Texto universitario

_____________________________
Módulo 4. Probabilidad y certeza
4.1 Formar el instinto científico
Investigar sobre el conocimiento científico y su metodología a la luz de superar el hecho obvio del prejuicio y descuido de la creencia de que este conocimiento es una cuestión de todo o nada, en su lugar preferimos decir es susceptible a diversos grados de intensidad de verdad. Más concretamente nuestro objetivo es tratar con el problema de la inducción y la paradoja de confirmación, así como lidiar con las preguntas sobre postulados en el realismo, las pruebas estadísticas relativas a los méritos de predicción, calidad de los datos y el valor probatorio de la información. Todo esto sin duda es terreno de la probabilidad subjetiva.
Los términos probabilísticos están íntimamente formulados con nuestra idea de evidencia, que nos ayuda a tener claridad y precisión, disipar la confusión y, por lo tanto, facilita la tarea de agenciar conocimiento. Discutir las ideas, es una actividad de escritura argumentativa, con el objetivo de producir una narrativa justificada de ciertos fenómenos y efectos, es la estructura discursiva de proposiciones, evidencias, datos, inferencias…, que por lo general la intuición llama teoría. Es una empresa en la que típicamente, nos enfrentamos a razones aparentemente buenas para aceptar tanto P, como no-P. En tales casos el problema no es formular y defender una teoría que dictará cuál de las proposiciones es verdaderas dentro de sus contradicciones mutuas, sino más bien descubrir en nosotros mismos las fuentes de nuestras inclinaciones contradictorias. Es la idea de Wittgenstein de la filosofía pura, sin teorías, solo reunir justificaciones para un propósito particular, es una batalla contra el hechizo de nuestra inteligencia por medio del lenguaje.
Debe subrayarse que, desde este punto de vista, no hay ninguna razón general para impugnar la legitimidad o el valor de cualquier otra cosa que se haga en nombre de la ciencia, y no hay necesidad de preocuparse por cómo debe utilizarse esa palabra. Es cierto que hay manuscritos malos, aquellos que descansan sobre presunciones erróneas o se rigen por una colección nebulosa de condiciones de adecuación. Estos, a través de la confusión que producen, pueden engendrar extravío. Todo proyecto de disertación debe ser coherente, siempre que exista en el escritor una comprensión definitiva de cómo debe reconocer el logro de conocimiento. Y sus resultados a veces pueden iluminar un concepto problemático y constituir justificaciones eficaces en la lucha por mantener una visión precisa del acto profundo de conciencia. El elemento de lo que hemos llamado filosofía científica consiste en la caracterización precisa de una noción de grado de creencia, diseño para tener la propiedad fructífera que los grados racionales de creencia deben ajustarse al cálculo de la probabilidad, este valor epistémico es sustancial de la ciencia experimental moderna y en la explicación, es el marco de la probabilidad subjetiva, que impacta en los conceptos metodológicos como: la confirmación, postulado ad hoc, y evidencia diversa. No afirmamos que los fundamentos de la probabilidad sean absolutamente seguros, ni que nuestro camino sea la única o la mejor manera de capturar nuestra idea de sentido común de grado de confianza. Puede ser que para otros fines, como la teoría matemática, la práctica tecnológica que no comprometa grados de creencia a valores numéricos precisos sea una mejor opción para estimar el grado de confianza. Lo que se quiere aquí es solo que las explicaciones sean lo suficientemente fieles y sencillas para permitir una percepción clara de los problemas que se están discutiendo y para permitir que la confusión y los conceptos erróneos que los produjeron sean expuestos y eliminados de nuestro oficio intelectual. Desafíos:
1) Acomodamiento de datos. Nos inclinamos a creer teorías que hacen predicciones precisas y acomodan resultados experimentales, y en el mismo sentido teorías poco creíbles cuyas consecuencias son incompatibles con nuestro datos. Esto no debería requerir ilustración dentro de la comunidad académica que busca fortalecer su tradición intelectual. Sin embargo, vale la pena destacar la conocida asimetría entre verificación y falsificación. Si se sabe que una teoría implica algo falso, se refuta de manera concluyente; pero si se sabe que implica algo verdadero, la teoría no se toma así como confirmada de manera concluyente, sino que, en el mejor de los casos, simplemente se apoya. En otras palabras, sus predicciones erróneas indican que la teoría debe ser abandonada o al menos revisada en parte.
2) Evidencia estadística. La afirmación, sobre algún experimento, de que la probabilidad de un determinado resultado es X, se toma para ser apoyado si aproximadamente xn tales resultados, en una larga secuencia de n instancias del experimento, se obtienen; y se desconfía si la proporción de casos con ese resultado difiere sustancialmente de X. En particular, si 100 lanzamientos consecutivos de una moneda se cargan a una cara, comenzamos a dudar de que la moneda es justa. En tales casos, los hechos observados no implican que no están absolutamente excluidos por la hipótesis de que se trata. Pero son, sin embargo, de gran importancia probatoria, y sería deseable tener algunas razones explícitas para nuestra práctica e intuiciones con respecto a la confirmación de hipótesis probabilística empírica.
3) Pruebas severas. Las teorías se prueban o se confirman en cierta medida si pasan audaces experimentos; pero están bien confirmadas solo si las pruebas son severas. Por ejemplo, si se usan instrumentos de medición de alta precisión, tenderán a promover la severidad de una prueba experimental, haciendo más difícil que la teoría pase y más impresionante si lo hace. Sin embargo, queda por ver lo que se entiende en general por “una prueba severa”, y por qué la supervivencia a través de tales cosas debería dar un impulso especial a la credibilidad de una teoría.
4) Predicciones. El apoyo particularmente poderoso a una teoría se transmite por la verificación de sus predicciones relativamente por verosimilitud. En otras palabras, una teoría recibe mucho crédito por predecir algo bastante insospechado, o por explicar un fenómeno extraño y anómalo, y deriva relativamente poco apoyo de la predicción de algo que esperábamos que ocurra de todos modos. Así, por ejemplo, la teoría especial de la relatividad de Einstein predice que los relojes que se mueven a alta velocidad, cerca de la velocidad de la luz, correrán lentamente en comparación con los relojes en reposo en nuestro marco de referencia y a esto se llama “dilatación del tiempo”, un fenómeno detectable. También predice que aunque el mismo efecto se manifieste por los relojes que se mueven lentamente, su magnitud es demasiado insustancial para ser medida, por lo que los relojes que se mueven lentamente parecen funcionar al mismo ritmo que los relojes estacionarios. Ahora, ambas predicciones, la dilatación del tiempo aparente en relojes rápidos, pero no en movimiento lento, han sido verificadas; sin embargo, solo la primera se toma para proporcionarnos una sorprendente confirmación de la teoría. ¿Por qué es esto? ¿Qué es lo que hace esto sorprendente? ¿Y por qué las predicciones sorprendentes y precisas tienen un valor probatorio especial?
5) Paradoja de confirmación. Creemos que por hipótesis “todos los cuervos son negros" está significativamente confirmada por la observación de que ciertos cuervos son negros; y no significativamente confirmada por la observación de que ciertas cosas que no son negras tampoco son cuervos. Pero es particularmente difícil llegar a cualquier razón para esta intuición; y para otras como ellas. El problema general aquí es conocido como “la paradoja de la confirmación”. Es natural suponer que cualquier hipótesis científica de la forma “todos como B son” estaría respaldada por evidencia de la forma “k es una A y k es una B”. Este bien podría ser el tipo de principio que podríamos proporcionar como ejemplo de un canon general de metodología científica. Además, parece claro que si algún dato apoya, o confirma, o es evidencia a favor de una hipótesis científica, entonces confirma toda formulación lógicamente equivalente de esa hipótesis. El problema o paradoja, es que estos dos principios muy plausibles conducen a una conclusión extremadamente contra-intuitiva. Porque el primer principio nos dice que la observación de un no negro (digamos una pañuelo blanco) debe ser evidencia a favor de la hipótesis “todas las cosas no negras no molestan”. Por lo tanto, por el segundo principio, nos lleva la extraña conclusión de que la hipótesis “todos los cuervos son negros” se confirma mediante la observación de un pañuelo blanco. Esto puede ser bienvenido en un día lluvioso, pero apenas cuadra con nuestra intuición sobre la metodología científica. Trataremos de explicar y justificar nuestras intuiciones, y mostrar lo que está mal con esos principios que suenan plausibles y que parecen ser incompatibles con ellos mismos.
La teoría ortodoxa y más ampliamente mantenida, de la metodología científica es el modelo hipotético deductivo de Hempel. Se llama así porque supone que el método de investigación científica implica las etapas: identificación del problema; formulación de la nueva hipótesis; deducción de implicación; Implicaciones verificadas por observación y, confirmación (se acepta) o no conformación (se rechaza).
 13.33.22.png)
Figura 4.1 Ejemplo del modelo hipotético deductivo de Hempel.
Este modelo guarda silencio sobre asuntos importantes, no tiene en cuenta las evidencias y la adopción de hipótesis estadísticas, no implica predicciones observables. No proporciona ninguna medida del grado de confirmación conferido por una predicción exitosa, es decir, ningún relato de los valores probatorios relativos de diferentes piezas de evidencia. Y no da ninguna indicación de cuándo una hipótesis ha sido suficientemente confirmada para justificar cualquier confianza en ella. Por lo tanto, el modelo hipotético deductivo, tal como está, no tiene en cuenta ninguno de esos elementos de metodología científica que queremos entender. Vamos a necesitar una teoría que se muestre en grados de confirmación.
Hasta ahora, no hemos dicho nada particularmente controvertido. Simplemente hemos expuesto en cierta perspectiva algunos problemas estándar del pensamiento científico. Pero el enfoque que pretendemos adoptar para tratar de resolver estos problemas es controvertido. Es conocido como bayesiano en honor al matemático inglés del siglo XVIII, Thomas Bayes. Y, en términos generales, se deriva de la opinión de que el concepto de probabilidad subjetiva es de valor fundamental para llegar a una comprensión de la metodología científica. Más específicamente, el enfoque bayesiano se basa en el principio fundamental:
B. Los grados de creencia de una persona idealmente racional se ajustan a los principios matemáticos de la teoría de la probabilidad.
Por ejemplo, un principio de la teoría de la probabilidad es:
P(H)+P(-H)=1
Así se deduce de B que nuestro grado de creencia, de que hay vida en la Luna más nuestro grado de creencia de que no hay vida en la Luna, si somos racionales, la suma es igual a uno. Si B es correcto, entonces el cálculo de probabilidad restringe combinaciones racionales de grados de creencias de la misma manera que los principios de la lógica deductiva restringen las combinaciones racionales de plena creencia. La idea bayesiana es que nuestros rompecabezas metodológicos provienen de una fijación sobre las creencias de todo o nada, y puede ser resuelta por medio de la “lógica” probabilística de la creencia parcial.
Ahora, combinando nuestro objetivo general (lograr una clarificación, sistematización y justificación de la metodología científica) con el enfoque bayesiano, vemos que hay tres cosas que hacer: 1) necesitamos explicaciones en términos probabilísticos las nociones tales como: 1)“confirmación”, “evidencia”, “simplicidad”; 2) debemos examinar en qué medida pueden derivarse los distintos cánones de la metodología científica B y en qué medida se requieren otros principios; 3) debemos evaluar la verosimilitud de B. ¿Podemos justificarlo y hacer más suposiciones que puedan ser necesarias?
Axioma de la teoría de la probabilidad Bayes. El teorema de Bayes parte de una situación en la que es posible conocer las probabilidades de que ocurran una serie de sucesos A y B.
P(A&B)=P(B)P(A/B)
 21.03.38.png)
Figura 4.2 Ejemplo de la probabilidad por el teorema de Bayes.
“Esta fórmula nos permite calcular la probabilidad condicional P(Ai|B) de cualquiera de los eventos Ai dado B. No tiene por qué haber una relación causal o temporal entre A y B. A puede preceder en el tiempo a B, sucederlo o pueden ocurrir simultáneamente. A puede causar B, viceversa o pueden no tener relación causal. Las relaciones causales o temporales son nociones que no pertenecen al ámbito de la probabilidad. Pueden desempeñar un papel o no, dependiendo de la interpretación que se le dé a los eventos[1]”.
![]()
![]()
Si ahora, supongamos que H significa alguna hipótesis y E para alguna afirmación de evidencia, y que H predice E.
Por lo tanto P(H&E)=P(H/E)P(E)
y P(E&H)=P(E/H)P(H)
Pero P(H&E)=P(E&H)
Por lo tanto P(H/E)=[P(H)P(E/H)]/[P(E)] Teorema de Bayes
 20.49.57.png)
Ahora, supongamos que podemos establecer B. Entonces podríamos inferir que los grados de creencia b(…) de una persona racional deben satisfacer la ecuación:
B(H/E)=[b(H)b(E/H)]/[b(E)]
Hemos supuesto que H significa alguna hipótesis y E para alguna afirmación de evidencia, y que H predice E. Considere una persona racional para quien la verdad de E y de H son inciertas, es decir:
0<b(H)<1
0<b(E)<1
Tenemos:
B(E/H)=1
Ya que es un axioma de probabilidad de que si A implica B, entonces P(B/A) es 1. b(E/H)>b(E) Por lo tanto, empleando el teorema de Bayes, encontramos:
b(H/E)>b(H)
En otras palabras, la racionalidad requiere que el grado condicional de creencia en H, dado E, sea mayor que el grado de creencia en H. Considere ahora una explicación probabilística no totalmente antinatural de lo que es para una declaración evidencia a favor de otra, a saber, el descubrimiento de E sería evidencia a favor de H si la racionalidad requiere que b(H/E)>b(H). Habida cuenta de esta aclaración de la noción de prueba; de ello se deduce que el descubrimiento de E tendería a confirmar H; por lo tanto, hemos proporcionado una justificación para el valor probatorio intuitivo de la predicción precisa.
Del mismo modo, podemos ver por qué, en esas circunstancias, el descubrimiento de -E debe desconfiar H. Porque es un teorema del cálculo de probabilidad que
P(A/B)+P(-A/B)=1
Por lo tanto, las creencias de un persona racional deben satisfacer:
B(E/H)+b(-E/H)=1
Por lo tanto, en las circunstancias dadas:
b(-E/H)=0
Por lo tanto b(H/-E)=[b(H)b(-E/H)]/[b(-E]=0
Podemos dar cuenta del segundo punto de metodología científica discutido anteriormente: que las predicciones relativamente sorprendentes tienen un mayor valor probatorio. Porque es natural tomar b(E) como medida inversa de la sorpresa de E (es decir, S(E)=1/b(E). Ahora supongamos que H implica E1 y E2 . Tenemos para una persona racional:
 13.38.55.png)
Por lo tanto, cuando más sorprendente sea la predicción E por H, mayor será el valor de b(H/E) y b(H).
Ahora pasaremos a una discusión general sobre la probabilidad. El objetivo es aclarar la noción de grado de creencia, o lo que generalmente de llama “probabilidad subjetiva” y distinguir esta de otros conceptos de probabilidad.
La tesis fundamental bayesiana B: los grados racionales de creencias se ajustan a los axiomas de la probabilidad.
4.2 Teoría primitiva
Según lo que se llama Teoría primitiva, la probabilidad de que un ensayo o experimento tenga un determinado resultado igual a la proporción de posibles resultados del ensayo que generan ese resultado. Hay seis resultados posibles al lanzar un dado, y tres de estos producen un número par; por lo que la probabilidad de ese resultado es 1/2.
Hay una falla importante con esta definición, es que implica atribuciones incorrectas de probabilidad. Las posibilidades de que un dado sesgado muestre un número par pueden no ser 1/2. Para evitar esta objeción, una estrategia natural es exigir que los posibles resultados del ensayo sean igualmente probables. La probabilidad, según una cuenta modificada de este tipo, sería la proporción de resultados igualmente probables que generan el resultado. Sin embargo, esto salva la definición de consecuencias incorrectas solo en el pesar de la circunstancia. La cuenta es ahora inadecuada como una definición de probabilidad, ya que depende de la noción de resultado igualmente probable. Para explicar la definición en el cálculo de alguna probabilidad, ya debemos comprender lo que es que los resultados alternativos del ensayo tengan la misma probabilidad.
Una respuesta natural a la parte defectuosa del subjetivismo —su inverosímil interpretación de las afirmaciones de probabilidad— es la adopción de una interpretación racionalista. En este punto de vista, una atribución de probabilidad a una declaración no describe el grado personal de creencia del hablante en la declaración, pero hace una afirmación objetiva en el sentido de que es razonable creer, en el grado especificado, que la declaración es verdadera. Esto explica la existencia de un verdadero desacuerdo de las afirmaciones de probabilidades a la luz de las normas reconocidas. Sin embargo, queda por ver qué hace que un determinado grado de creencia sea racional o irracional, necesitamos formular principios que nos permitan determinar qué grado de creencia es racional.
Es útil distinguir dos formas de racionalismo. Podemos llamarlas débiles o fuertes en su racionalismo. En primer lugar, la única condición que debe cumplirse para que una combinación de grados de creencia sea racional es que sean coherentes, es decir, se ajusten al cálculo de probabilidades. Por lo tanto, según un racionalista débil, la probabilidad de p es x, significa, dada la evidencia disponible, el grado de creencia de cualquier persona se ajustará al cálculo de probabilidad solo si su grado de creencia en p es x.
Un racionalista fuerte sostiene, por otra parte, que la racionalidad limita las combinaciones legítimas de grado de creencia que una persona puede tener, pero no solo por el requisito de que se ajusten al cálculo de probabilidad. Según un fuerte racionalismo, la racionalidad no solo requiere coherencia, sino que también se rige por otros principios que regulan la creencia parcial en las hipótesis, dada la situación probatoria. Por lo tanto, dada una situación probatoria en la que todo lo que se conoce es:
(a) La proporción de F’s que son G es x
(b) k es un F
Se podría afirmar que la racionalidad requiere un grado de creencia igual a x en la declaración de que k es G. Esta opinión puede expresarse como la afirmación:
Prob (k es G/k es F y la proporción de Fs que son G es x)=x
Por lo tanto, el programa de investigación de un racionalista fuerte incluirá un intento de formular principios como este, o, más ambiciosamente, para proporcionar una manera de determinar, para cualquier declaración, p y q, el grado en que es racional creer p en una situación probatoria en la que todo lo que se conoce es la verdad de q.
A primera vista parece que la versión fuerte del racionalismo es más plausible que la versión débil. Porque parece que la coherencia, aunque una condición necesaria para la racionalidad, difícilmente sería suficiente. Por ejemplo, supongamos que nos enfrentamos a una urna que conocemos contiene 1 bola roja y 99 bolas blancas. Estamos planeando llegar y seleccionar una de las bolas. ¿Qué grado de creencia debemos tener si vamos a elegir la bola roja? La respuesta correcta parecería ser alrededor de 1/100. Sin embargo, no parecería determinar ese resultado de manera coherente. Podría insistir en que la probabilidad de obtener la bola roja es 3/4 y mantener la coherencia siempre que nuestros otros grados de creencia se ajusten en consecuencia. Así que mi grado de creencia de que vamos a elegir una bola blanca tendría que ser 1/4.
O supongamos que todo lo que sabemos es que hay 100 bolas, algunas blancas y otras rojas, y que hemos elegido sacar 50 al azar y hemos encontrado 40 rojas y 10 blancas. A la luz de esa evidencia parece claro que deberíamos tener un grado de creencia mayor que 1/2 por la mayoría de las bolas rojas. Pero una vez más, la mera coherencia no parece recitar esta conclusión.
Si embargo, estas consideraciones no son concluyentes. El racionalista débil tiene una respuesta ingenua en la manga, aunque no es, en el análisis final, bastante adecuada. Su respuesta se basa en un fenómeno llamado “el pantano de los antecedentes”, una abrumadora, por las ideas preconcebidas por nuevos datos, y pretende mostrar que la restricción de coherencia es más poderosa de lo que uno podría suponer en primer lugar.
Consideremos dos hipótesis H1 y H2. Tenemos el teorema de Bayes:
 15.49.26.png)
Ahora, supongamos que dos personas difieren en los grados de creencia que asignan a H1 y H2. Sin embargo, pueden estar bastante de acuerdo sobre su relativa verosimilitud, dadas las pruebas E, y que pueden ser:
a) que están de acuerdo sobre P(E/H1) y P(E/H2) y
b) que P(E/H1)/P(E/H2) es muy grande o muy pequeño en comparación con cualquiera de sus estimaciones de P(H1)/P(H2)
En consecuencia, sus puntos de vista previos sobre la verosimilitud de H1 y H2están inundados por el valor extremo de P(E/H1)/P(E/H2), pueden llegar a estar de acuerdo sobre qué hipótesis es más probable a la luz de E, aunque no estuvieran de acuerdo inicialmente.
