededor de la media. Los resúmenes estadísticos de dispersión proporcionan esta información. La medida de dispersión más simple es el rango.
El rango se define como la diferencia entre los valores mayor y menor del conjunto de datos. El rango tiene la propiedad de aportar información de la dispersión de los datos, de una manera muy sencilla. Sin embargo, se siente que no es muy ideal. Después de todo ignora la mayoría de los datos, no puede encontrar el hecho de dónde se encuentra la mayor densidad alrededor de la media. Es deficiencia se puede superar mediante el uso de una medida de dispersión que toma a todos los valores en cuenta.
Una forma de hacer esto, es tomar la diferencia entre la media aritmética y cada número del conjunto de datos al cuadrado y luego encontrar la media de estas diferencias cuadradas. Si la media resultante de las diferencias cuadradas es pequeña, nos dice que, en promedio los números son demasiado diferentes de su promedio. Es decir, ellos no son muy dispersos. Esta medida de la diferencia de cuadrados se llama varianza de los datos o desviación cuadrada media.
Una complicación surge del hecho de que la varianza implica al valor de el cuadrado de los datos. La varianza es una media de los valores cuadrado. Si medimos la productividad de páginas escritas, estamos hablando del promedio de páginas cuadradas. Es obvio que no hacemos esto. Debido a esta dificultad, es común tomar la raíz cuadrada de la varianza. Esto cambia las unidades, a las unidades originales y produce la media de dispersión llamada desviación estándar. La media se le suele conocer también como esperanza matemática, es el valor medio esperado E.
![]() Varianza
Varianza
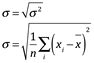 Desviación estándar
Desviación estándar
La desviación estándar supera el problema que identificamos con el rango, al emplear todos los datos. Esta desviación típica, si la mayoría de los datos están agrupados muy cerca, con pocos periféricos, se reconocerán por la desviación estándar pequeña. Por contrario, si los datos toman valores muy lejanos de la esperanza matemática, la desviación estándar será mucho mayor su valor.
Oblicuidad
Si bien las medidas de dispersión nos dicen cuánto se desvían los valores individuales de datos unos de otros. Pero no nos dicen de qué manera se desvían. En particular, no nos dicen si las desviaciones más grandes tienden a ser los valores más grandes o los valores más pequeños del conjunto de datos. Para detectar esta diferencia, necesitamos de otro resumen estadístico, uno que recoge y mida la asimetría en la distribución de valores de los datos. Un tipo de asimetría de valores se llama sesgo. Las distribuciones sesgadas son muy comunes. Un ejemplo clásico es la distribución de la riqueza en la sociedad, en la que la mayoría de las personas esta en valores pequeños y unos cuantos en valores mayores de riqueza. Es justo por lo dispar de los sueldos. El sesgo es un estimador entre la diferencia de su media y el valor numérico del parámetro que se estima dentro de un conjunto de datos.