![]()
Por lo tanto, la probabilidad relativa posterior de y
![]() es igual que su probabilidad
es igual que su probabilidad
Por lo tanto, la probabilidad relativa posterior de ![]() y
y ![]() es igual que su probabilidad relativa previa. La evidencia E no hace nada para ayudarnos a elegir entre ellas. Además, es fácil extrapolar este resultado y ver que, en general, el fenómeno de antecedentes no explicará nuestras intuiciones de racionalidad, es decir, sobre nuestros juicios sobre qué teoría debe preferirse. En esa clase generalizada de casos que implican la elección entre hipótesis incompatibles y empíricamente adecuadas. Ciertamente, la responsabilidad de la demostración es con el racionalista débil para explicar cómo, por mera coherencia, estas diversas intuiciones pueden ser extraídas.
es igual que su probabilidad relativa previa. La evidencia E no hace nada para ayudarnos a elegir entre ellas. Además, es fácil extrapolar este resultado y ver que, en general, el fenómeno de antecedentes no explicará nuestras intuiciones de racionalidad, es decir, sobre nuestros juicios sobre qué teoría debe preferirse. En esa clase generalizada de casos que implican la elección entre hipótesis incompatibles y empíricamente adecuadas. Ciertamente, la responsabilidad de la demostración es con el racionalista débil para explicar cómo, por mera coherencia, estas diversas intuiciones pueden ser extraídas.
Cualquiera que se la versión del racionalismo se adopta, el significado de una reclamación de probabilidad se toma para ser:
Uno debe creer p a grado x.
Ahora, es evidente que los grados de creencia que sería racional tener en una declaración como "Hay vida en Marte", depende de la evidencia disponible. La probabilidad de vida en Marte es baja, puede ser cierta en relación con ciertas condiciones probatorias y falsas en relación con otras. Por consiguiente, en las alegaciones de probabilidad categóricas subyacentes, hay notificaciones de probabilidad condicional del formulario:
En condiciones probatorias E, la probabilidad de p es x.
o, en otras palabras:
En las condiciones probatorias E, uno debe creer p a grado x.
4.2.1 La lógica de interpretación
Ahora es un paso corto a la interpretación lógica de probabilidad de Carnap (1950). Supongamos que las circunstancias probatorias pueden estar representadas por el conocimiento de una sola proposición E (la conjunción de hechos observados). A continuación, una reivindicación de probabilidad condicional racionalista tiene forma
![]()
Ahora comparemos esto con la declaración del formulario
![]()
Esto implica una restricción a cualquier sistema racional de creencias, a saber, que sería irracional creer que E es verdadera y p es falsa. Sin embargo, no consideramos que ![]() significa: sería irracional creer que E es verdadera y p es falsa. Más bien, interpretamos que
significa: sería irracional creer que E es verdadera y p es falsa. Más bien, interpretamos que ![]() expresa una relación lógica de implicación causal entre E y p, afirmando la imposibilidad de que E sea verdad sin que p sea verdad también. Del mismo modo, debemos reconocer la existencia de declaraciones de probabilidad de al forma: E confirma p a grado x,
expresa una relación lógica de implicación causal entre E y p, afirmando la imposibilidad de que E sea verdad sin que p sea verdad también. Del mismo modo, debemos reconocer la existencia de declaraciones de probabilidad de al forma: E confirma p a grado x, ![]() , expresando una relación objetiva de probabilidad de verificación o implicación parcial entre p y E, lo que implica, que no afirman directamente, que alguien cuya evidencia total es E debe creer p a grado x. A cada afirmación de probabilidad racionalista acerca de la ciencia:
, expresando una relación objetiva de probabilidad de verificación o implicación parcial entre p y E, lo que implica, que no afirman directamente, que alguien cuya evidencia total es E debe creer p a grado x. A cada afirmación de probabilidad racionalista acerca de la ciencia:
Dada la evidencia total E, uno debe creer p en grado x.
Corresponderá una relación de probabilidad lógica entre instrucciones:
E confirma p en grado x.
Carnap en su programa de lógica inductiva idea una función:
![]()
Que especificaría, para cualquier instrucción p y E, el grado en que E confirma p, en otras palabras, la probabilidad lógica de p dado E. De este modo, esta función determinará el grado en que se debe creer p, dada la evidencia total E.
Carnap ofrece una serie de razones para llamar a esta concepción la interpretación lógica de la probabilidad. Primero, la relación de probabilificación en grado x que tiene entre declaraciones y puede considerarse una versión débil de la relación lógica de la implicación. Segundo, tales declaraciones conocedoras a priori, y sus valores de verdad determinados únicamente por los significados de los términos constitutivos. Si es un hecho que: dada la evidencia total E, uno debe creer p a grado x. Entonces estaríamos obligados a reconocer este hecho si estuviéramos en el estado de pruebas totales E. Pero en ese caso deberíamos ser capaces de ver, incluso ahora, que en esas circunstancias hipotéticas lo reconoceríamos. Así que deberíamos ver ahora, independientemente de neutra evidencia actual, que el grado correctivo de creencias en p, dada la evidencia total E, es x. Por consiguiente, las declaraciones de probabilidad racional y lógica no son empíricas. Tercero, la función c se define especificando, para cualquier par de instrucciones, el valor de la función. Por lo tanto, el valor d ella verdad de ![]() es solo una cuestión de definición. Se puede descubrir simplemente consultando la definición de c y estableciendo si el triplete
es solo una cuestión de definición. Se puede descubrir simplemente consultando la definición de c y estableciendo si el triplete ![]() se ajusta a él.
se ajusta a él.
Cuarto, si E implica o no lógicamente p depende únicamente de las formas lógicas de las sentencias E y p. Del mismo modo, pensó Carnap, el grado en que E lógicamente sucedía p debería depender solo de estas características formales. Por lo tanto, esperaba idear una función de confirmación c con la siguiente propiedad: que si los dos pares de declaraciones ![]() y
y ![]() tienen la misma forma lógica, entonces:
tienen la misma forma lógica, entonces:
![]()
Por ejemplo, el valor numérico de
c(Todos los valores B/ Objetos k1,k2,…,kn, son A y B)
No dependerán de qué predicados particulares se sustituyan por A y B.
Hemos simplificado la discusión anterior sugiriendo que hay una función c única y correcta que especifica probabilidades numéricas agudas para cada declaración, dada la evidencia total. De hecho, Carnap reconoce que puede haber, dada la evidencia, una serie de grados de creencia en, digamos, la vida en Marte, que no sería irracional. Tal vez la razón solo dicta que la probabilidad es baja, y no requiere un grado específico de creencia. Si esto es así, entonces la probabilidad lógica de p, dada E, será un conjunto de numeraros I, de modo que, dada la evidencia total E, el grado de creencia en p puede ser algún número dentro de nosotros y puede que no esté fuera de nosotros. Y en ese caso el objeto principal de la investigación en la lógica inductiva se convierte en una característica de todas las c-funciones permisibles: todas las funciones de confirmación valoradas en números que producen grados permisibles de creencias.
Tanto el racionalismo como la interpretación lógica implican cierta distinción ente el estado probatorio de un sujeto y las creencias posteriores que deben justificarse sobre la base de esta información que constituye ese Estado, y corresponde aun proponente de uno de estos puntos de vista decir algo acerca de cómo se debe extraer esta distinción, cómo se debe especificar el estado probatorio del sujeto.
Una estrategia natural es invocar la diferencia entre las frases de observación y las sentencias teóricas. Se dice que el estado probatorio del sujeto consiste en aquellas creencias adquiridas no inferencialmente, directamente sobre la base de la observación experimental. Carnap supone, además, que existe una clase de función de confirmación permisible, ![]() , desde pares de declaraciones hasta números reales, cada una de las cuales especifica un grado de creencia x, que sería racional para una persona tener en H, cuyo estado probatorio consiste en la conjunción E de creencias observacionales. Por tanto, para determinar si el sistema total de creencias de un sujeto es racional, o no, identificamos primero aquellos elementos que comprenden su estado probatorio, segundo, nos unimos a las creencias en una sola declaración E; y por último, examinaremos la clase de funciones c admisibles para ver si hay una que prescribe, en relación con E, exactamente aquellos grados de creencia que están en manos del sujeto. Sí y solo si, hay uno, el sistema de creencias es racional.
, desde pares de declaraciones hasta números reales, cada una de las cuales especifica un grado de creencia x, que sería racional para una persona tener en H, cuyo estado probatorio consiste en la conjunción E de creencias observacionales. Por tanto, para determinar si el sistema total de creencias de un sujeto es racional, o no, identificamos primero aquellos elementos que comprenden su estado probatorio, segundo, nos unimos a las creencias en una sola declaración E; y por último, examinaremos la clase de funciones c admisibles para ver si hay una que prescribe, en relación con E, exactamente aquellos grados de creencia que están en manos del sujeto. Sí y solo si, hay uno, el sistema de creencias es racional.
6) El problema “grue”. Hay una nueva objeción a la idea natural, ya amenazada por la paradoja de confirmación, de que el razonamiento científico puede ser codificado por alguna norma como
Todas las muestras A s han sido B
Por lo tanto, todas A s son B
Nelson Goodman (1955) ha identificado instancias de este esquema que constituyen argumentos intuitivamente malos. Por ejemplo, defina el predicado grue de la siguiente manera[2]:
x es grue: x es muestreo y verde o no muestreo y azul.
Ahora, el argumento
Todas las esmeraldas han sido grue
Por lo tanto, todas las esmeraldas son grue.
Se ajusta a la supuesta regla de inducción. Sin embargo, este razonamiento es definitivamente equivalente a:
Todas las esmeraldas muestreadas han sido verdes
Por lo tanto, todas las esmeraldas muestreadas son verdes
y las esmeraldas sinmuestrear son azules.
Que seguramente rechazaríamos. En cambio, sería nuestra práctica inductiva inferir de la información dada que las esmeraldas sin muestreo son verdes. Por lo tanto, el esquema no es preciso en general, aunque ciertas instancias (por ejemplo, A = esmeralda, B=verde) producen razonamientos aceptables. Por lo tanto, nos quedamos con la pregunta: cómo especificar la clase de predicados (llamados predicados proyectables) cuya sustitución en el esquema inductivo producirá argumentos aceptables.
7) Simplicidad. Dadas dos teorías incompatibles que se adaptan a nuestro datos, creemos que es más probable que la más simple sea cierta. La necesidad de cierta intuición de este tipo surge en primer lugar porque siempre es posible encontrar varias teorías incompatibles, todas las cuales se ajustan a la evidencia que ya hemos acumulado. Un caso típico de este fenómeno es la posibilidad de dibujar muchas curvas a través de nuestro conjunto de puntos de datos. Así, supongamos que un científico quiere conocer la relación funcional entre dos parámetros X e Y (por ejemplo , temperatura y presión de una cantidad fija de gas, confinada a una cámara cuyo volumen es contante). Digamos que puede virara el valor X y medir el valor correspondiente de Y. Ahora, supongamos que de esta manera ha obtenido, para seis valores de X, los valores correspondientes de Y, y trazado estos puntos en papel gráfico. Los puntos resultan estar sobre una línea recta; sin embargo, muchas otras funciones son compatibles con ellas, como se muestra
 19.27.45.png)
Este fenómeno -la prevalencia de hipótesis observacionales adecuadas competidoras- da lugar a tres preguntas:
A) ¿Cómo elegimos entre las alternativas? ¿En qué se basa nuestra preferencia? ¿Simplicidad? Si es así, ¿cómo es reconocible la simplicidad? El problema grue es un elemento en este problema general de idear una descripción de nuestra práctica inductiva.
B) Cómo es que esta medida de preferencia debe cambiarse con el conocimiento de que alguna teoría se ajusta a ciertos datos, para producir una evaluación de su verosimilitud?
C) ¿Qué justifica nuestro método de evaluación teórico? Dada la respuesta a la pregunta A) -un relato de las características de una hipótesis que tomamos para recomendarla por encima de otras que se justifican igualmente a los datos— ¿qué razón tenemos para pensar que nuestro procedimiento tenderá a conducirnos hacia la verdad? En particular, ¿por qué deberíamos concluir, como haríamos las pruebas citadas anteriormente, que probablemente todas las esmeraldas son verdes? Este es el problema tradicional de la inducción.
8) Hipótesis ad hoc. Se cree que la postulación de una hipótesis ad hoc es algo de mala reputación. Cuando una teoría establecida está en peligro de falsificación por el descubrimiento de hechos que no puede explicar, sus defensores pueden parchear la teoría de tal manera que la reconcilien con los datos. A veces se dice que tal maniobra es ad hoc y los científicos tienen una visión tenue de ella. Consideremos, por ejemplo, la afirmación ad hoc de que phlogiston tiene un peso negativo. Esto se propuso únicamente para intentar salvar la combustión de metales, dado que las cenizas pesan las cenizas pesan más que el metal original.
9) Evidencia diversa. Creemos que las teorías están mejor confirmadas por un amplio espectro de diferentes tipos de evidencia por un estrecho conjunto repetido de datos. Por lo tanto, intuitivamente, E2 es mejor evidencia para H que E1. Pero se proporciona evidencia más sólida si digamos aumentamos a 100 experimentos, implica no solo una variación. Una vez más lo que deseamos es una caracterización precisa de la amplitud y un explicación de su valor probatorios.
4.3 La domesticación del azar
Por inverosímil que sea, nadie había ensayado hasta entonces una teoría general de los juegos. El babilonio no es especulativo. Acata los dictámenes del azar, les entregan su vida, su esperanza, su terror pánico, pero no se le ocurre investigar sus leyes laberínticas, no las esferas giratorias que lo revelan. Sin embargo, la declaración oficiosa que he mencionado inspiró muchas discusiones de carácter jurídico-matemático. De alguna de ellas nació la conjetura siguiente: si la lotería es una intensificación del azar, una periódica infusión del caos en el cosmos, ¿no convendría que el azar interviniera en todas las etapas del sorteo y en una sola? ¿No es irrisorio que el azar dicte la muerte de alguien y que las circunstancias de esa muerte —la reserva, la publicidad, el plazo de una hora o de un siglo— no estén sujetas al azar[3]?
De “La lotería en Babilonia” de Jorge Luis Borges
4.3.1 De lo impredecible a las leyes
En los oscuros recovecos de la historia antigua, la idea del azar se entrelazó con la del destino. Lo que estaba destinado a ser, lo sería. El azar estaba personificado, al menos en el Imperio Romano, por la Diosa Fortuna, que reinaba como soberana del cinismo y la inconstancia. Como dice Howard Patch en su estudio de esta deidad romana, “a los hombres que sintieron que la vida no muestra signos de justicia, y que lo que hay más allá es, en el mejor de los casos, es dudoso, que lo máximo que pueden hacer es tomar lo que se les presente, Fortuna representa un resumen útil, aunque a veces frívolo, de cómo van las cosas[4]".
Para subvertir la obstinación de Fortuna, quizás uno podría adivinar sus intenciones intentando simular su propio modo de comportamiento. Esto podría lograrse participando en un juego de azar con la esperanza de que sus resultados revelen qué elección tomaría la propia Fortuna. Existe evidencia de que la gente precristiana a lo largo de la costa mediterránea arrojó huesos de talón de animales, llamados tali, y que esto finalmente evolucionó para jugar con dados. Cuando un resultado fortuito de muchos resultados posibles había sido revelado por el sorteo, uno podía intentar interpretar sus presagios y decidir qué acción tomar a continuación. Julio César, por ejemplo, resolvió su angustiosa decisión de cruzar el Rubicón y avanzar sobre Roma al supuestamente arrojar dados y exclamar "iacta alea est", la suerte está echada. Esto se repite en nuestro propio tiempo cuando la gente hace un sorteo para decidir quién es el primero o, para el caso, quién será el último. La esencia misma del juego limpio es lanzar una moneda para que el azar pueda decidir el próximo movimiento.
La interpretación de los presagios fue un intento de descifrar el parloteo de signos aparentemente incoherentes codificándolos en una profecía compacta y coherente o, quizás, como un conjunto de instrucciones para guiar al suplicante. Visto de esta manera, la adivinación es un precursor del uso de la codificación en la teoría de la información y la compresión de mensajes en la teoría de la complejidad algorítmica, temas que ocuparán un lugar destacado en partes posteriores de este libro.
Fortuna no era todo un presentimiento. Existe evidencia de que los elementos del azar se emplearon no solo para augurios y adivinación, sino, en un aspecto más lúdico, para divertirse. Los juegos de azar y apuestas fueron firmemente establecidos por el Renacimiento, y varias personas habían comenzado a notar que cuando se lanzaban repetidamente dados de forma regular y equilibrada, ciertos resultados, como cinco puntos en una de las seis caras, parecían ocurrir en la promedio alrededor de una sexta parte del tiempo. Nadie fue más persuasivo sobre esto que la figura del siglo XVI de Girolamo Cardano, un célebre médico y matemático italiano, que escribió un pequeño tratado sobre el juego, Liber de Ludo Aleae, en el que demostró su conocimiento de cómo calcular las probabilidades de ganar en varios juegos.
Esta comprensión recién descubierta sobre el funcionamiento del azar en juegos simples pronto evolucionaría hacia una comprensión más amplia de los patrones revelados por el azar cuando se hacen muchas observaciones. En retrospectiva, parece inevitable que el estudio de la aleatoriedad se convierta en una ciencia cuantitativa, paralela a la forma en que evolucionaron las ciencias físicas durante el Renacimiento tardío. Durante los dos siglos siguientes, varias personas, como los matemáticos Blaise Pascal y Pierre de Fermat, participaron en el control del espíritu arbitrario de la fortuna, al menos en los juegos de dados y cartas, pero no fue hasta el A principios del siglo XVIII, después de que se inventó el cálculo y las matemáticas en general habían alcanzado un nivel de madurez impensable unos siglos antes, los eventos probables e improbables podían expresarse adecuadamente en una forma matemática. Fue en este momento que se forjaron las herramientas que llevaron a la teoría moderna de la probabilidad. Al mismo tiempo, el estudio de las estadísticas tal como las conocemos ahora comenzó a surgir de los esfuerzos de recopilación de datos dirigidos a proporcionar tablas de mortalidad y anualidades de seguros, los cuales dependen de eventos fortuitos.
El matemático suizo Jakob Bernoulli, en su "Ars Conjectandi[5]" de 1713 y, poco después en 1718, Abraham de Moivre, en "The Doctrine of Chances[6]", despojó el elemento de la aleatoriedad a lo esencial al considerar solo dos resultados posibles, como bolas blancas y negras seleccionadas a ciegas de una urna, o lanzamientos de una moneda imparcial.
Imagina que alguien lanza una moneda equilibrada un total de n veces, para un número entero n. La proporción de caras en estos n lanzamientos, es decir, el número real de caras producidas, dividido por n, es una cantidad que generalmente se conoce como el promedio de la muestra, ya que depende de la muestra particular de una secuencia de lanzamientos de moneda que se obtenga. Los diferentes resultados de n lanzamientos generalmente darán como resultado diferentes promedios de la muestra.
Lo que Bernoulli mostró es que a medida que el tamaño de la muestra n aumenta, es cada vez más probable que la proporción de caras en n lanzamientos de una moneda balanceada (el promedio de la muestra) no se desvíe de la mitad en más de un margen de error fijo. Esta afirmación se reformulará más adelante en términos más precisos como la "Ley de los números grandes" de Moivre[7], puso más sustancia en la declaración de Bernoulli al establecer que si el número promedio de caras se calcula muchas veces, la mayoría de los promedios de la muestra tienen valores que se agrupan alrededor de 1/2, mientras que el resto se dispersa más escasamente cuanto más se obtiene 1/2. Además, Moivre mostró que a medida que aumenta el tamaño de la muestra, la proporción de promedios muestrales se coloca alrededor de la mitad, las distancias variables comienza a verse como una curva suave en forma de campana, conocida como curva normal o Gaussiana (después de el matemático alemán Carl-Friedrich Gauss, cuya carrera abarcó los siglos XVIII y XIX). Este fenómeno se ilustra en la figura 4.3, en la que se agrupan 10,000 promedios muestrales en pequeños segmentos a lo largo del eje horizontal. La altura de los contenedores rectangulares sobre los segmentos representa el número de promedios de muestra que se encuentran dentro del intervalo indicado. Los rectángulos disminuyen de tamaño cuanto más se aleja de 1/2, lo que muestra que cada vez se encuentran menos promedios de muestra a distancias más largas del pico en 1/2. El perfil general de los rectángulos, es decir, la distribución de los promedios muestrales, tiene forma de campana y, a medida que n aumenta, este perfil comienza a aproximarse cada vez más a la curva suave (gaussiana) que se ve superpuesta en los rectángulos de la figura 4.3.
 19.20.46.png)
Fig. 4.3 La distribución de 10,000 promedios de muestra a diferentes distancias de ½. La curva suave en forma de campana es una presencia omnipresente en las estadísticas y se conoce como la curva normal o, a veces, la curva gaussiana.
Aunque las demostraciones formales del teorema de De Moivre y de la ley de Bernoulli están más allá del alcance del presente trabajo, los resultados mismos se utilizarán más adelante. En conjunto, las afirmaciones de Bernoulli y de Moivre describen una especie de orden latente que emerge de una masa de datos desordenados, una regularidad que se manifiesta en medio del caos de una gran muestra de números. En los primeros años del siglo XIX, el uso de los nuevos métodos para manejar grandes cantidades de datos se empleó con entusiasmo para aprovechar la incertidumbre en todas las esferas de la vida, más allá de los ejemplos bastante benignos de los juegos, y nunca más que por las burocracias gubernamentales entusiastas empeñadas en lidiar con los torrentes de datos que se recopilan sobre las poblaciones dentro de sus fronteras. La locura, el crimen y otras formas de comportamiento aberrante se habían catalogado abundantemente en el siglo XVIII y principios del XIX, y por fin se disponía de una forma de extraer las implicaciones sociales de estos números. Ahora se podría definir el comportamiento "normal" como estar dentro de una cierta fracción del promedio de una muestra grande de personas, con desviaciones que se encuentran fuera de este rango, de la misma manera que se habla del promedio de muchos lanzamientos de monedas.
Lo que antes era desconcertante e impredecible ahora parecía encajar en patrones dictados por la curva normal. Esta curva fue considerada empíricamente por ciencias como la astronomía como una “ley de errores”, pero algunos científicos como el astrónomo francés Adolphe Quetelet en particular, la convirtieron en un bastión de la teoría social. Hacia 1835 Quetelet llegó a enmarcar el concepto de “hombre promedio” que aún hoy nos acompaña. El período de clasificación e interpretación de datos, la esencia misma de la estadística, había comenzado en serio, y no es exagerado decir que la domesticación del azar había llegado a la mayoría de edad. A lo largo del siglo XIX y principios del XX, las aplicaciones de las ideas matemáticas al estudio de la incertidumbre se generalizaron y, en particular, jugaron un papel importante en la física con el estudio de la mecánica estadística, donde grandes conjuntos de moléculas chocan entre sí y se dispersan al azar.
Los métodos matemáticos para el estudio de los fenómenos aleatorios se volvieron más sofisticados a lo largo de la primera parte del siglo XX, pero al matemático ruso Andrei Kolmogorov le correspondía formalizar el pensamiento entonces actual sobre la probabilidad en una breve pero influyente monografía que se publicó en 1933[8]. Estableció un conjunto de hipótesis sobre eventos aleatorios que, cuando se usan adecuadamente, podrían explicar cómo se comporta el azar cuando uno se enfrenta a una gran cantidad de observaciones similares de algún fenómeno. Desde entonces, la probabilidad ha proporcionado los fundamentos teóricos de las estadísticas en las que se extraen inferencias a partir de datos numéricos mediante la cuantificación de las incertidumbres inherentes al uso de una muestra finita para sacar conclusiones sobre un conjunto de posibilidades muy grande o incluso ilimitado.
Veremos en lo particular de inferencia estadística un poco más adelante cuando intentemos decidir si una determinada cadena de dígitos es aleatoria. La fascinación de la aleatoriedad es que es omnipresente, proporcionando las coincidencias sorprendentes, la suerte extraña y los giros inesperados que colorean nuestra percepción de los eventos cotidianos. Aunque el azar puede contribuir a nuestra sensación de malestar por el futuro, también es, como sostenemos es un baluarte contra la asombrosa simetría (igualdad determinista), que da a la vida su sentido de inefable misterio. Por eso preguntamos urgentemente "¿qué es el azar"? La modesta cantidad de matemáticas empleadas aquí nos permite ir más allá de los significados meramente anecdóticos de la aleatoriedad, cuantificar lo que de otro modo seguiría siendo difícil de alcanzar y nos acerca a saber qué es lo aleatorio.
4.3.2 Probabilidad
El tema de la probabilidad comienza asumiendo que algún mecanismo de incertidumbre está funcionando dando lugar a lo que se llama aleatoriedad, pero no es necesario distinguir entre el azar que ocurre debido a algún orden oculto que puede existir y el azar que es el resultado de anarquía ciega. Este mecanismo, en sentido figurado, produce una sucesión de eventos, cada uno individualmente impredecible, o conspira para producir un resultado imprevisible cada vez que se muestrea un gran conjunto de posibilidades. Un requisito de la teoría de la probabilidad es que podamos describir los resultados mediante números. La totalidad de muertes por caída de un corto circuito, el número ganador en una lotería, el precio de una acción, e incluso situaciones de sí y no, como "llueve o no llueve hoy" (que es cuantificable por un cero "no" o un uno para "sí"), son todos ejemplos de esto.
La colección de eventos cuyos resultados son dictados por el azar se llama espacio muestral y puede incluir algo tan simple como dos elementos, cara o cruz en el lanzamiento de una moneda, o puede ser algo más complicado, como los ocho tripletes de cara y cruz en tres lanzamientos, o el precio de cien acciones diferentes al final de cada mes. La palabra "resultado" es intercambiable con observación, ocurrencia, experimento o ensayo, y en todos los casos se asume que el experimento, la observación o lo que sea puede repetirse en condiciones esencialmente idénticas tantas veces como se desee, aunque el resultado sea cada vez impredecible. Con los juegos, por ejemplo, se supone que las cartas se barajan minuciosamente o que las bolas mezcladas en una urna y son seleccionadas por el equivalente de una anfitriona con los ojos vendados. En otras situaciones en las que el mecanismo de selección no está bajo nuestro control, se supone que la naturaleza elige arbitrariamente uno de los posibles resultados. No importa si pensamos en la sucesión de resultados como un solo experimento repetido muchas veces o como una gran muestra de muchos experimentos llevados a cabo simultáneamente. Un solo dado lanzado tres veces es lo mismo que tres dados lanzados una vez cada uno. Cada resultado posible en un espacio muestral finito se denomina evento elemental y se le asigna un número en el rango de cero a uno. Este número, la probabilidad del evento, designa la probabilidad de que el evento tenga lugar. Cero significa que no puede suceder, y el número uno está reservado para algo que seguramente ocurrirá. Los casos interesantes se encuentran en el medio.
Imagine que se realiza una gran cantidad de observaciones, posiblemente ilimitadas, y que de vez en cuando ocurre un evento en particular inesperadamente. La probabilidad de este evento es un número entre cero y uno que expresa la relación entre el número real de ocurrencias del evento y el número total de observaciones. Al lanzar una moneda, por ejemplo, a cada cara y cruz se les asigna una probabilidad de 1/2 siempre que la moneda parece estar equilibrada. Esto se debe a que se espera que el evento de una cara o cruz sea igualmente probable en cada lanzamiento y, por lo tanto, el número promedio de caras (o cruces) en un gran número de lanzamientos debería ser cercano a 1/2. Los eventos más generales en un espacio muestral se obtienen considerando la unión de varios eventos elementales. Un evento E (a veces se usan otras letras, como A o B) tiene una probabilidad asignada tal como se hizo con los eventos elementales. Por ejemplo, el número de puntos en un solo lanzamiento de un dado balanceado conduce a seis eventos elementales, a saber, el número de puntos, de uno a seis, en la cara invertida. El evento E podría ser "la cara hacia arriba muestra un número mayor que cuatro", que es la unión de los eventos elementales "5 puntos" y "6 puntos" y, en este caso, la probabilidad de "5 o 6 puntos". es 2/6 o 1/3.
Se dice que dos eventos que representan subconjuntos disjuntos de un espacio muestral, subconjuntos que no tienen un punto en común, se excluyen mutuamente. Si A y B representan eventos mutuamente excluyentes, el evento "ya sea A o B", generalmente denotado por la abreviatura A ∪ B, tiene una probabilidad igual a la suma de las probabilidades individuales de A y B. Las probabilidades individuales de la La unión de cualquier número de subconjuntos mutuamente excluyentes del espacio muestral (es decir, un grupo de eventos que representan conjuntos de posibilidades que no tienen nada en común) debe sumar la unidad ya que es seguro que uno de ellos ocurra. Si la ocurrencia o no ocurrencia de un evento en particular es impredecible, totalmente indiferente a si sucedió antes, decimos que los resultados son estadísticamente independientes o, simplemente, independientes. Para una moneda sesgada en la que una cara tiene solo 1/3 de probabilidad de que ocurra, la frecuencia a largo plazo de caras en una secuencia de muchos lanzamientos de esta moneda realizados en circunstancias casi idénticas debería parecer estabilizarse en el valor 1/3.
Aunque esta probabilidad refleja la incertidumbre asociada con la obtención de una cara o cruz para una moneda sesgada, le doy un significado particular en este libro a las monedas no sesgadas o, de manera más general, a la situación en la que todos los eventos elementales son igualmente probables. Cuando no hay mayor propensión a que ocurra una ocurrencia sobre otra, se dice que los resultados están distribuidos uniformemente y, en este caso, las probabilidades de los N eventos elementales separados que constituyen algún espacio muestral son cada una igual al mismo valor. 1 / N. Por ejemplo, las seis caras de un dado balanceado tienen la misma probabilidad de ocurrir en un sorteo, por lo que la probabilidad de cada cara es 1/6. El proceso aleatorio por excelencia se considerará, al menos por ahora, como una sucesión de resultados independientes y distribuidos uniformemente.
Al pensar en los procesos aleatorios, a menudo se simplifican las cosas si consideramos que los resultados sucesivos tienen solo dos valores, cero o uno. Esto podría representar cualquier proceso binario, como lanzar una moneda al aire o, en circunstancias más generales, la ocurrencia o no ocurrencia de algún evento (éxito o fracaso, sí o no, encendido o apagado). Los números enteros ordinarios siempre se pueden expresar en forma binaria, es decir, una cadena de ceros y unos. Basta escribir cada número como una suma de potencias de 2. Por ejemplo, el número 9 se identifica con los dígitos binarios multiplicando las potencias individuales de 2, es decir, 1001. De manera similar,
 19.52.26.png)
 19.52.30.png)
por lo que 30 se identifica con 11110.
Los ejemplos de hecho, en la mayor parte están enmarcados en términos de dígitos binarios. Por lo tanto, cualquier resultado, como el precio de una acción volátil o el número de personas infectadas con una enfermedad contagiosa, puede codificarse como una cadena de ceros y unos llamados cadenas binarias o, como a veces se las conoce, secuencias binarias. Las computadoras, dicho sea de paso, expresan números en forma binaria, ya que los circuitos impresos en los chips responden a voltajes bajos / altos, y el conocido código Morse, durante mucho tiempo el elemento básico de la comunicación telegráfica, opera con un sistema binario de puntos y guiones.
4.3.3 Orden en grande
Ya se ha mencionado que uno espera que la proporción de caras en n lanzamientos de una moneda balanceada sea cercana a 1/2, lo que lleva a inferir que la probabilidad de una cara (o cruz) es precisamente 1/2. Lo que hizo Jakob Bernoulli fue convertir esta afirmación en un teorema matemático formal mediante la hipótesis de una secuencia de observaciones independientes o, como a menudo se les llama, ensayos independientes, de un proceso aleatorio con dos resultados posibles que se etiquetan como cero o uno, cada uno de ellos mutuamente exclusivo del otro. En lugar de estar restringido a solo monedas balanceadas, asumió más generalmente una probabilidad, designada por p, para el evento "1 ocurrirá" y una probabilidad correspondiente 1 - p para el evento "cero no ocurrirá". Dado que uno de los dos eventos debe tener lugar en cada ensayo, sus probabilidades p y 1 - p suman la unidad. Para p = 1/3, digamos, significaría que la moneda está desequilibrada y sesgada hacia la salida de cruces. Estos supuestos idealizan lo que realmente se observaría al ver un proceso binario en el que solo hay dos resultados. La secuencia de resultados, potencialmente ilimitada en número, se denominará ensayos p de Bernoulli o, de manera equivalente, proceso p de Bernoulli. En lugar de uno y cero, los resultados binarios también podrían considerarse como éxito y fracaso, verdadero y falso, sí y no, o alguna dicotomía similar. En las estadísticas médicas, por ejemplo, uno podría preguntarse si un tratamiento farmacológico en particular es efectivo o no cuando se prueba en un grupo de voluntarios seleccionados sin sesgos de la población en general. Para una secuencia de ensayos p de Bernoulli, intuitivamente se espera que la proporción de unos en n ensayos independientes se acerque a p a medida que n aumenta. Para convertir esta intuición en un enunciado más preciso, denote con ![]() el número de unos en n intentos. Entonces Sn dividido por n, es decir,
el número de unos en n intentos. Entonces Sn dividido por n, es decir, ![]() , representa la fracción de unos en n ensayos; es habitual llamar a
, representa la fracción de unos en n ensayos; es habitual llamar a ![]() el promedio de la muestra o la media de la muestra. Lo que estableció Jakob Bernoulli es que a medida que n aumenta, es cada vez más seguro que la diferencia absoluta entre
el promedio de la muestra o la media de la muestra. Lo que estableció Jakob Bernoulli es que a medida que n aumenta, es cada vez más seguro que la diferencia absoluta entre ![]() y p es menor que cualquier medida de discrepancia preasignada. Dicho de manera más formal, esto dice que la probabilidad del evento "
y p es menor que cualquier medida de discrepancia preasignada. Dicho de manera más formal, esto dice que la probabilidad del evento "![]() está dentro de una distancia fija de p" tenderá a uno cuando se permita que n aumente sin límite. El teorema de Bernoulli se conoce como Ley de los números grandes. Los ensayos de Bernoulli 1/2 son el ejemplo por excelencia de un proceso aleatorio como lo definimos anteriormente: la sucesión de ceros y unos es independiente y se distribuye uniformemente, y cada dígito tiene la misma probabilidad de ocurrir. En la figura 4.4 hay una gráfica de
está dentro de una distancia fija de p" tenderá a uno cuando se permita que n aumente sin límite. El teorema de Bernoulli se conoce como Ley de los números grandes. Los ensayos de Bernoulli 1/2 son el ejemplo por excelencia de un proceso aleatorio como lo definimos anteriormente: la sucesión de ceros y unos es independiente y se distribuye uniformemente, y cada dígito tiene la misma probabilidad de ocurrir. En la figura 4.4 hay una gráfica de ![]() versus n generada por un lanzamiento de moneda aleatorio simulado por computadora con p=1/2, y en este caso, vemos que la media de la muestra serpentea hacia 1/2 en su propia forma idiosincrásica. Este es un buen lugar para comentar sobre la frecuentemente citada "ley de los promedios", que se resume en la creencia de que después de una larga racha de mala suerte, como se ve por un bloque repetido de ceros (por ejemplo cruz, pierde), la fortuna eventualmente cambiará las cosas al favorecer las probabilidades de un uno (cara o una victoria). La percepción es que una larga serie de ceros es tan improbable que después de una sucesión tan extraña de pérdidas, la posibilidad de una cara es prácticamente inevitable, y un jugador tiene la sensación palpable de estar en la cúspide de una victoria. Sin embargo, la independencia de los lanzamientos expone esto como una ilusión: la probabilidad de otro cero sigue siendo la misma 1/2 que para todos los demás lanzamientos. Lo que es cierto es que en el conjunto de todas las cadenas binarias posibles de una longitud dada, la probabilidad de que una cadena en particular tenga un bloque de ceros increíblemente largo es bastante pequeña. Esta dicotomía entre lo que es cierto de una realización particular de un proceso aleatorio y el conjunto de todos los resultados posibles es una espina persistente en el flanco de la teoría de la probabilidad.
versus n generada por un lanzamiento de moneda aleatorio simulado por computadora con p=1/2, y en este caso, vemos que la media de la muestra serpentea hacia 1/2 en su propia forma idiosincrásica. Este es un buen lugar para comentar sobre la frecuentemente citada "ley de los promedios", que se resume en la creencia de que después de una larga racha de mala suerte, como se ve por un bloque repetido de ceros (por ejemplo cruz, pierde), la fortuna eventualmente cambiará las cosas al favorecer las probabilidades de un uno (cara o una victoria). La percepción es que una larga serie de ceros es tan improbable que después de una sucesión tan extraña de pérdidas, la posibilidad de una cara es prácticamente inevitable, y un jugador tiene la sensación palpable de estar en la cúspide de una victoria. Sin embargo, la independencia de los lanzamientos expone esto como una ilusión: la probabilidad de otro cero sigue siendo la misma 1/2 que para todos los demás lanzamientos. Lo que es cierto es que en el conjunto de todas las cadenas binarias posibles de una longitud dada, la probabilidad de que una cadena en particular tenga un bloque de ceros increíblemente largo es bastante pequeña. Esta dicotomía entre lo que es cierto de una realización particular de un proceso aleatorio y el conjunto de todos los resultados posibles es una espina persistente en el flanco de la teoría de la probabilidad.
 13.57.08.png)
Fig. 4.4. Fluctuaciones en el valor del promedio muestral Sn/n para n hasta 400. Nótese que las fluctuaciones parecen establecerse en el valor ½ a medida que n aumenta, tanto como la ley de los números grandes nos lleva a esperar.
Si, en lugar de la media muestral, uno mira simplemente la suma ![]() , sucede algo inesperado que vale la pena revelar, ya que subraya la naturaleza a menudo contradictoria de la aleatoriedad. En lugar de cero y uno, suponga que los dos resultados son más y menos uno y considere un juego de lanzamiento de moneda entre Pedro y Paul en el que Paul gana un peso, denotado por +1, si una moneda justa sale cara y pierde un dólar como era de esperar -1 en este caso, si el resultado es cruz. Todo lo contrario es cierto para su oponente Paul. Ahora
, sucede algo inesperado que vale la pena revelar, ya que subraya la naturaleza a menudo contradictoria de la aleatoriedad. En lugar de cero y uno, suponga que los dos resultados son más y menos uno y considere un juego de lanzamiento de moneda entre Pedro y Paul en el que Paul gana un peso, denotado por +1, si una moneda justa sale cara y pierde un dólar como era de esperar -1 en este caso, si el resultado es cruz. Todo lo contrario es cierto para su oponente Paul. Ahora ![]() indicará las ganancias totales de Pedro, positivas o negativas, después de n lanzamientos. Una ganancia para Pedro es, por supuesto, una pérdida para Paul.
indicará las ganancias totales de Pedro, positivas o negativas, después de n lanzamientos. Una ganancia para Pedro es, por supuesto, una pérdida para Paul. ![]() ejecuta un paseo aleatorio entre los números enteros positivos y negativos que fluctúan salvajemente en cualquier dirección volviendo en ocasiones a cero (los jugadores están igualados) antes de alejarse con excursiones positivas y negativas, algunas grandes y otras pequeñas. Nuestra intuición nos dice que uno de los jugadores estará a la cabeza aproximadamente la mitad del tiempo. ¡Pero eso es enfáticamente falso! De hecho, se puede demostrar (no es un cálculo que queramos hacer aquí) que un jugador estará a la cabeza durante la mayor parte de la duración del juego. En la Fig. 4.5 se trazan las ganancias acumuladas de 5000 lanzamientos, e ilustra dramáticamente que una ventaja o una pérdida se mantiene durante la mayor parte del juego, aunque tiende a fluctuar en valor. Lo que es cierto es que si se considera un gran número de juegos similares de longitud n, Peter estará a la cabeza en aproximadamente la mitad de estos juegos y Paul en la otra mitad. Esto se relaciona con la Ley de los números grandes si ahora volvemos a las variables cero y uno con uno que indica que Paul está a la cabeza en el enésimo lanzamiento. Al permitir que se jueguen N juegos, tenemos N ensayos de Bernoulli, uno para cada juego, con probabilidad p = 1/2. Entonces, la media muestral
ejecuta un paseo aleatorio entre los números enteros positivos y negativos que fluctúan salvajemente en cualquier dirección volviendo en ocasiones a cero (los jugadores están igualados) antes de alejarse con excursiones positivas y negativas, algunas grandes y otras pequeñas. Nuestra intuición nos dice que uno de los jugadores estará a la cabeza aproximadamente la mitad del tiempo. ¡Pero eso es enfáticamente falso! De hecho, se puede demostrar (no es un cálculo que queramos hacer aquí) que un jugador estará a la cabeza durante la mayor parte de la duración del juego. En la Fig. 4.5 se trazan las ganancias acumuladas de 5000 lanzamientos, e ilustra dramáticamente que una ventaja o una pérdida se mantiene durante la mayor parte del juego, aunque tiende a fluctuar en valor. Lo que es cierto es que si se considera un gran número de juegos similares de longitud n, Peter estará a la cabeza en aproximadamente la mitad de estos juegos y Paul en la otra mitad. Esto se relaciona con la Ley de los números grandes si ahora volvemos a las variables cero y uno con uno que indica que Paul está a la cabeza en el enésimo lanzamiento. Al permitir que se jueguen N juegos, tenemos N ensayos de Bernoulli, uno para cada juego, con probabilidad p = 1/2. Entonces, la media muestral ![]() estará cerca de 1/2 con una confianza creciente a medida que N aumente.
estará cerca de 1/2 con una confianza creciente a medida que N aumente.
 13.49.41.png)
Fig. 4.5 Fluctuaciones del total de victorias y derrotas en un juego de cara y cruz con una moneda justa en un lapso de 5000 lanzamientos, representados cada décimo valor. Una pérdida se mantiene claramente en más de 4000 lanzamientos de la moneda.
4.3.4 La ley normal
Como mencionamos anteriormente, de Moivre dio un nuevo giro a la ley de los números grandes para los ensayos p de Bernoulli. La ley de los números grandes dice que para un tamaño de muestra suficientemente grande, es probable que el promedio de la muestra esté cerca de p, pero el teorema de De Moivre, un caso especial de lo que se conoce hoy como el teorema del límite central, permite estimar la probabilidad de que un promedio de la muestra se encuentra dentro de una distancia especificada de p. Primero se debe elegir una medida de qué tan lejos está ![]() de p. Esta medida se define convencionalmente como
de p. Esta medida se define convencionalmente como ![]() , donde el símbolo σ representa
, donde el símbolo σ representa ![]() . Con p igual a 0.25, por ejemplo, σ es igual a la raíz cuadrada de 3/16.
. Con p igual a 0.25, por ejemplo, σ es igual a la raíz cuadrada de 3/16.
El teorema de de Moivre dice que la proporción (porcentaje) de promedios muestrales Sn / n que caen en el intervalo de valores entre ![]() y
y ![]() para un valor dado de c es aproximadamente igual a la fracción de área total que se encuentra debajo de la curva normal entre −c y c. La curva normal, a menudo llamada curva de Gauss, o incluso ley de errores, es la curva omnipresente en forma de campana que es familiar para todos los estudiantes de estadística y que se muestra en la figura 4.3. La esencia del teorema de De Moivre es que el error cometido al usar la curva normal para aproximar la probabilidad de que
para un valor dado de c es aproximadamente igual a la fracción de área total que se encuentra debajo de la curva normal entre −c y c. La curva normal, a menudo llamada curva de Gauss, o incluso ley de errores, es la curva omnipresente en forma de campana que es familiar para todos los estudiantes de estadística y que se muestra en la figura 4.3. La esencia del teorema de De Moivre es que el error cometido al usar la curva normal para aproximar la probabilidad de que ![]() esté dentro del intervalo dado disminuye a medida que n aumenta. Es este hecho el que pronto nos permitirá diseñar una prueba, la primera de varias, para decidir si una cadena binaria dada es aleatoria o no. El área bajo la curva normal se ha calculado para todo c, y estos números están disponibles en forma de tabla en prácticamente todos los textos y paquetes de software de estadísticas. Un valor de c que se distingue particularmente por el uso común es 1.96 que corresponde, según las tablas, a una probabilidad de 0.95. Una probabilidad de 0.95 significa que se espera que
esté dentro del intervalo dado disminuye a medida que n aumenta. Es este hecho el que pronto nos permitirá diseñar una prueba, la primera de varias, para decidir si una cadena binaria dada es aleatoria o no. El área bajo la curva normal se ha calculado para todo c, y estos números están disponibles en forma de tabla en prácticamente todos los textos y paquetes de software de estadísticas. Un valor de c que se distingue particularmente por el uso común es 1.96 que corresponde, según las tablas, a una probabilidad de 0.95. Una probabilidad de 0.95 significa que se espera que ![]() se encuentre dentro del intervalo en 19 de 20 casos o, dicho de otra manera, las probabilidades a favor de que
se encuentre dentro del intervalo en 19 de 20 casos o, dicho de otra manera, las probabilidades a favor de que ![]() caiga dentro del intervalo es de 19 a 1. En preparación para usar Los resultados anteriores para probar la aleatoriedad, intentaré enfocar el teorema de De Moivre para p = 1/2 (piense en una moneda equilibrada que no esté sesgada a favor de caer de un lado o del otro). Antes de realizar este cálculo, espero que esté de acuerdo en que es menos engorroso expresar el intervalo c mediante la abreviatura matemática:
caiga dentro del intervalo es de 19 a 1. En preparación para usar Los resultados anteriores para probar la aleatoriedad, intentaré enfocar el teorema de De Moivre para p = 1/2 (piense en una moneda equilibrada que no esté sesgada a favor de caer de un lado o del otro). Antes de realizar este cálculo, espero que esté de acuerdo en que es menos engorroso expresar el intervalo c mediante la abreviatura matemática:
![]()
Dado que la cantidad σ es la raíz cuadrada de 1/4 en el caso presente, es decir, 1/2, y dado que una probabilidad de 0.95 corresponde c = 1.96, como acaba de ver, la expresión anterior se convierte en:
![]()
y al redondear 1,96 a 2,0, esto adquiere la forma agradablemente simple:
![]()
lo que significa que se espera que aproximadamente el 95% de los promedios de la muestra adopten valores entre 0,5 más o menos![]() .
.
Por ejemplo, en 10,000 lanzamientos de una moneda normal, hay una probabilidad de 0.95 de que los promedios de la muestra estén dentro de (0.49, 0.51) ya que la raíz cuadrada de 10,000 es 100. Si en realidad hay 5300 caras en 10,000 lanzamientos, entonces Sn / n es .53, y no estamos inclinados a creer que la moneda está equilibrada a favor de pensar que está desequilibrada (p no es igual a 1/2). Cálculos como este son parte de la tradición obligatoria de la mayoría de los cursos de estadística. La distribución de valores de 10,000 muestras diferentes de ![]() para n = 15 se representa en la Fig. 4.5 (mitad superior) para el caso p = 1/2, y vemos que se agrupan alrededor de 1/2 con una dispersión que parece aproximadamente en forma de campana. La altura de cada rectángulo en la figura indica el número de todos los promedios de la muestra que se encuentran en el intervalo indicado a lo largo del eje horizontal. Para fines de comparación, la curva normal real se superpone a los rectángulos y representa el límite teórico al que se acerca la distribución de los promedios muestrales cuando n aumenta sin límite. La mitad inferior de la figura 4.5 compara la diferencia entre usar 10,000 promedios muestrales de tamaño n = 60. Dado que la dispersión de aproximadamente 1/2 disminuye inversamente con la raíz cuadrada de n, la distribución inferior es más estrecha y su pico es más alto. Parece, entonces, que del desorden de los números individuales surge una cierta legalidad cuando se ven desde lejos grandes conjuntos de números. El comportamiento desenfrenado y sin forma de estas cantidades cuando se ven de cerca se convierte en gel, en grande, en la forma ordenada en forma de campana de una "ley de errores", la ley normal. Las extensiones de la ley normal a otros ensayos p distintos de Bernoulli se conocen hoy en día como el "Teorema del límite central". Debe recordarse, sin embargo, que la ley normal es un enunciado matemático basado en un conjunto de supuestos sobre la percepción de la aleatoriedad que pueden o no siempre cuadrar completamente con la realidad. La teoría de la probabilidad permite que enunciados como la Ley de los números grandes o el Teorema del límite central reciban una prueba formal, capturando lo que parece ser la esencia de la regularidad estadística a medida que se desarrolla a partir de grandes conjuntos de datos desordenados, pero no lo hace, por sí mismo, Significa que la naturaleza nos complacerá al garantizar que el promedio de la muestra tenderá a p cuando n aumenta sin límite o que los valores del promedio de la muestra se distribuirán según una curva normal. Nadie lleva a cabo una secuencia infinita de Ensayos. En cambio, lo que tenemos es una observación empírica basada en una experiencia limitada y no una ley de la naturaleza. Esto nos recuerda una observación frecuentemente citada del matemático Henri Poincaré en el sentido de que los practicantes creen que la ley normal es un teorema de las matemáticas, mientras que los teóricos están convencidos de que es una ley de la naturaleza. Es divertido comparar esto con los comentarios extáticos del científico social del siglo XIX Francis Galton, quien escribió: “Apenas conozco algo tan apto para impresionar la imaginación como la maravillosa forma de orden cósmico expresada por la “Ley de la frecuencia del error” (la ley normal) reina con serenidad y con total modestia, en medio de la confusión más salvaje. Cuanto más grande es la mafia y mayor la aparente anarquía, más perfecta es su influencia. Es la ley suprema de la sinrazón ".
para n = 15 se representa en la Fig. 4.5 (mitad superior) para el caso p = 1/2, y vemos que se agrupan alrededor de 1/2 con una dispersión que parece aproximadamente en forma de campana. La altura de cada rectángulo en la figura indica el número de todos los promedios de la muestra que se encuentran en el intervalo indicado a lo largo del eje horizontal. Para fines de comparación, la curva normal real se superpone a los rectángulos y representa el límite teórico al que se acerca la distribución de los promedios muestrales cuando n aumenta sin límite. La mitad inferior de la figura 4.5 compara la diferencia entre usar 10,000 promedios muestrales de tamaño n = 60. Dado que la dispersión de aproximadamente 1/2 disminuye inversamente con la raíz cuadrada de n, la distribución inferior es más estrecha y su pico es más alto. Parece, entonces, que del desorden de los números individuales surge una cierta legalidad cuando se ven desde lejos grandes conjuntos de números. El comportamiento desenfrenado y sin forma de estas cantidades cuando se ven de cerca se convierte en gel, en grande, en la forma ordenada en forma de campana de una "ley de errores", la ley normal. Las extensiones de la ley normal a otros ensayos p distintos de Bernoulli se conocen hoy en día como el "Teorema del límite central". Debe recordarse, sin embargo, que la ley normal es un enunciado matemático basado en un conjunto de supuestos sobre la percepción de la aleatoriedad que pueden o no siempre cuadrar completamente con la realidad. La teoría de la probabilidad permite que enunciados como la Ley de los números grandes o el Teorema del límite central reciban una prueba formal, capturando lo que parece ser la esencia de la regularidad estadística a medida que se desarrolla a partir de grandes conjuntos de datos desordenados, pero no lo hace, por sí mismo, Significa que la naturaleza nos complacerá al garantizar que el promedio de la muestra tenderá a p cuando n aumenta sin límite o que los valores del promedio de la muestra se distribuirán según una curva normal. Nadie lleva a cabo una secuencia infinita de Ensayos. En cambio, lo que tenemos es una observación empírica basada en una experiencia limitada y no una ley de la naturaleza. Esto nos recuerda una observación frecuentemente citada del matemático Henri Poincaré en el sentido de que los practicantes creen que la ley normal es un teorema de las matemáticas, mientras que los teóricos están convencidos de que es una ley de la naturaleza. Es divertido comparar esto con los comentarios extáticos del científico social del siglo XIX Francis Galton, quien escribió: “Apenas conozco algo tan apto para impresionar la imaginación como la maravillosa forma de orden cósmico expresada por la “Ley de la frecuencia del error” (la ley normal) reina con serenidad y con total modestia, en medio de la confusión más salvaje. Cuanto más grande es la mafia y mayor la aparente anarquía, más perfecta es su influencia. Es la ley suprema de la sinrazón ".
 14.06.07.png)
Fig. 4.5 La distribución de 10,000 promedios de muestra ![]() para n = 15 en la mitad superior. La altura de cada rectángulo indica la fracción de todos los promedios de la muestra que se encuentran en el intervalo indicado del eje horizontal. La distribución de 10,000 promedios muestrales para n = 60 está en la mitad inferior. La extensión de aproximadamente la mitad en la figura inferior es menor que en la superior y alcanza su punto máximo más alto. Por tanto, el intervalo de confianza del 95% es más estrecho. Esto se debe a que la dispersión de aproximadamente ½ es inversamente proporcional a la raíz cuadrada de n. Observe que la distribución de valores parece seguir una curva normal.
para n = 15 en la mitad superior. La altura de cada rectángulo indica la fracción de todos los promedios de la muestra que se encuentran en el intervalo indicado del eje horizontal. La distribución de 10,000 promedios muestrales para n = 60 está en la mitad inferior. La extensión de aproximadamente la mitad en la figura inferior es menor que en la superior y alcanza su punto máximo más alto. Por tanto, el intervalo de confianza del 95% es más estrecho. Esto se debe a que la dispersión de aproximadamente ½ es inversamente proporcional a la raíz cuadrada de n. Observe que la distribución de valores parece seguir una curva normal.
4.3.5 ¿Es aleatorio?
Si hubiera un ejemplo de firma en las estadísticas, sería para probar si una cadena binaria en particular se debe al azar o si puede descartarse como una aberración. Dicho de otra manera, si no conoce los orígenes de esta cadena, es legítimo preguntarse si es probable que sea el resultado de un proceso aleatorio o si es una sucesión de dígitos artificial y manipulada. Veamos cómo un estadístico puede negar la hipótesis de que proviene de un mecanismo aleatorio, con un grado de confianza prescrito, aplicando el teorema de De Moivre.
En los cálculos siguientes, se elige que n sea 25 que, como resulta, es lo suficientemente grande para que la ley normal se aplique sin errores indebidos y lo suficientemente pequeño para evitar que los números se vuelvan difíciles de manejar. Suponga que se le da la siguiente cadena de 25 ceros y unos, que parece tener preponderancia de unos, y pregunta si es probable que se haya generado a partir de un proceso aleatorio con p = 1/2; los estadísticos llamarían a esto una “hipótesis nula”:
1110110001101111111011110
Ahora llevamos a cabo un cálculo que es similar al realizado un poco antes. Con ![]() denotando el número de unos, adoptemos una probabilidad de 0.95 de que el promedio muestral Sn/n difiera de 1/2 en magnitud en menos de
denotando el número de unos, adoptemos una probabilidad de 0.95 de que el promedio muestral Sn/n difiera de 1/2 en magnitud en menos de ![]() . Dado que n = 25,
. Dado que n = 25, ![]() es igual a 1/5. Por lo tanto, se espera que el promedio de la muestra se encuentre dentro del intervalo de 1/2 más o menos 1/5, es decir, (0.4, 0.6), en 19 de 20 casos. En realidad, hay 18 en la cadena dada, por lo que Sn/n es igual a 18/25 = 0.72. Este número se encuentra fuera de los límites del intervalo y, por lo tanto, la hipótesis nula de que p es igual a 1/2, se rechaza a favor de la hipótesis alternativa de que p no es igual a 1/2. Tenga en cuenta la palabra rechazar. Si el promedio de la muestra estuviese de hecho dentro del intervalo, no estaríamos aceptando la hipótesis de p = 1/2, sino simplemente no la rechazaríamos. Esto se debe a que quedan dudas sobre si la cadena se generó al azar. Podría haberse creado deliberadamente con la intención de engañar o, quizás, representa el resultado de los ensayos p de Bernoulli en los que p no es igual a 1 2. Considere, de hecho, la cadena de abajo generada con p = .4:
es igual a 1/5. Por lo tanto, se espera que el promedio de la muestra se encuentre dentro del intervalo de 1/2 más o menos 1/5, es decir, (0.4, 0.6), en 19 de 20 casos. En realidad, hay 18 en la cadena dada, por lo que Sn/n es igual a 18/25 = 0.72. Este número se encuentra fuera de los límites del intervalo y, por lo tanto, la hipótesis nula de que p es igual a 1/2, se rechaza a favor de la hipótesis alternativa de que p no es igual a 1/2. Tenga en cuenta la palabra rechazar. Si el promedio de la muestra estuviese de hecho dentro del intervalo, no estaríamos aceptando la hipótesis de p = 1/2, sino simplemente no la rechazaríamos. Esto se debe a que quedan dudas sobre si la cadena se generó al azar. Podría haberse creado deliberadamente con la intención de engañar o, quizás, representa el resultado de los ensayos p de Bernoulli en los que p no es igual a 1 2. Considere, de hecho, la cadena de abajo generada con p = .4:
0101110 010 0101111110 01000
En este caso Sn = 13/25 = .52, dentro del intervalo designado, aunque la moneda hipotética que generó la cadena está sesgada. Del mismo modo, aunque la secuencia
0101010101010101010101010
tiene un patrón que se repite regularmente, encontramos que ![]() es 12/25 = 0.48 y, por lo tanto, la hipótesis nula de aleatoriedad no puede rechazarse a pesar de la naturaleza sospechosa de la cadena.
es 12/25 = 0.48 y, por lo tanto, la hipótesis nula de aleatoriedad no puede rechazarse a pesar de la naturaleza sospechosa de la cadena.
La decisión de no rechazar es una táctica de precaución a la luz de la evidencia, con el acuerdo de que una probabilidad de .95 es la línea de demarcación para la incredulidad. En las primeras páginas del libro Strong Poison de Dorothy Sayer de 1930, hay una situación análoga a la adoptada en un tribunal de justicia en la que “todo acusado es considerado inocente a menos y hasta que se demuestre lo contrario”. No es necesario que él o ella demuestren su inocencia; en la jerga moderna, depende de la fiscal probar la culpabilidad y, a menos que esté completamente satisfecho de que la fiscal lo ha hecho más allá de cualquier duda razonable, es su deber emitir un veredicto de "no culpable". no significa que la prisionera haya demostrado su inocencia mediante pruebas; simplemente significa que la fiscal no ha logrado producir en sus mentes una indudable convicción de culpabilidad.
La otra cara de la moneda, sin embargo, es que uno puede equivocarse al rechazar una secuencia en particular, como una cadena de ceros en su mayoría, aunque podría, de hecho, haber sido generada por un proceso de Bernoulli 1/2 de resultados uniformemente distribuidos. No solo se puede liberar a una persona verdaderamente culpable, sino que también se puede juzgar culpable a un alma inocente. La prueba invocada anteriormente no es evidentemente un poderoso discriminador de aleatoriedad. Después de todo, solo verifica el equilibrio relativo entre ceros y unos como medida de probabilidad. Lo incluí únicamente para ilustrar la ley normal y para proporcionar la primera, históricamente la más antigua y posiblemente la más débil de las herramientas del arsenal necesario para responder a la pregunta "¿es aleatorio?"
Hay una serie de otras pruebas estadísticas, decididamente más sólidas y reveladoras, para decidir que una secuencia binaria es aleatoria. Se podría, por ejemplo, comprobar si el el número total de corridas sucesivas de ceros o unos, o las longitudes de estas corridas, es consistente con la aleatoriedad en algún nivel de confianza apropiado. Una serie de ceros significa una sucesión ininterrumpida de ceros en la cadena flanqueada por el dígito uno o por ningún dígito, y una serie de unos se define de manera similar.
Muy pocas cadenas de números, o cadenas de longitud excesiva, son indicadores de falta de aleatoriedad, al igual que demasiadas cadenas en las que cero y uno se alternan con frecuencia. Esto puede ser arbitrado por un procedimiento estadístico llamado prueba de cadenas que es demasiado extenso para ser descrito aquí, pero veamos dos ejemplos para ver qué implica.
La secuencia 0000000000000111000000000 tiene 2 cadenas de ceros y una sola cadena de unos, mientras que la secuencia 0101010101010101010101010 tiene 12 cadenas de 1 y 13 de cero. Ninguna de estas secuencias se aprobaría como aleatoria usando una prueba de corridas con un nivel de confianza apropiado, aunque el uso del teorema de De Moivre no rechaza la aleatoriedad de la segunda cadena, como vio. Examinar las cadenas y sus longitudes plantea la interesante pregunta de cómo las personas perciben la aleatoriedad.
La tendencia es que los individuos rechacen patrones tales como un largo plazo como no típico de la aleatoriedad y compensen esto juzgando que las alternancias frecuentes entre ceros y unos son más típicas del azar. Los experimentos de psicólogos que piden a los sujetos que produzcan o evalúen una sucesión de dígitos revelan un sesgo a favor de más alternancias de las que se puede esperar que tenga una cadena aleatoria aceptable; la gente tiende a considerar una agrupación de dígitos como un patrón de orden característico cuando, de hecho, la cadena se genera aleatoriamente. Frente a HHHTTT y HTTHTH, ¿cuál crees que es más aleatorio? Ambos, por supuesto, son resultados igualmente probables de lanzar una moneda justa. Por cierto, la gente también tiende a discernir patrones siempre que ocurre una densidad desigual de puntos espacialmente, incluso si en realidad, los puntos se distribuyen al azar. La aparición de grupos en algunas partes del espacio puede llevar a algunos observadores a concluir erróneamente que hay algún mecanismo causal en juego. Una alta incidencia de cáncer en ciertas comunidades, por ejemplo, a veces se considera el resultado de alguna condición ambiental local cuando, de hecho, puede ser consistente con un proceso aleatorio. Los psicólogos comentan[9] que la evaluación de la aleatoriedad de un individuo en los lanzamientos de una moneda justa parece basarse en la probabilidad igual de los dos resultados junto con alguna irregularidad en el orden de aparición; se espera que estos se manifiesten no solo a largo plazo, sino incluso en segmentos relativamente cortos, tan cortos como seis o siete. Las fallas en los juicios de la gente sobre la aleatoriedad en lo grande es el precio de su insistencia en que se manifieste en lo pequeño. Los autores proporcionan un ejemplo divertido de esto cuando citan a Linus en la tira cómica "Peanuts”.
Linus está tomando una prueba de verdadero-falso y decide frustrar a los examinadores ideando un orden "aleatorio" de TFFTFT; luego exclama triunfalmente "si eres lo suficientemente inteligente, puedes pasar una prueba de verdadero o falso sin ser inteligente". Evidentemente, Linus entiende que para que una secuencia corta de seis o siete T y F se perciba como aleatoria, sería prudente no generarla a partir de ensayos de Bernoulli 1/2, ya que esto podría resultar fácilmente en una cadena de aspecto no aleatorio. La ilusión de la aleatoriedad también se puede imponer a un observador desprevenido de otras formas. Una baraja de cartas conserva un vestigio de "memoria" de manos anteriores a menos que se haya barajado muchas veces. Una mezcla permuta el orden de las cartas, pero la disposición anterior no se borra por completo, y puede engañarse pensando que el paquete ahora está ordenado al azar. Vimos que los números enteros se pueden representar mediante cadenas binarias finitas. Resulta que cualquier número, en particular todos los números entre cero y uno se pueden expresar de manera similar en términos de una cadena binaria que suele tener una longitud infinita. Aceptamos este hecho en este momento y dejamos los detalles. El matemático Emile Borel definió un número entre cero y uno como normal (no debe confundirse con el término "normal" usado anteriormente) si cada dígito 0 o 1 en la cadena binaria que representa, el número aparece con la misma frecuencia a medida que el número de dígitos crece hasta el infinito y, además, si las proporciones de todas las corridas posibles de dígitos binarios de una longitud determinada también son iguales. En otras palabras, para que x sea normal, no solo deben aparecer 0 y 1 con la misma frecuencia en la representación binaria de x, sino que también deben aparecer 00, 01, 10 y 11 y, de manera similar, los 8 tripletes 000, 001 ,…, 111. Lo mismo, además, debe ser cierto para cada una de las ![]() k-tuplas de cualquier longitud k. Dado que los dígitos sucesivos son independientes, la probabilidad de cualquier bloque de longitud k es la misma. En un sentido técnico preciso en el que no necesitamos entrar aquí, la mayoría de los números son normales, cualquier candidato razonable para una secuencia aleatoria debe, como mínimo, definir un número normal aunque proporcione un número explícito. El único ejemplo ampliamente citado, debido a D. Champernowne, es el número cuya representación binaria se encuentra tomando cada dígito individualmente y luego en pares y luego en tripletes, y así sucesivamente:
k-tuplas de cualquier longitud k. Dado que los dígitos sucesivos son independientes, la probabilidad de cualquier bloque de longitud k es la misma. En un sentido técnico preciso en el que no necesitamos entrar aquí, la mayoría de los números son normales, cualquier candidato razonable para una secuencia aleatoria debe, como mínimo, definir un número normal aunque proporcione un número explícito. El único ejemplo ampliamente citado, debido a D. Champernowne, es el número cuya representación binaria se encuentra tomando cada dígito individualmente y luego en pares y luego en tripletes, y así sucesivamente:
0100011011000001010100 ⊃
4.3.6 Una perspectiva bayesiana
A mediados del siglo XVIII, surgió un nuevo y sutil sesgo sobre la idea del azar basado en el trabajo de un clérigo oscuro, el reverendo Thomas Bayes, quien, en 1763, publicó póstumamente un panfleto titulado “Un ensayo para resolver un problema en la Doctrina de las Oportunidades”. Su trabajo fue ampliado y aclarado por Pierre-Simon Laplace un poco más tarde en 1774. Aunque Bernoulli había establecido la probabilidad de que las medias muestrales ![]() se encuentren dentro de algún intervalo fijo sobre la probabilidad conocida p de algún evento, la perspectiva cambió a la obtención de la probabilidad de que una probabilidad desconocida de un evento se encuentre dentro de un intervalo dado de medias muestrales. Podemos decir que si Bernoulli razonó de causa a efecto, entonces Bayes y Laplace trabajaron en la dirección opuesta de un efecto a una causa. A primera vista, estos suenan como objetivos equivalentes, ya que para n lo suficientemente grandes, las medias muestrales se acercan a la probabilidad dada con una confianza creciente, por lo que uno podría ser excusado por tomar el valor de p para igualar el límite de las muestras. Esto se llama la definición frecuentista de probabilidad, es decir, que p es igual a la frecuencia límite (o, de manera equivalente, la proporción) de éxitos en n ensayos a medida que n se vuelve cada vez más grande. De manera más general, si un evento E ocurre r veces en n ensayos independientes, la probabilidad de E es casi igual a la frecuencia relativa r/n para n suficientemente grande. Todo lo que hemos hecho hasta ahora ha estado en consonancia con este punto de vista.
se encuentren dentro de algún intervalo fijo sobre la probabilidad conocida p de algún evento, la perspectiva cambió a la obtención de la probabilidad de que una probabilidad desconocida de un evento se encuentre dentro de un intervalo dado de medias muestrales. Podemos decir que si Bernoulli razonó de causa a efecto, entonces Bayes y Laplace trabajaron en la dirección opuesta de un efecto a una causa. A primera vista, estos suenan como objetivos equivalentes, ya que para n lo suficientemente grandes, las medias muestrales se acercan a la probabilidad dada con una confianza creciente, por lo que uno podría ser excusado por tomar el valor de p para igualar el límite de las muestras. Esto se llama la definición frecuentista de probabilidad, es decir, que p es igual a la frecuencia límite (o, de manera equivalente, la proporción) de éxitos en n ensayos a medida que n se vuelve cada vez más grande. De manera más general, si un evento E ocurre r veces en n ensayos independientes, la probabilidad de E es casi igual a la frecuencia relativa r/n para n suficientemente grande. Todo lo que hemos hecho hasta ahora ha estado en consonancia con este punto de vista.
Una forma caprichosa de pensar en la diferencia entre los dos enfoques es que si Bernoulli nos dice que p es la probabilidad de sacar cara al lanzar en una moneda, está haciendo una proclamación sobre el comportamiento de la moneda, mientras que Bayes no sabe lo que hará la moneda y, por lo tanto, lo que afirma no se trata de la moneda en sí, sino de su creencia con respecto a lo que hará la moneda. Para explicar el enfoque bayesiano de manera más general, se requiere un breve desvío para introducir probabilidades condicionales. Suponga que para dos eventos cualesquiera, llamémoslos A y B, construimos un nuevo evento "A y B" para significar que si uno ha ocurrido, también lo ha hecho el otro e indicamos este hecho usando la abreviatura A∩B. Entonces la notación probabilidad P(A | B) denotará "la probabilidad de que el evento A ocurra condicionada al hecho de que el evento B haya tenido lugar". Ésta es una cantidad que es proporcional a la probabilidad de A ∩ B porque B es ahora donde está toda la acción, por lo que quiero decir que el espacio muestral original se ha reducido a solo B, como se ilustra en la figura 1.4. Se proporcionan más detalles en las Notas técnicas, pero un punto que debe señalarse de inmediato es que se puede definir igualmente la probabilidad opuesta de que "el evento B ocurra dado que el evento A ha tenido lugar". Estas dos probabilidades condicionales que apuntan en direcciones contrarias pueden ser, ya menudo son, bastante diferentes. El caso citado anteriormente con respecto a las medias muestrales es una confusión bastante benigna que hace poco daño, pero en general el mal uso de condicionales puede ser más preocupante. El enfoque bayesiano, tal como se utiliza en la práctica contemporánea, debe comenzar con un grado de creencia acerca de alguna hipótesis o suposición denotada por H y que se cuantifica como una probabilidad previa. Luego, se calcula la probabilidad condicional de que se observe un resultado B si H es verdadero. Esto se conoce como la probabilidad de la evidencia B dada la hipótesis H. Finalmente, un uso hábil de probabilidades condicionales, conocido como Teorema de Bayes, establece que la probabilidad posterior de H basada en la evidencia conocida, es decir, P(H | B), se puede determinar combinando P(B | H) con la probabilidad previa de H. Le ahorraremos los detalles matemáticos de cómo ocurre esto Fig. 4.6. Pueden surgir muchas complicaciones por un uso inadecuado de las probabilidades condicionales.
Existe una clase de juicios mal informados que se producen en los exámenes médicos y los juicios penales, entre otros entornos, en los que una probabilidad condicional en una dirección se malinterpreta en el sentido opuesto. Pero estos dos números pueden ser muy diferentes, y esto conduce a consecuencias que son, como mínimo, problemáticas y, a menudo, bastante graves. Este no es el lugar para explorar los usos atroces de la probabilidad en los asuntos cotidianos.
 13.11.19.png)
Fig. 4.6 Intersección de los eventos A y B
4.3.6.1 Dónde estamos ahora
En este terreno tomamos el punto de vista de que la aleatoriedad es una noción que pertenece a un conjunto de posibilidades, cuya incertidumbre es una propiedad del mecanismo que genera estos resultados, y no una propiedad de ninguna secuencia individual. Sin embargo, somos reacios a llamar aleatoria a una cadena de 100 dígitos si el cero se repite 100 veces, por lo que lo que necesitamos es una forma de ver lo que una serie individual de ceros y unos puede decirnos sobre la aleatoriedad independientemente de su procedencia.
El cambio de énfasis consiste en mirar la disposición de una cadena completamente desarrollada por sí misma y no en lo que la generó. Ésta es una de las tareas que tenemos ante nosotros. En particular, se verá que la aleatoriedad puede rechazarse cuando existen reglas simples que predicen en gran medida los dígitos sucesivos de una cadena. El número de Champernowne que se discutió no calificará como aleatorio, por ejemplo. Los argumentos utilizados en el resto del texto son bastante diferentes de los empleados en el presente apartado en el que se invocó la ley normal para tamaños de muestra grandes para probar una suposición a priori sobre la aleatoriedad de una cadena.
Aunque este enfoque sigue siendo parte del canon central de la teoría estadística, los temas siguientes se centrarán menos en la aleatoriedad del proceso de generación y más en los patrones que realmente se producen. Hay una serie de sorpresas en el almacén y, en particular, nuevamente estaremos engañados al creer que una cadena de dígitos es aleatoria cuando el mecanismo que se generó no es aleatorio y viceversa.
Terminemos con una cita del matemático Pierre-Simon Laplace, él mismo un importante contribuyente a la teoría de la probabilidad en la primera parte del siglo XIX, quien sin saberlo anticipó la necesidad de un nuevo enfoque: “en el juego de cara y cruz , si la cabeza sale cien veces seguidas entonces esto nos parece extraordinario, porque después de dividir el número casi infinito de combinaciones que pueden surgir en cien lanzamientos en secuencias regulares, como aquellas en las que observamos una regla que es fácil de captar, y en secuencias irregulares, estos últimos son incomparablemente más numerosos ".
4.4 Incertidumbre e información
Norman ... miró muchas estadísticas en su vida, buscando patrones en los datos. Eso era algo en lo que los cerebros humanos eran intrínsecamente buenos, encontrando patrones en el material visual. Norman no pudo señalarlo, pero sintió un patrón aquí. Dijo, tengo la sensación de que no es al azar.
De Esfera, por Michael Crichton
4.4.1 Mensajes e información
Hace medio siglo, Claude Shannon, matemático e ingeniero innovador de lo que entonces se llamaba Bell Telephone Laboratories, formuló la idea de que el contenido de la información reside en un mensaje y, en un artículo fundamental de 1948, estableció la disciplina que se conoció como teoría de la información. Aunque su influencia se encuentra principalmente en la ingeniería de la comunicación, la teoría de la información ha llegado a desempeñar un papel importante en años más recientes para dilucidar el significado del azar y la Genómica. Shannon imaginó una fuente de símbolos que se seleccionan, uno a la vez, para generar mensajes que se envían a un destinatario. Los símbolos podrían ser, por ejemplo, los diez dígitos 0, 1,…, 9 o las primeras 13 letras del alfabeto, o una selección de 10,000 palabras de algún idioma, o incluso textos completos. Todo lo que importa para la generación de mensajes es que exista una paleta de opciones representadas por lo que se denominan vagamente "símbolos de un alfabeto“. Una propiedad clave de la fuente es la incertidumbre en cuanto a qué símbolo se elige realmente cada vez. Se dice que la libertad de elección que tiene la fuente para seleccionar un símbolo entre otros es su contenido de información. A medida que se desarrolle esta discusión, resultará evidente que el contenido máximo de información es sinónimo de aleatoriedad y que una secuencia binaria generada a partir de una fuente que consta de solo dos símbolos 0 y 1 no puede ser aleatoria si existe alguna restricción sobre la libertad que la fuente tiene para elegir cualquiera de estos dígitos. La identificación del azar con la información nos permitirá cuantificar el grado de aleatoriedad en una cadena y responder a la pregunta “¿es aleatorio?” De una manera diferente a la discusión anterior.
El caso más simple a considerar es un alfabeto fuente que consta de solo dos símbolos, 0 y 1, que generan mensajes que son cadenas binarias. Si hay una elección igual entre los dos símbolos alternativos, decimos que la información en esta elección es un bit. Basta pensar en un interruptor con dos posibles posiciones 0 y 1, en el que se elige una u otra con probabilidad 1/2. Con dos conmutadores independientes, el número de resultados igualmente probables es 00, 01, 10 y 11, y se dice que hay dos bits de información. Con tres conmutadores independientes, hay 23 = 8 resultados posibles 000, 001, 010, 011, 100, 101, 110 y 111, cada uno de los cuales consta de tres bits de información; en general, n conmutadores dan como resultado una elección igual entre ![]() posibilidades, cada una codificada como una cadena de n ceros y unos, o n bits. Puede considerar las cadenas como mensajes generados independientemente uno a la vez por una fuente utilizando sólo dos símbolos o, alternativamente, los mensajes pueden considerarse como símbolos, cada uno de los cuales representa una de las
posibilidades, cada una codificada como una cadena de n ceros y unos, o n bits. Puede considerar las cadenas como mensajes generados independientemente uno a la vez por una fuente utilizando sólo dos símbolos o, alternativamente, los mensajes pueden considerarse como símbolos, cada uno de los cuales representa una de las ![]() cadenas igualmente probables de longitud n. Con los mensajes como símbolos, el alfabeto fuente consta de
cadenas igualmente probables de longitud n. Con los mensajes como símbolos, el alfabeto fuente consta de ![]() mensajes y su contenido de información es de n bits, mientras que una fuente binaria tiene un contenido de información de un bit.
mensajes y su contenido de información es de n bits, mientras que una fuente binaria tiene un contenido de información de un bit.
Puede considerar las cadenas como mensajes generados independientemente uno a la vez por una fuente utilizando solo dos símbolos o, alternativamente, los mensajes pueden considerarse como símbolos, cada uno de los cuales representa una de las ![]() cadenas igualmente probables de longitud n. Con los mensajes como símbolos, el alfabeto fuente consta de
cadenas igualmente probables de longitud n. Con los mensajes como símbolos, el alfabeto fuente consta de ![]() mensajes y su contenido de información es de n bits, mientras que una fuente binaria tiene un contenido de información de un bit.
mensajes y su contenido de información es de n bits, mientras que una fuente binaria tiene un contenido de información de un bit.
Existe incertidumbre en cuanto a qué cadena de mensaje encapsulada por n dígitos binarios es la que realmente se elige de una fuente de mensaje de ![]() cadenas posibles. A medida que n aumenta, también lo hace la vacilación y, por lo tanto, el contenido de información de la fuente se convierte en una medida del grado de duda sobre qué mensaje se selecciona realmente. Sin embargo, una vez elegido, la ambigüedad con respecto a un mensaje se disipa ya que ahora sabemos cuál es el mensaje. Se puede esperar que la mayoría de las cadenas no tengan un orden o patrón reconocible, pero algunas de ellas pueden proporcionar un elemento de sorpresa en el sentido de que percibimos un patrón ordenado y no basura. La sorpresa al descubrir una cadena inesperada y útil entre muchas aumenta a medida que aumenta el contenido de información de la fuente. Sin embargo, el orden (y el desorden) está en el ojo del espectador, y la selección de cualquier otra cadena, con patrón o no, es igualmente probable y sorprendente. Los n bits necesarios para describir los m =
cadenas posibles. A medida que n aumenta, también lo hace la vacilación y, por lo tanto, el contenido de información de la fuente se convierte en una medida del grado de duda sobre qué mensaje se selecciona realmente. Sin embargo, una vez elegido, la ambigüedad con respecto a un mensaje se disipa ya que ahora sabemos cuál es el mensaje. Se puede esperar que la mayoría de las cadenas no tengan un orden o patrón reconocible, pero algunas de ellas pueden proporcionar un elemento de sorpresa en el sentido de que percibimos un patrón ordenado y no basura. La sorpresa al descubrir una cadena inesperada y útil entre muchas aumenta a medida que aumenta el contenido de información de la fuente. Sin embargo, el orden (y el desorden) está en el ojo del espectador, y la selección de cualquier otra cadena, con patrón o no, es igualmente probable y sorprendente. Los n bits necesarios para describir los m = ![]() mensajes generados por una fuente binaria están relacionados por la expresión matemática n=log m donde "log" significa "logaritmo en base 2 de". La cantidad log m se define formalmente como el número para el cual
mensajes generados por una fuente binaria están relacionados por la expresión matemática n=log m donde "log" significa "logaritmo en base 2 de". La cantidad log m se define formalmente como el número para el cual ![]() . Como 20 = 1 y 21 = 2, de la definición se deduce que log 1 = 0 y log 2 = 1. Se pueden encontrar propiedades adicionales de los logaritmos (si no está familiarizado con los logaritmos, simplemente piense en ellos como un dispositivo de notación para representar ciertas expresiones numéricas que involucran exponentes en una forma compacta). Utilizamos los logaritmos con moderación, pero no podemos evitarlos por completo porque son necesarios para formalizar la noción de contenido de información de Shannon. De hecho, Shannon define el contenido de información de m elecciones igualmente probables e independientes como exactamente log m. Con m = 1 (sin elección), la información es cero, pero para m =
. Como 20 = 1 y 21 = 2, de la definición se deduce que log 1 = 0 y log 2 = 1. Se pueden encontrar propiedades adicionales de los logaritmos (si no está familiarizado con los logaritmos, simplemente piense en ellos como un dispositivo de notación para representar ciertas expresiones numéricas que involucran exponentes en una forma compacta). Utilizamos los logaritmos con moderación, pero no podemos evitarlos por completo porque son necesarios para formalizar la noción de contenido de información de Shannon. De hecho, Shannon define el contenido de información de m elecciones igualmente probables e independientes como exactamente log m. Con m = 1 (sin elección), la información es cero, pero para m = ![]() el contenido de la información es n bits. En el caso de que una fuente funcione a partir de un alfabeto de k símbolos, todos igualmente probables y elegidos de forma independiente, genera un total de m =
el contenido de la información es n bits. En el caso de que una fuente funcione a partir de un alfabeto de k símbolos, todos igualmente probables y elegidos de forma independiente, genera un total de m = ![]() cadenas de mensajes de longitud n, cada una con la misma probabilidad de ocurrir. En este caso, el contenido de información por cadena es log m = n log k, mientras que el contenido de información por símbolo es simplemente log k. Con tres símbolos A, B y C, por ejemplo, hay 32 = 9 mensajes de longitud 2, a saber, AA, AB, AC, BA, BB, BC, CA, CB y CC. Por tanto, el contenido de información de la fuente es dos veces log 3 o, aproximadamente, 3.17.
cadenas de mensajes de longitud n, cada una con la misma probabilidad de ocurrir. En este caso, el contenido de información por cadena es log m = n log k, mientras que el contenido de información por símbolo es simplemente log k. Con tres símbolos A, B y C, por ejemplo, hay 32 = 9 mensajes de longitud 2, a saber, AA, AB, AC, BA, BB, BC, CA, CB y CC. Por tanto, el contenido de información de la fuente es dos veces log 3 o, aproximadamente, 3.17.
La palabra "información" tal como la usa Shannon no tiene nada que ver con "significado" en el sentido convencional. Si los símbolos representan mensajes, un destinatario puede ver uno de ellos como muy significativo y otro como una charla inactiva. La diferencia entre información y significado puede ilustrarse mediante una fuente que consta de ocho símbolos igualmente probables A, D, E, M, N, O, R y S que generan todas las palabras que tienen 10 letras. La mayoría de estas palabras son un galimatías, pero si la aleatoriedad aparece en el conjunto de 210 = 1024 palabras posibles, hay buenas razones para asustarse y sentir que tal vez somos receptores de un presagio. Sin embargo, la palabra RRRRRRRRRR tiene la misma probabilidad de aparecer y no debería sorprendernos menos. Otro ejemplo sería una fuente cuyos símbolos consisten en un conjunto de instrucciones en inglés. El contenido de información de esta fuente no nos dice nada sobre el significado de los símbolos individuales. Un mensaje podría indicarle que abra un cajón y lea el contenido, que resulta ser una descripción completa del genoma humano. El mensaje desempaquetado transmite un significado enorme para un genetista. El siguiente mensaje te indica que apagues al gato, lo que posiblemente no sea muy significativo (excepto, por supuesto, para el gato).
4.4.2 Entropía
Después de estos preliminares, consideramos m posibilidades, cada una de las cuales no está influenciada por las otras y elegida con probabilidades ![]() quizás desiguales para el i-ésimo símbolo, siendo i cualquier número entero de 1 a m. El espacio muestral consta de m eventos elementales "se elige el i-ésimo símbolo". Estas probabilidades suman uno, por supuesto, ya que las m opciones mutuamente excluyentes agotan el espacio muestral de resultados. El contenido de información promedio de esta fuente, denotado por H, fue definido por Shannon como el negativo de la suma de los logaritmos del
quizás desiguales para el i-ésimo símbolo, siendo i cualquier número entero de 1 a m. El espacio muestral consta de m eventos elementales "se elige el i-ésimo símbolo". Estas probabilidades suman uno, por supuesto, ya que las m opciones mutuamente excluyentes agotan el espacio muestral de resultados. El contenido de información promedio de esta fuente, denotado por H, fue definido por Shannon como el negativo de la suma de los logaritmos del
![]()
o, en forma más compacta,
![]()
La expresión H se denomina entropía de la fuente y representa el contenido de información promedio de la fuente, en bits por símbolo. Aunque esta definición parece artificial, es exactamente lo que se necesita para extender la idea de información a símbolos que aparecen con frecuencias desiguales. Además, se reduce a la medida del contenido de información considerado previamente para el caso en el que los m símbolos tienen la misma probabilidad de ser elegidos. Cuando la fuente consta de m =![]() cadenas de mensajes, cada una de las cuales tiene quizás diferentes probabilidades de ocurrir, H se considera el contenido de información promedio en bits por mensaje.
cadenas de mensajes, cada una de las cuales tiene quizás diferentes probabilidades de ocurrir, H se considera el contenido de información promedio en bits por mensaje.
Para ilustrar el cálculo de la entropía, considere un tablero dividido en 16 cuadrados del mismo tamaño y suponga que se le pide que determine qué cuadrado (ver Fig. 4.7) tiene algún objeto participando en una variante del juego "20 preguntas". Usted hace las siguientes preguntas con respuesta sí o no:
¿Es uno de los 8 cuadrados de la mitad superior del tablero? (No)
¿Es uno de los 4 cuadrados de la mitad derecha de las 8 posibilidades restantes? (Sí) ¿Es uno de los 2 cuadrados de la mitad superior de las 4 posibilidades restantes? (Sí) ¿Es el cuadrado a la derecha de las 2 posibilidades restantes? (No)
 13.50.19.png)
Fig. 4.7 Un tablero dividido en 16 casillas, todas vacías excepto una, que contiene un objeto cuya ubicación será determinada por un concursante con los ojos vendados en una variante del juego “20 preguntas”.
Dejando que uno signifique sí y cero no, el cuadrado descubierto está determinado por la cadena 0110 porque su ubicación está determinada por no sí sí no. Cada pregunta reduce progresivamente la incertidumbre y la cantidad de información que recibe sobre la posición desconocida disminuye en consecuencia.
Hay 16 = 24 cuadrados posibles para elegir inicialmente, todos igualmente probables y, por lo tanto, 16 cadenas binarias diferentes.
La incertidumbre antes de que se haga la primera pregunta, a saber, la entropía, es por lo tanto log 16 = 4 bits por cadena. La entropía disminuye a medida que avanza el juego. Para una fuente binaria que consta de solo dos símbolos con probabilidades p y 1 - p, la expresión para la entropía H se simplifica a:
![]()
 13.57.21.png)
Fig. 4.8 Gráfica de entropía H versus probabilidad p para una fuente binaria que consta de solo dos símbolos con probabilidades p y 1 - p. Tenga en cuenta que H se maximiza cuando p es ½ y es cero cuando no hay incertidumbre (p igual a 0 o 1).
La figura 4.8 traza los valores de H para una fuente binaria versus la probabilidad p, y vemos que H se maximiza cuando p = 1/2 en cuyo punto H = 1 (ya que log 2 = 1); de lo contrario, H es menor que 1. Con p = 3/4, por ejemplo, la entropía H es - {.75 log .75 + .25 log .25} que es aproximadamente .81. En general, para una fuente no binaria, es posible mostrar que H se maximiza cuando las m opciones independientes son igualmente probables, en cuyo caso H se convierte en log m, como ya se señaló. De conformidad con la discusión del capítulo anterior, la máxima entropía se identifica con la aleatoriedad por excelencia. Esto se ilustra en el juego de mesa de la figura 4.7, donde la entropía es máxima ya que las cuatro opciones son independientes y tienen la misma probabilidad 1/2 de ser verdaderas.
El concepto de entropía nos permitirá dar un nuevo significado en el siguiente apartado a la pregunta "¿Es aleatorio?" Es importante enfatizar que la información se equipara con la incertidumbre en el sentido de que cuanto más inconscientes seamos acerca de alguna observación o hecho, mayor es la información que recibimos cuando ese hecho es revelado. A medida que aumenta la incertidumbre, también aumenta la entropía, ya que la entropía mide la información. Una simple elección entre dos mensajes alternativos es levemente informativa, pero tener un mensaje confirmado entre muchos tiene un grado de inesperado y sorpresa que es muy informativo. Sin elección, no hay información o entropía cero. Sin embargo, el contenido del mensaje es irrelevante, como ya hemos subrayado. La entropía en una fuente binaria no se ve afectada por el hecho de que un símbolo representa un libro de texto de mil páginas y el otro un simple "duh".
4.4.3 Mensajes, códigos y entropía
Si las probabilidades p y 1 - p en una fuente binaria son desiguales, entonces los patrones de ceros o unos repetidos tenderán a repetirse y el conjunto tiene cierta redundancia. Si es posible reducir la redundancia comprimiendo el mensaje, entonces una secuencia binaria más corta puede servir como código para reproducir el todo. En una cadena verdaderamente aleatoria, se ha eliminado toda la redundancia y no es posible una mayor compresión.
La cadena ahora es lo más corta posible. Debido a las redundancias, algunos mensajes del total generado por una fuente binaria son más probables que otros debido al hecho de que ciertos patrones se repiten. Por lo tanto, existe una alta probabilidad de que algunos pequeños subconjuntos de mensajes se formen realmente del total que es posible. La colección restante (grande) de mensajes tiene una pequeña probabilidad de aparecer, de lo que se deduce que se pueden codificar la mayoría de los mensajes con un número menor de bits. De todos los mensajes de longitud n que posiblemente puedan ser generados por los ensayos p de Bernoulli, lo más probable es que solo una pequeña fracción de ellos ocurra realmente cuando p no es igual a 1/2. En lugar de requerir n bits para codificar cada cadena de mensaje, basta con usar nH bits para representar todo menos un subconjunto (grande) de cadenas para una fuente de mensaje de entropía H. Por lo tanto, el número requerido de bits por símbolo es aproximadamente nH / n = H. Esta compresión en la longitud del mensaje es efectiva solo cuando H es menor que 1 (p no es igual a 1 - p) ya que H es igual a uno cuando p = 1/2. Dicho de una manera ligeramente diferente, todos los mensajes de tamaño n se pueden dividir en dos subconjuntos, uno de ellos una pequeña fracción del total que contiene mensajes que ocurren un gran porcentaje del tiempo y una fracción mucho mayor que consiste en mensajes que rara vez aparecen. Esto sugiere que deben usarse códigos cortos para el subconjunto más probable y códigos más largos para el resto a fin de lograr una descripción promedio más baja de todos los mensajes. La excepción a esto, por supuesto, es cuando p = 1/2 ya que todos los mensajes son igualmente probables. Para aprovechar la compresión de mensajes, debemos encontrar una codificación adecuada, pero la forma de hacerlo es menos que obvia. Describiré aquí una codificación razonable, pero no máximamente eficiente, y la aplicaremos a una secuencia específica si no hay compresibilidad. Sin embargo, si se puede encontrar una cadena más corta para generar el todo, una cadena más corta que codifica la más larga, entonces debe haber patrones reconocibles que redujeron la incertidumbre. El enfoque adoptado por Kolmogorov es diferente al de Shannon, como veremos, ya que depende del uso de algoritmos computables para generar cadenas, y esto trae consigo la parafernalia de las máquinas de Turing.
Tome una cadena binaria creada por Bernoulli p-trial en la que la probabilidad de un cero es .1 y la de uno es .9 (p = .9). Divida la cadena en fragmentos consecutivos de longitud 3. Dado que es más probable que aparezcan bloques de unos consecutivos que ceros, asigne un 0 a cualquier triplete 111. Si hay un solo cero en un triplete, codifique esto con un 1 seguido de 00 , 01 o 10 para indicar si el cero apareció en la primera, segunda o tercera posición. En el caso menos frecuente de 2 ceros, comience el código con un prefijo de 111 seguido de 0001 (primera y segunda posiciones), 0010 (primera y tercera posiciones) o 0110 (segunda y tercera posiciones). Al evento raro de todos los ceros se le asigna 11111111. Considere, por ejemplo, el fragmento de cadena 110 111 101 010 111 110 111 que consta de siete tripletes con un total de 21 bits. Estos tripletes están codificados, en secuencia, por las palabras 110, 0, 101, 1110010, 0, 110 y 0. El código requiere 19 bits, una ligera compresión del mensaje original.
En general, la reducción es considerablemente mejor ya que se producirá un número mucho mayor de unos en promedio para los ensayos de Bernoulli 9/10 reales que lo que indica la cadena elegida arbitrariamente aquí. Tenga en cuenta que este esquema de codificación tiene la virtud de ser un código de prefijo, lo que significa que ninguna de las palabras de código son prefijos entre sí. Cuando llega al final de una palabra de código, sabe que es el final, ya que no aparece ninguna palabra al principio de cualquier otra palabra de código. Esto significa que existe una correspondencia única entre los tripletes de mensajes y las palabras que los codifican, por lo que es posible leer el código hacia atrás para descifrar el mensaje. Esto es evidente en el ejemplo anterior, en el que ninguna de las siete palabras de código vuelve a aparecer como prefijo de ninguna de las otras palabras. Ahora puede leer con confianza el fragmento 11001110010 de izquierda a derecha y encontrar que 1 por sí solo no significa nada, ni 11. Sin embargo, 110 significa 110. Continuando, se encuentra con 0, que denota 111. Continuando, debe leer antes para el septuple 1110010 para descubrir que este es el código para 010; nada menos que los siete dígitos completos tiene algún significado cuando se escanea de izquierda a derecha. En total, el mensaje descifrado es 1101010.
Aunque la discusión de códigos se ha restringido a solo dos símbolos, cero y uno, se aplican resultados similares a fuentes que tienen alfabetos de cualquier tamaño k como el ADN. Suponga que el i-ésimo símbolo ocurre con probabilidad 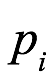 con i = 1,…, k. Shannon estableció que existe una codificación de prefijo binario de los k símbolos en la que la longitud promedio de las palabras de código en bits por símbolo es casi igual a la entropía H de la fuente. Como consecuencia de esto, un mensaje de longitud n puede codificarse con aproximadamente nH bits. Considere, por ejemplo, una fuente con cuatro símbolos a, b, c y d que tienen probabilidades 1/2, 1/4, 1/8 y 1/8, respectivamente. La entropía se calcula en 1.75, y si las palabras de código se eligen como 0 para a, 10 para b, 110 para c y 111 para d, entonces esto corresponde a longitudes de palabras de código de 1, 2, 3, 3 cuyo promedio la longitud es 1.75 que, al menos en este caso, es igual a la entropía. En el ejemplo dado en los dos párrafos anteriores, la fuente constaba de los ocho tripletes 000, 001,…, 111 de dígitos binarios independientes en los que la probabilidad de 111, por ejemplo, es 9/10 multiplicado por sí mismo tres veces, o aproximadamente 0.73, con un cálculo similar para todos los demás tripletes. Aunque se diseñó un código razonablemente efectivo para esta fuente, no es tan eficiente como el código establecido por Shannon. Para obtener una visión adicional de la aleatoriedad, se puede abandonar la suposición de que los símbolos sucesivos son independientes permitiendo que cada símbolo dependa de lo que el símbolo anterior o, para el caso, de lo que sucedió con varios de los símbolos anteriores. Más exactamente, la probabilidad de que un símbolo en particular adopte cualquiera de los valores del alfabeto k está condicionada a cuál de estos valores fue asumido por el símbolo o símbolos anteriores. Para una ilustración simple, elija el caso k = 2 donde el alfabeto es sí o no. Suponga que la probabilidad de sí es 1/3 si el bit anterior es sí y 1/4 si el predecesor resultó ser no. Las probabilidades condicionales de obtener no, por el contrario, son 2/3 y 3/4, respectivamente. Esto significa que si la fuente emite el símbolo sí, entonces la probabilidad de obtener un no en el siguiente turno es el doble que la de obtener un sí. Aquí hay una redundancia incorporada debido a la correlación entre bits sucesivos.
con i = 1,…, k. Shannon estableció que existe una codificación de prefijo binario de los k símbolos en la que la longitud promedio de las palabras de código en bits por símbolo es casi igual a la entropía H de la fuente. Como consecuencia de esto, un mensaje de longitud n puede codificarse con aproximadamente nH bits. Considere, por ejemplo, una fuente con cuatro símbolos a, b, c y d que tienen probabilidades 1/2, 1/4, 1/8 y 1/8, respectivamente. La entropía se calcula en 1.75, y si las palabras de código se eligen como 0 para a, 10 para b, 110 para c y 111 para d, entonces esto corresponde a longitudes de palabras de código de 1, 2, 3, 3 cuyo promedio la longitud es 1.75 que, al menos en este caso, es igual a la entropía. En el ejemplo dado en los dos párrafos anteriores, la fuente constaba de los ocho tripletes 000, 001,…, 111 de dígitos binarios independientes en los que la probabilidad de 111, por ejemplo, es 9/10 multiplicado por sí mismo tres veces, o aproximadamente 0.73, con un cálculo similar para todos los demás tripletes. Aunque se diseñó un código razonablemente efectivo para esta fuente, no es tan eficiente como el código establecido por Shannon. Para obtener una visión adicional de la aleatoriedad, se puede abandonar la suposición de que los símbolos sucesivos son independientes permitiendo que cada símbolo dependa de lo que el símbolo anterior o, para el caso, de lo que sucedió con varios de los símbolos anteriores. Más exactamente, la probabilidad de que un símbolo en particular adopte cualquiera de los valores del alfabeto k está condicionada a cuál de estos valores fue asumido por el símbolo o símbolos anteriores. Para una ilustración simple, elija el caso k = 2 donde el alfabeto es sí o no. Suponga que la probabilidad de sí es 1/3 si el bit anterior es sí y 1/4 si el predecesor resultó ser no. Las probabilidades condicionales de obtener no, por el contrario, son 2/3 y 3/4, respectivamente. Esto significa que si la fuente emite el símbolo sí, entonces la probabilidad de obtener un no en el siguiente turno es el doble que la de obtener un sí. Aquí hay una redundancia incorporada debido a la correlación entre bits sucesivos.
Un ejemplo más sorprendente de correlaciones secuenciales son el idioma inglés. El texto en inglés es una concatenación de letras de un alfabeto total de 27 (si se cuentan los espacios) o, desde un punto de vista más liberal, un texto es una cadena de palabras en las que el "alfabeto" ahora es mucho más grande, pero aún finito. , conjunto de palabras posibles. La frecuencia con la que aparecen letras individuales no es uniforme ya que E, por ejemplo, es más probable que Z. Además, las correlaciones seriales son bastante evidentes: TH ocurre a menudo como un par, por ejemplo, y U típicamente sigue a Q. Para analizar una fuente que arroja letras, suponga que cada letra se produce con diferentes frecuencias correspondientes a su aparición real en el idioma inglés. La letra más frecuente es E, y la probabilidad de encontrar E en un texto suficientemente largo es aproximadamente 0.126, lo que significa que su frecuencia de aparición es 0.126, mientras que Z tiene una frecuencia de solo aproximadamente 0.001. La simulación más ingenua del inglés escrito es generar letras según sus frecuencias obtenidas empíricamente, una tras otra, de forma independiente. Se obtiene una mejor aproximación al inglés si las letras no se eligen de forma independiente, pero si se hace que cada letra dependa de las letras anteriores, aunque no de las letras anteriores. La estructura ahora se especifica dando las frecuencias de varios pares de letras, como QU. Esto es lo que Shannon llamó las probabilidades del "digram" de las apariciones. Después de elegir una letra, se elige la siguiente de acuerdo con las frecuencias con las que las distintas letras siguen a la primera. Esto requiere una tabla de frecuencias condicionales. El siguiente nivel de sofisticación involucraría frecuencias de “trigramas” en las que una letra depende de las dos que la preceden.
Generar palabras al azar usando frecuencias de trigramas da lugar a una versión confusa del inglés, pero a medida que avanza con los tetragramas y más allá, una aproximación a la palabra escrita se vuelve cada vez más inteligible. La aproximación más cruda al inglés es generar cada uno de los 27 símbolos de forma independiente con iguales probabilidades 1/2. La entropía media por letra en este caso es log 27 = 4.76. Cuando se alcanza la estructura de tetragrama, la entropía por símbolo se reduce a 4.1, lo que muestra que se ha acumulado una redundancia considerable como resultado de las correlaciones en el lenguaje inducidas por el uso gramatical y los muchos hábitos de estructura de la oración acumulados a lo largo del tiempo. Más refinamientos de estas ideas llevaron a Shannon a creer que la entropía del inglés real es aproximadamente un bit por símbolo. Este alto nivel de redundancia explica por qué uno puede seguir la esencia de una conversación escuchando algunos fragmentos aquí y allá en una habitación ruidosa, aunque algunas palabras o frases enteras se ahogan en el estruendo.
Dado que la redundancia reduce la incertidumbre, se introduce deliberadamente en muchos sistemas de comunicación para reducir el impacto del ruido en la transmisión de mensajes entre el remitente y el destinatario. Esto se logra mediante los llamados códigos de corrección de errores en los que el mensaje, digamos un bloque de dígitos binarios, se reemplaza por una cadena más larga en la que los dígitos adicionales identifican efectivamente cualquier error que pueda haber ocurrido en el bloque original. Para ilustrar esto en la configuración más cruda posible, imagine bloques de mensajes de longitud dos designados como b1b2en los que cada bi es un dígito binario. Sea b3 igual a 0 si el bloque es 00 o 11 y 1 si el bloque es 01 o 10. Ahora transmita el mensaje b1b2b3 que siempre tiene un número par de unos. Si se produce un error en la transmisión en la que se modifica un solo dígito como, por ejemplo, cuando se cambia 011 a 001, el receptor nota que hay un número impar de unos, una clara indicación de un error. Con un refinamiento adicional de este código, uno puede ubicar exactamente en qué posición se produjo el error y, por lo tanto, corregirlo. Los reproductores de discos compactos que escanean discos digitalizados corrigen los errores de las imperfecciones de la superficie empleando una versión más elaborada de la misma idea. Diametralmente opuesto a la corrección de errores es la inserción deliberada de errores en un mensaje para evitar que personas no autorizadas lo entiendan. La protección de los secretos del gobierno, especialmente en tiempos de guerra, es una historia notable que parece un thriller, especialmente en The Codebreakers de David Kahn. Un método seguro de cifrar mensajes para mantener el secreto consiste en codificar cada letra del alfabeto mediante una cadena binaria de cinco dígitos. Los 25 = 32 quintillizos posibles abarcan las 26 letras, así como ciertos marcadores adicionales. Entonces, un mensaje es una cadena binaria larga. Sea v, llamada clave, que designa una cadena binaria aleatoria de la misma longitud que s (v se obtiene en la práctica a partir de un generador "pseudoaleatorio", como se describe en el capítulo siguiente). El número de mensaje cifrado se obtiene a partir de los mensajes de texto simple s sumando la clave va s, dígito a dígito, de acuerdo con la siguiente regla:
0 + 0 = 0
0 + 1 = 1
1 + 0 = 1
1 + 1 = 0
El destinatario de # puede decodificar el mensaje cifrado mediante el mismo procedimiento: simplemente agregue v a # usando la misma regla de adición que la anterior, ¡y esto restaura s! Por ejemplo, si s = 10010 y v = 11011, el número de mensaje transmitido es 01001. El mensaje decodificado se obtiene a partir de 01001 sumando 11011 para obtener 10010, es decir, el texto plano s (ver Fig. 4.9 para una ilustración esquemática de todo el sistema de comunicación). Dado que la clave v es aleatoria y solo la conocen el remitente y el receptor, cualquier espía que intercepte el mensaje confuso no podrá leerlo. Por razones de seguridad, la clave generalmente se usa solo una vez por mensaje en este esquema para evitar que surjan patrones reveladores del análisis de varias intercepciones subrepticias. Existe un equilibrio entre la estructura inherente y los patrones de uso en un idioma como el inglés y la libertad que uno tiene para generar una progresión de palabras que aún se las arreglan para deleite y sorpresa. Un lenguaje completamente ordenado sería predecible y aburrido. En el otro extremo, la salida aleatoria del proverbial mono golpeando un teclado sería un galimatías. El inglés es rico en matices y comprensible al mismo tiempo. En el capítulo 5, esta interacción entre el azar y la necesidad se convierte en una metáfora de la extensión de la cultura humana y la naturaleza en general, en la que la aleatoriedad se verá como un agente esencial de innovación y diversidad.
 14.33.38.png)
Fig. 4.9 Representación esquemática de un esquema de codificación cifrado-descifrador para enviar mensajes de forma segura.
4.4.4 Entropía aproximada
Al final, expusimos la intención de decidir la aleatoriedad de una cadena dada independientemente de su procedencia. Ignoramos cómo llegó a ser la cadena y no nos importa el mecanismo que lo generó, ya sea pura casualidad o algún diseño oculto, es irrelevante, y queremos distanciarnos de la fuente y concentrarnos en la cuerda en sí.
Siguiendo el ejemplo de la discusión anterior, ahora se hará que la cuestión de la aleatoriedad dependa del contenido de información de una secuencia binaria dada. Una herramienta aproximada y lista para evaluar la aleatoriedad en términos de su entropía se llama entropía aproximada (o ApEn, para abreviar).
Supongamos que una secuencia finita está modelada hasta cierto punto en virtud de dependencias secuenciales, como sucede cuando la probabilidad de un cero o uno depende de si está precedida por uno o más ceros o unos. Calculamos el grado de redundancia o, para decirlo de otra manera, el grado de aleatoriedad, calculando una expresión análoga a la entropía que mide la incertidumbre en bits por símbolo. Si la fuente genera símbolos independientes que tienen diferentes probabilidades 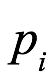 , para i = 1, 2,… m, entonces, como ya ha visto, la entropía viene dada por el expresión H = - la suma de
, para i = 1, 2,… m, entonces, como ya ha visto, la entropía viene dada por el expresión H = - la suma de ![]() . Sin embargo, no conocer la fuente requiere que estas probabilidades se estimen a partir de la secuencia particular que tenemos ante nosotros. La ley de los números grandes nos dice que el
. Sin embargo, no conocer la fuente requiere que estas probabilidades se estimen a partir de la secuencia particular que tenemos ante nosotros. La ley de los números grandes nos dice que el ![]() es aproximadamente igual a la fracción de veces que aparece el símbolo i en la cadena dada. Junto a los digramas, es decir, pares de símbolos consecutivos, una expresión para la "entropía" por pareja se define de la misma manera, excepto que
es aproximadamente igual a la fracción de veces que aparece el símbolo i en la cadena dada. Junto a los digramas, es decir, pares de símbolos consecutivos, una expresión para la "entropía" por pareja se define de la misma manera, excepto que ![]() ahora se refiere a la probabilidad de obtener uno de los posibles digramas
ahora se refiere a la probabilidad de obtener uno de los posibles digramas ![]() (donde m es el número de símbolos y r es el número de digramas formados a partir de estos símbolos); la expresión de H sigue siendo la misma, pero ahora debe sumar en el rango i = 1, 2,… r. Por ejemplo, si m = 3 con un alfabeto que consta de A, B, C, entonces hay 32 = 9 digramas:
(donde m es el número de símbolos y r es el número de digramas formados a partir de estos símbolos); la expresión de H sigue siendo la misma, pero ahora debe sumar en el rango i = 1, 2,… r. Por ejemplo, si m = 3 con un alfabeto que consta de A, B, C, entonces hay 32 = 9 digramas:
AA BA CA
AB BB CB
AC BC CC
Los tripletes de símbolos consecutivos, o trigramas, se manejan de manera análoga, teniendo en cuenta el hecho de que ahora hay m3 posibilidades. El mismo principio se aplica a los k-gramos, bloques de k símbolos, para cualquier k. Lo que me esfuerzo por establecer es que una cadena finita es aleatoria si su "entropía" es lo más grande posible y si los digramas, trigramas, etc., no proporcionan ninguna pista nueva que pueda usarse para reducir el contenido de la información.
Para una cadena dada de longitud finita n, es necesario estimar las probabilidades ![]() para todos los bloques posibles. Como antes, la ley de los números grandes nos asegura que cuando n es suficientemente grande, el valor de
para todos los bloques posibles. Como antes, la ley de los números grandes nos asegura que cuando n es suficientemente grande, el valor de ![]() es aproximadamente igual a la proporción de veces que aparece el i-ésimo bloque de longitud k (los bloques de longitud 1 se refieren a uno de los m símbolos individuales ), donde i varía de 1 a mk. Se puede determinar fácilmente que hay exactamente n + 1 - k bloques de longitud k en la cadena, es decir, los bloques que comienzan en la primera, segunda,…, (n + 1 - k) posición. Por ejemplo, si n = 7 y k = 3, los bloques de longitud k en la cadena “ENTROPY” son ENT, NTR, TRO, ROP y OPY, y hay n + 1 - k = 7 + 1-3 = 5 de ellos. Sea
es aproximadamente igual a la proporción de veces que aparece el i-ésimo bloque de longitud k (los bloques de longitud 1 se refieren a uno de los m símbolos individuales ), donde i varía de 1 a mk. Se puede determinar fácilmente que hay exactamente n + 1 - k bloques de longitud k en la cadena, es decir, los bloques que comienzan en la primera, segunda,…, (n + 1 - k) posición. Por ejemplo, si n = 7 y k = 3, los bloques de longitud k en la cadena “ENTROPY” son ENT, NTR, TRO, ROP y OPY, y hay n + 1 - k = 7 + 1-3 = 5 de ellos. Sea ![]() el número de veces que ocurre el i-ésimo tipo de bloque entre los n + 1 - k k-gramos sucesivos en la cadena. Entonces, la probabilidad pi del i-ésimo bloque se estima como la frecuencia
el número de veces que ocurre el i-ésimo tipo de bloque entre los n + 1 - k k-gramos sucesivos en la cadena. Entonces, la probabilidad pi del i-ésimo bloque se estima como la frecuencia ![]() en la que acordamos escribir (n + 1 - k) simplemente como N. Por ejemplo, la cadena
en la que acordamos escribir (n + 1 - k) simplemente como N. Por ejemplo, la cadena
CAAABBCBABBCABAACBACC
tiene una longitud n = 21 y m es igual a 3. Hay m2 = 9 posibles digramas y, como k=2, estos se encuentran entre los N = 20 bloques consecutivos de longitud 2 en la cadena. Uno de los 9 digramas imaginables es AB, y esto ocurre tres veces, por lo que la probabilidad de este bloque en particular es 3/20. No es difícil ver que ni debe sumar N ya que i varía de 1 a mk. Entonces se obtiene la siguiente expresión aproximada para la "entropía" H (k) por bloque de tamaño k:
![]()
donde el índice i va de 1 a mk; H(1) es idéntica a la expresión habitual para H. Sin embargo, debe tener en cuenta que la "entropía" es un abuso del lenguaje aquí, ya que la entropía, como se definió anteriormente para H, se aplica a un alfabeto de símbolos elegidos independientemente, mientras que los bloques el tamaño k puede estar correlacionado debido a dependencias secuenciales. Además, la entropía asume que hay alguna fuente generadora específica, mientras que ahora solo hay una sola cadena de alguna fuente desconocida, y todo lo que podemos hacer es estimar la fuente a partir de las probabilidades estimadas aproximadamente. Ahora puedo introducir la noción clave de entropía aproximada ApEn (k) como la diferencia H (k) - H (k - 1), siendo ApEn (1) simplemente H(1). La idea aquí es que queremos estimar la "entropía" de un bloque de longitud k condicionada a conocer su prefijo de longitud k - 1. Esto da la nueva información aportada por el último miembro de un bloque dado que conocemos sus predecesores dentro el bloque. Si la cadena es muy redundante, se espera que el conocimiento de un bloque dado ya determine en gran medida el símbolo siguiente, por lo que se acumula muy poca información nueva. En esta situación, la diferencia ApEn será pequeña. Esto se puede ilustrar esquemáticamente para los digramas en la figura 4.9, en la que los óvalos representan la entropía promedio de un par de símbolos superpuestos (secuencialmente dependientes) en un caso y símbolos separados (independientes) en el otro. Los óvalos individuales tienen "entropías" H(1), mientras que su unión tiene "entropía" H(2).
 14.46.23.png)
Fig. 4.9 Representación esquemática de dos símbolos sucesivos que son secuencialmente independientes (a) y dependientes (b). El grado de superposición indica el grado de dependencia secuencial. Sin superposición significa independencia. La "entropía" promedio por disco (lea: símbolo) es H(1), y la "entropía" promedio del digram es H(2), mientras que el área sombreada representa la información aportada por el segundo miembro del digram, que no está ya contenido en su predecesor, condicionado a conocer el primer miembro del par, es decir, H (2) - H (1) = ApEn (2).
El área sombreada en el diagrama (a) representa la nueva información aportada por el segundo miembro del digram que aún no está contenida en su predecesor. Esta es la entropía aproximada ApEn (2) del digram, condicionada a conocer el primer miembro del par. El área sombreada en el diagrama (b), y por lo tanto la incertidumbre, es máxima siempre que los óvalos no se superponen. Otra forma de ver por qué ApEn (2) está cerca de cero cuando el segundo dígito de un par de digramas está completamente determinado por el anterior es que hay aproximadamente tantos digramas distintos en esta situación como dígitos distintos y, por lo tanto, H(1) y H(2) son aproximadamente iguales; de ahí que su diferencia sea cercana a cero. Por el contrario, si una cadena de longitud n es aleatoria, entonces H(1) = log n y H(2) = log n2 = 2 log n, ya que hay n2 digramas igualmente probables; por lo tanto, ApEn (2) = 2 log n - log n = log n, que es igual a ApEn (1).
4.4.5 De nuevo, ¿es aleatorio?
En el caso de cadenas que no sean demasiado largas, suele ser suficiente comprobar ApEn (k) para que k no exceda de 3 para tener una idea del grado de redundancia. Hay un algoritmo simple para calcular ApEn para cadenas binarias, y lo ilustraremos aquí para tres secuencias diferentes de longitud 24 con k igual a 1 y 2. El primero repite el motivo de 01, por lo que el los patrones 00 y 11 nunca aparecen. La segunda secuencia es de Bernoulli 1/2: ensayos en los que se espera cierta redundancia debido a largos bloques de ceros consecutivos. La última secuencia es de los ensayos de Bernoulli 1/2, y aquí uno puede anticipar algo más cercano a la máxima "entropía". Dado que estas cadenas progresan de ordenadas a codificadas, los valores de ApEn deberían reflejar esto aumentando, y esto es precisamente lo que sucede. Aunque pasemos para conocer la procedencia de cada serie, podrían habernos aparecido sin previo aviso, por lo que al menos es concebible que cada una pudiera haber surgido de un proceso totalmente ordenado o, quizás, irremediablemente enredado. No sabemos cuál. Las secuencias de dígitos se toman como son, al natural, sin prejuicios en cuanto a la fuente, y nos preguntamos hasta qué punto la máscara que nos presentan imita el rostro de la aleatoriedad. La entropía aproximada se maximiza siempre que cualquiera de los k bloques de dígitos de longitud aparezca con la misma frecuencia, que es el requisito de firma de un número normal como se presentó en el capítulo anterior.
Ahora está claro que para que una secuencia binaria ilimitada califique como aleatoria, debe ser un número normal. De lo contrario, algunos bloques ocurren con más frecuencia que otros y, como en el caso de los procesos p de Bernoulli en los que p difiere de 1/2, la distribución desigual de bloques da como resultado redundancias que pueden ser explotadas por una codificación más eficiente. En particular, una secuencia aleatoria tiene la propiedad de que las frecuencias límite de ceros y unos son las mismas. Sin embargo, debo advertir que cuando observa una cadena de longitud finita, no hay forma de saber con certeza si este fragmento proviene de un proceso aleatorio o no. La cadena finita se considera simplemente en sus propios términos. Por el contrario, los procedimientos estadísticos probaron la hipótesis nula de que la cadena se genera aleatoriamente, es decir, que proviene de ensayos de Bernoulli 1/2, pero un elemento ineluctable de incertidumbre permanece incluso si la hipótesis nula no se rechaza ya que todo eso fue capaz de verificar es la frecuencia de bloques de longitud uno. Volviendo a los ejemplos, deje que la primera cadena consista en 01 repetida 12 veces. Los valores calculados de ApEn(1) y ApEn (2) son 1.000 y .001, respectivamente. Como hay exactamente el mismo número de unos y ceros, ApEn (1) toma el valor máximo de log 2 = 1, pero ApEn(2) es casi cero porque el segundo dígito de cualquier digram está completamente determinado por el primero, y no hay sorpresas. La siguiente cadena es
00010001000010000010 010 0
y encontramos que ApEn(1) = .738 y ApEn(2) =.684. Hay muchos más ceros que unos, lo que explica por qué ApEn(1) es menor que la entropía máxima teórica de 1 que habría prevalecido si estos dígitos estuvieran distribuidos por igual en frecuencia. Además, el valor de ApEn(2) indica que el segundo miembro de cada digram está determinado sólo parcialmente por su predecesor. El cero suele seguir a un 0, pero a veces hay una sorpresa; por otro lado, 0 siempre sigue a 1.
El tercer ejemplo, de Bernoulli 1 2 -trials, es
11110 0100010111010110 010
y aquí ApEn(1) = .9950, mientras que ApEn(2) = .9777, ambos cercanos a la entropía máxima de 1. En este ejemplo, las proporciones de unos y ceros están más equilibradas que en el ejemplo anterior, y este es también el caso de cada uno de los digramas 00, 01, 10 y 11.
Para propósitos de comparación, reconsideremos la cadena cuya aleatoriedad fue rechazada usando el teorema de De Moivre. La cadena constaba de 25 dígitos
1110110001101111111011110
La aplicación de ApEn a esta secuencia da ApEn(1) = .8555 y ApEn(2) = .7406, dejando nuevamente cuestionable la hipótesis nula de aleatoriedad. Vale la pena señalar que aunque la cadena con patrón de repetidos 01 engañó a de Moivre, ApEn proporciona una prueba más estricta ya que ApEn(2) es casi cero, como vio (en realidad, el ejemplo tenía 25 dígitos en lugar de 24, pero la conclusión sigue siendo la misma). Es justo agregar que la prueba de entropía de aleatoriedad puede requerir la aplicación de ApEn para valores más altos de k con el fin de detectar cualquier regularidad latente. Por ejemplo, una secuencia en la que 0011 se repite seis veces tiene la propiedad de que 0 y 1 y 00, 01, 10 y 11 aparecen todos con la misma frecuencia y, por lo tanto, engaña a ApEn (k) en un juicio prematuro de aleatoriedad si k es limitado a uno o dos. Requiere ApEn(3) para descubrir el patrón. De hecho, ApEn(1) es 1.000, ApEn(2) es .9958, ¡pero ApEn(3) es igual a .0018! Como nota a pie de página, vale la pena señalar que aunque un número aleatorio debe ser normal, no todos los números normales son necesariamente aleatorios. El ejemplo de Champernowne se genera mediante un procedimiento simple de escribir 0 y 1 seguido de todos los pares 00 01 10 11, seguido de todos los tripletes 000001 etc., y esto puede ser codificado por una cadena finita que proporciona las instrucciones para llevar a cabo los pasos sucesivos. Esto se aclarará, pero por ahora basta con afirmar que un tramo suficientemente largo de este número normal no puede ser aleatorio precisamente porque puede codificarse con una cadena más corta.
4.4.6 La percepción de la aleatoriedad
En la discusión anterior, mencionamos que los psicólogos han llegado a la conclusión de que las personas generalmente perciben una secuencia binaria como aleatoria si hay más alteraciones entre ceros y unos de las que justifica el azar solo. Las secuencias producidas por un proceso de Bernoulli 1/2, por ejemplo, ocasionalmente exhiben carreras largas que van en contra de la intuición común de que el azar corregirá el desequilibrio mediante inversiones más frecuentes.
Los psicólogos Ruma Falk y Clifford Konold dieron un nuevo giro a estas observaciones en un estudio que realizaron recientemente. Se pidió a varios participantes que evaluaran la aleatoriedad de las secuencias binarias que se les presentaron, ya sea mediante una inspección visual o al poder reproducir la cadena de memoria. Se encontró que la percepción de aleatoriedad estaba relacionada con el grado de dificultad que experimentaban los sujetos al intentar dar sentido a la secuencia. Para citar a los autores, “juzgar el grado de aleatoriedad se basa en un acto encubierto de codificar la secuencia. La percepción de la aleatoriedad puede, por esta razón, ser una consecuencia de una falla en la codificación ”y, en otros lugares,“ los participantes evalúan tácitamente la dificultad de codificación de las secuencias para juzgar su aleatoriedad ”. De las dos secuencias
1 1 1 1 1 1 0 0 0 1 1 0 0 0 0 0 0 0 1 1 1
,
1 1 0 1 0 1 0 1 0 1 0 0 0 1 1 0 1 0 1 0 1
el segundo, con su exceso de alternancias, se percibe como más aleatorio, aunque cada cadena se aparta por igual del número de corridas que se esperaría que tuviera una cadena verdaderamente aleatoria. Simplemente, es más difícil reproducir el segundo de memoria.
Los resultados experimentales no son incompatibles con la idea de que un valor bajo de ApEn traiciona una secuencia modelada cuyas redundancias secuenciales pueden explotarse favorablemente empleando un código adecuado. En realidad, los sujetos mostraron un sesgo sistemático a favor de percibir aleatoriedad en cadenas con una prevalencia de alteraciones moderadamente superior a la que indicaría el valor máximo de ApEn.
Falk y Konold concluyen su artículo con un comentario sobre “la interconexión de ver la estructura subyacente (es decir, eliminar la aleatoriedad) y dar con una codificación eficiente. Aprender un idioma extranjero es un ejemplo de ello; formar una hipótesis científica es a menudo otra... una vez que se ha reconocido un patrón, la descripción del mismo fenómeno se puede condensar considerablemente ". En una línea similar, los psicólogos Daniel Kahneman y Amos Tversky argumentan que "las secuencias que aparecen al azar son aquellas cuyas descripciones verbales son más largas". Estas afirmaciones se hacen eco de los sentimientos de Laplace, sentimientos que resuenan con fuerza en el resto de la discusión. En particular, la complejidad de una cadena como una indicación de lo difícil que es codificar finalmente se reformulará como una medida precisa de aleatoriedad. Para resumir, la idea de entropía se introdujo como una medida de incertidumbre en una cadena de mensajes, y vimos que cualquier falta de aleatoriedad puede ser aprovechada por un esquema de codificación que elimina parte de la redundancia. Pero la historia está lejos de estar completa. La entropía y la información reaparecerán para ayudar a proporcionar información adicional sobre la pregunta "¿qué es aleatorio?"
4.5 Aleatoriedad
Ese es el efecto de vivir al revés, dijo la Reina amablemente: siempre te da un poco de vértigo al principio ... pero tiene una gran ventaja: la memoria de uno funciona en ambos sentidos. El otro mensajero se llama Hatta. Debo tener dos, ya sabes, para ir y venir. Uno para venir y otro para ir... ¿No te lo digo? repitió el rey con impaciencia. Debo tener dos para ir a buscar y llevar. Uno para buscar y otro para llevar de a través del espejo de Lewis Carroll.
4.5.1 ¿Es el determinismo una ilusión?
El estadístico M. Bartlett ha introducido un procedimiento simple paso a paso para generar una secuencia aleatoria que es tan curioso que nos obliga a examinarlo con cuidado, ya que nos llevará al núcleo mismo de lo que hace que la aleatoriedad parezca esquiva. Cualquier procedimiento paso a paso que implique un conjunto preciso de instrucciones sobre qué hacer a continuación se denomina algoritmo. El algoritmo de Bartlett produce números uno tras otro utilizando la misma instrucción básica y, por esta razón, también se conoce como iteración. Comienza con un número "semilla" ![]() entre cero y uno y luego genera una secuencia de números un, para n = 1, 2,…, por la regla de que un es el valor anterior un
entre cero y uno y luego genera una secuencia de números un, para n = 1, 2,…, por la regla de que un es el valor anterior un ![]() más un dígito binario aleatorio
más un dígito binario aleatorio ![]() obtenido de Bernoulli 1/2-ensayos, la suma dividida por dos; los valores sucesivos de bn son independientes e idénticamente distribuidos como 0 y 1. Dicho de otra manera, un puede tomar uno de los dos valores posibles un
obtenido de Bernoulli 1/2-ensayos, la suma dividida por dos; los valores sucesivos de bn son independientes e idénticamente distribuidos como 0 y 1. Dicho de otra manera, un puede tomar uno de los dos valores posibles un ![]() o
o ![]() , cada uno igualmente probable.
, cada uno igualmente probable.
La conexión entre dos valores sucesivos de un ![]() se ilustra en la figura 4.10, en la que el eje horizontal muestra los valores de un
se ilustra en la figura 4.10, en la que el eje horizontal muestra los valores de un ![]() y el eje vertical da los dos valores posibles del sucesor iterar
y el eje vertical da los dos valores posibles del sucesor iterar ![]() .
.
 14.45.23.png)
Fig. 4.10 Valores sucesivos ![]() ) del algoritmo de Bartlett para 200 iteraciones. Para cada valor de
) del algoritmo de Bartlett para 200 iteraciones. Para cada valor de ![]() , hay dos valores posibles de un, cada uno equiprobable.
, hay dos valores posibles de un, cada uno equiprobable.
Para avanzar más en esta secuencia y revelar su estructura esencial, es conveniente, de hecho necesario, representar los números sucesivos mediante una cadena binaria. Cualquier número x entre cero y uno se puede representar como una suma infinita:
![]()
en el que los coeficientes a1, a2, a3,… pueden ser cero o uno. Por qué esto es así es una cuestión del concepto de sucesión numérica, pero por ahora es suficiente con dar algunos ejemplos. El número 11/16, por ejemplo, se puede expresar como la suma finita 1/2+ 1/8+ 1/16, mientras que el número 5/6 es una suma interminable 1/2+ 1/4 +1/16 +1/64 + 1/256+… Los coeficientes a1, a2, ... en la suma infinita se pueden encadenar para formar una secuencia binaria, y esta es la representación que estamos buscando. En el caso de 11/16, la secuencia binaria se representa como 1011000 ... con todos los dígitos restantes siendo 0 (ya que a1 = 1, a2 = 0, a3 = 1, a4 = 1, y así sucesivamente), mientras que 5/6 se representa como 11010101…, en el que el patrón 01 se repite indefinidamente. De la misma manera, cualquier número x en el intervalo unitario (es decir, los números entre cero y uno) se puede representar como una secuencia binaria a1a2a3…; esto se aplica, en particular, al valor inicial ![]() . El truco ahora es ver cómo se obtiene la primera iteración u1 del algoritmo de Bartlett a partir de
. El truco ahora es ver cómo se obtiene la primera iteración u1 del algoritmo de Bartlett a partir de ![]() en términos de la representación binaria. La respuesta es que la secuencia a1a2… se desplaza un lugar a la derecha y se agrega un dígito b1 a la izquierda. En efecto,
en términos de la representación binaria. La respuesta es que la secuencia a1a2… se desplaza un lugar a la derecha y se agrega un dígito b1 a la izquierda. En efecto, ![]() está representado por b1a1a2a3… y, al desplazar la secuencia a la derecha n lugares y agregar dígitos aleatorios a la izquierda, la enésima iteración se expresa como bnbn−1… b1a1a2a3…. Un ejemplo simple muestra cómo funciona esto: elija el número de semilla inicial
está representado por b1a1a2a3… y, al desplazar la secuencia a la derecha n lugares y agregar dígitos aleatorios a la izquierda, la enésima iteración se expresa como bnbn−1… b1a1a2a3…. Un ejemplo simple muestra cómo funciona esto: elija el número de semilla inicial![]() para que sea 1/4, y suponga que los dígitos aleatorios b1 y b2 son, respectivamente, 0 y 1. Entonces
para que sea 1/4, y suponga que los dígitos aleatorios b1 y b2 son, respectivamente, 0 y 1. Entonces ![]() y
y ![]() . Las representaciones binarias de u0, u1 y u2 ahora resultan ser 01000…, 001000… y 1001000… de acuerdo con lo que se acaba de describir.
. Las representaciones binarias de u0, u1 y u2 ahora resultan ser 01000…, 001000… y 1001000… de acuerdo con lo que se acaba de describir.
El ingenioso esquema de reemplazar las iteraciones de ![]() por la acción más fácil y transparente de cambiar la secuencia binaria que representa
por la acción más fácil y transparente de cambiar la secuencia binaria que representa ![]() se conoce como dinámica simbólica. La figura 4.11 es una representación esquemática. En este punto deberíamos hacer una pausa y notar un hecho muy curioso: la secuencia generada aleatoriamente de Bartlett es un conjunto de números que, cuando se ve al revés, se revela como un proceso determinista. Lo que quiero decir es que si comienzas con el último valor conocido de
se conoce como dinámica simbólica. La figura 4.11 es una representación esquemática. En este punto deberíamos hacer una pausa y notar un hecho muy curioso: la secuencia generada aleatoriamente de Bartlett es un conjunto de números que, cuando se ve al revés, se revela como un proceso determinista. Lo que quiero decir es que si comienzas con el último valor conocido de ![]() y calcula
y calcula ![]() en términos de
en términos de ![]() y luego
y luego ![]() en términos de
en términos de ![]() y así sucesivamente, hay una manera inequívoca de describir cómo los pasos de La iteración de Bartlett se puede rastrear hacia atrás. Las iteraciones en reversa se obtienen desplazando la secuencia binaria que representa
y así sucesivamente, hay una manera inequívoca de describir cómo los pasos de La iteración de Bartlett se puede rastrear hacia atrás. Las iteraciones en reversa se obtienen desplazando la secuencia binaria que representa ![]() un paso a la izquierda y truncando el dígito más a la izquierda: la secuencia
un paso a la izquierda y truncando el dígito más a la izquierda: la secuencia ![]() por lo tanto se convierte en bn
por lo tanto se convierte en bn ![]() esto es mostrado esquemáticamente en la Fig. 4.12.
esto es mostrado esquemáticamente en la Fig. 4.12.
 14.49.56.png)
Fig. 4.11 Representación del algoritmo de Bartlett usando dinámica simbólica: la iteración de ![]() a
a ![]() equivale a un desplazamiento de la secuencia binaria
equivale a un desplazamiento de la secuencia binaria ![]() a la derecha y luego sumar el dígito
a la derecha y luego sumar el dígito ![]() a la derecha y luego sumar el dígito
a la derecha y luego sumar el dígito ![]() a la izquierda.
a la izquierda.
 14.53.00.png)
Fig. 4.12 Representación de la inversa del algoritmo de Bartlett usando dinámica simbólica: la iteración de ![]() a
a ![]() equivale a un desplazamiento de la secuencia binaria
equivale a un desplazamiento de la secuencia binaria ![]() a la izquierda y luego borrar el dígito más a la izquierda.
a la izquierda y luego borrar el dígito más a la izquierda.
Esta operación de desplazamiento no implica la creación de dígitos aleatorios como lo hace en la iteración de Bartlett, sino que simplemente elimina los dígitos existentes, y este es un procedimiento perfectamente mecánico. Ahora podemos retroceder un momento para ver a qué equivale realmente esta operación inversa. Elija un nuevo número de semilla ![]() en el intervalo unitario y ahora genere una secuencia
en el intervalo unitario y ahora genere una secuencia ![]() para
para ![]() mediante la regla iterativa de que
mediante la regla iterativa de que ![]() es la parte fraccionaria de dos veces
es la parte fraccionaria de dos veces ![]() . Tomar la parte fraccionaria de un número a menudo se expresa escribiendo “mod 1”, por lo que
. Tomar la parte fraccionaria de un número a menudo se expresa escribiendo “mod 1”, por lo que ![]() también se puede escribir como
también se puede escribir como ![]() . Por ejemplo, si
. Por ejemplo, si ![]() es igual a 7/8, entonces
es igual a 7/8, entonces ![]() se obtiene duplicando 7/8, lo que da 14/8, y tomando la parte fraccionaria, es decir, 3/4. Ahora suponga que
se obtiene duplicando 7/8, lo que da 14/8, y tomando la parte fraccionaria, es decir, 3/4. Ahora suponga que ![]() tiene, como lo hizo
tiene, como lo hizo ![]() antes, una representación binaria infinita q1q2q3…. Resulta que la acción de obtener
antes, una representación binaria infinita q1q2q3…. Resulta que la acción de obtener ![]() de su predecesor se representa simbólicamente cortando el dígito más a la izquierda y luego desplazando la secuencia binaria hacia la izquierda: q1q2q3… se convierte en q2q3q4… Esto se ilustra con la secuencia de tres iteraciones de Bartlett dada anteriormente, a saber, 1/4, 1/8 y 9/16. Comenzando con 9/16 como el valor
de su predecesor se representa simbólicamente cortando el dígito más a la izquierda y luego desplazando la secuencia binaria hacia la izquierda: q1q2q3… se convierte en q2q3q4… Esto se ilustra con la secuencia de tres iteraciones de Bartlett dada anteriormente, a saber, 1/4, 1/8 y 9/16. Comenzando con 9/16 como el valor ![]() y trabajando hacia atrás con la regla “mod 1”, obtienes
y trabajando hacia atrás con la regla “mod 1”, obtienes ![]() y
y ![]() . En términos de representaciones binarias, la secuencia de iteraciones es 1001000…, 001000… y 01000….
. En términos de representaciones binarias, la secuencia de iteraciones es 1001000…, 001000… y 01000….
 14.58.10.png)
Fig. 4.13 Valores sucesivos ![]() del algoritmo de Bartlett inverso, es decir, el algoritmo mod 1, para 200 iteraciones. Para cada valor de
del algoritmo de Bartlett inverso, es decir, el algoritmo mod 1, para 200 iteraciones. Para cada valor de ![]() , hay un valor único de
, hay un valor único de ![]() , una relación determinista.
, una relación determinista.
Ahora es evidente que la iteración mod 1 es idéntica en forma a la inversa de la iteración de Bartlett y nuevamente puede determinar que esta inversa es determinista, ya que calcula iteraciones mediante una regla precisa e inequívoca. La figura 4.13 traza la relación de ![]() con
con ![]() , y al inclinar la cabeza, queda claro que esta imagen es la misma que la de la figura 4.10 vista al revés. Todo lo que necesita hacer es volver a etiquetar
, y al inclinar la cabeza, queda claro que esta imagen es la misma que la de la figura 4.10 vista al revés. Todo lo que necesita hacer es volver a etiquetar ![]() ,
, ![]() como
como ![]() , un en ese orden, como se muestra en la figura 4.14. Así que ahora tenemos la siguiente situación: siempre que Bartlett genera aleatoriamente una cadena binaria
, un en ese orden, como se muestra en la figura 4.14. Así que ahora tenemos la siguiente situación: siempre que Bartlett genera aleatoriamente una cadena binaria ![]() , el algoritmo mod 1 invierte esto borrando determinísticamente un dígito para obtener la secuencia
, el algoritmo mod 1 invierte esto borrando determinísticamente un dígito para obtener la secuencia ![]()
 15.02.27.png)
Figura 4.14 El par ![]() de la figura 4.13 corresponde al par
de la figura 4.13 corresponde al par ![]() del algoritmo de Bartlett (figura 4.10), cuyas iteraciones constituyen la secuencia de Janus. Las iteraciones definidas por el algoritmo de Bartlett inverso, es decir, el algoritmo mod 1, definen la secuencia de Janus inversa
del algoritmo de Bartlett (figura 4.10), cuyas iteraciones constituyen la secuencia de Janus. Las iteraciones definidas por el algoritmo de Bartlett inverso, es decir, el algoritmo mod 1, definen la secuencia de Janus inversa
En efecto, el futuro se desarrolla a través de Bartlett esperando que cada nuevo cero o un evento ocurra al azar, mientras que el inverso olvida el presente y vuelve sobre sus pasos. El futuro incierto y un conocimiento claro del pasado son dos caras de la misma moneda. Es por eso que llamamos a las iteraciones de Bartlett una secuencia de Jano, nombrada en honor a la divinidad romana que fue representada en monedas con dos cabezas mirando en direcciones opuestas, mirando hacia el futuro y explorando el pasado a la vez. Aunque esta secuencia con el rostro de Jano parece ser una mezcla de aleatoriedad y determinismo, un escrutinio más cuidadoso revela que lo que se presenta como orden es en realidad un desorden disfrazado. De hecho, la cadena a la inversa genera lo que se conoce como caos determinista en el que cualquier incertidumbre en las condiciones iniciales se traduce inevitablemente en una eventual aleatoriedad. Para ver esto, volvamos a la forma en que el mod 1 itera desplaza una secuencia binaria q1q2… hacia la izquierda. Si la cadena q1q2… correspondiente a la condición inicial ![]() se conoce en su totalidad, entonces no hay incertidumbre sobre el número obtenido después de cada turno; es el número que se disfraza como la secuencia q2q3…. El problema surge de lo que se llama granulado grueso, es decir, cuando
se conoce en su totalidad, entonces no hay incertidumbre sobre el número obtenido después de cada turno; es el número que se disfraza como la secuencia q2q3…. El problema surge de lo que se llama granulado grueso, es decir, cuando ![]() se conoce solo con precisión limitada como una cadena finita q1… qn. La razón es que todas las cadenas binarias infinitas se pueden considerar como salidas de un interminable ensayo de Bernoulli 1/2 y, por lo tanto, si
se conoce solo con precisión limitada como una cadena finita q1… qn. La razón es que todas las cadenas binarias infinitas se pueden considerar como salidas de un interminable ensayo de Bernoulli 1/2 y, por lo tanto, si ![]() se conoce solo con la precisión finita q1 ... qn, los dígitos restantes de la secuencia comprenden los restos indeterminados de los ensayos de Bernoulli 1/2. Después de n iteraciones, los primeros n dígitos se han truncado, y la cadena ahora se ve como
se conoce solo con la precisión finita q1 ... qn, los dígitos restantes de la secuencia comprenden los restos indeterminados de los ensayos de Bernoulli 1/2. Después de n iteraciones, los primeros n dígitos se han truncado, y la cadena ahora se ve como ![]() , y esto consiste en una secuencia de ceros y unos de los que todo lo que sabemos es que son independientes e igualmente probables; de aquí en adelante, las iteraciones del mod 1 son impredecibles. Si
, y esto consiste en una secuencia de ceros y unos de los que todo lo que sabemos es que son independientes e igualmente probables; de aquí en adelante, las iteraciones del mod 1 son impredecibles. Si ![]() es cero, entonces la n + 1 iteración es un número en
es cero, entonces la n + 1 iteración es un número en ![]() , mientras que si
, mientras que si ![]() es igual a uno, esto le dice que la iteración se encuentra en algún lugar dentro de
es igual a uno, esto le dice que la iteración se encuentra en algún lugar dentro de ![]() ; cada evento tiene la misma probabilidad de ocurrir.
; cada evento tiene la misma probabilidad de ocurrir.
El comportamiento aparentemente determinista de las iteraciones de Janus inversas (iteración mod 1) está evidentemente comprometido a menos que uno conozca el valor presente ![]() exactamente como una secuencia infinita q1q2…. Además, un cambio sutil en las condiciones iniciales, un simple cambio de 0 a 1 en uno de los dígitos, puede resultar en una secuencia totalmente diferente de iteraciones. Los teóricos dinámicos llaman al algoritmo mod 1, es decir, el reverso de Janus, caótico debido a esta sensibilidad a las condiciones iniciales: un pequeño cambio se magnifica por iteraciones sucesivas en imprevisibilidad; la ignorancia ahora genera aleatoriedad más tarde.
exactamente como una secuencia infinita q1q2…. Además, un cambio sutil en las condiciones iniciales, un simple cambio de 0 a 1 en uno de los dígitos, puede resultar en una secuencia totalmente diferente de iteraciones. Los teóricos dinámicos llaman al algoritmo mod 1, es decir, el reverso de Janus, caótico debido a esta sensibilidad a las condiciones iniciales: un pequeño cambio se magnifica por iteraciones sucesivas en imprevisibilidad; la ignorancia ahora genera aleatoriedad más tarde.
Se puede producir una secuencia aleatoria de iteraciones ![]() ,
, ![]() , usando el algoritmo mod 1 directamente. Comenzando con un
, usando el algoritmo mod 1 directamente. Comenzando con un ![]() cuya expansión binaria corresponde a alguna secuencia de Bernoulli aleatoria, establezca
cuya expansión binaria corresponde a alguna secuencia de Bernoulli aleatoria, establezca ![]() en 0 si la enésima iteración es un número en
en 0 si la enésima iteración es un número en ![]() , y póngalo igual a 1 si el número está dentro de
, y póngalo igual a 1 si el número está dentro de ![]() . Una pequeña reflexión muestra que aunque los valores sucesivos de
. Una pequeña reflexión muestra que aunque los valores sucesivos de ![]() se generan mediante un procedimiento puramente mecánico, son idénticos a los dígitos
se generan mediante un procedimiento puramente mecánico, son idénticos a los dígitos ![]() dados anteriormente. Por tanto, las iteraciones definen un proceso aleatorio. Esta es una revelación sorprendente porque sugiere que el determinismo es una ilusión. ¿Que esta pasando aqui?
dados anteriormente. Por tanto, las iteraciones definen un proceso aleatorio. Esta es una revelación sorprendente porque sugiere que el determinismo es una ilusión. ¿Que esta pasando aqui?
La solución a la aparente paradoja ya se ha dado: si ![]() se conoce completamente en el sentido de conocer todos sus dígitos binarios
se conoce completamente en el sentido de conocer todos sus dígitos binarios ![]() , entonces el proceso "aleatorio" generado por el algoritmo mod 1 colapsa en una enumeración inútil de una oferta interminable y predestinada. de ceros y unos, y se conserva el determinismo. El problema, como dije antes, es poseer verdaderamente los dígitos de la representación binaria de
, entonces el proceso "aleatorio" generado por el algoritmo mod 1 colapsa en una enumeración inútil de una oferta interminable y predestinada. de ceros y unos, y se conserva el determinismo. El problema, como dije antes, es poseer verdaderamente los dígitos de la representación binaria de ![]() en su totalidad y, en la práctica, esto se nos escapa; la maldición del granulado grueso es que la aleatoriedad no puede evitarse si
en su totalidad y, en la práctica, esto se nos escapa; la maldición del granulado grueso es que la aleatoriedad no puede evitarse si ![]() se conoce imperfectamente. Sin embargo, en una nota más positiva, pueden ser necesarias muchas iteraciones antes de que la imprevisibilidad se manifieste, lo suficiente como para proporcionar una apariencia temporal de orden.
se conoce imperfectamente. Sin embargo, en una nota más positiva, pueden ser necesarias muchas iteraciones antes de que la imprevisibilidad se manifieste, lo suficiente como para proporcionar una apariencia temporal de orden.
4.5.2 Generación de aleatoriedad
La naturaleza determinista de mod 1 se desenmascara de otras formas, la más convincente de las cuales es la trama de la figura 4.13, que muestra que iteraciones sucesivas se suceden en un patrón ordenado, una consecuencia del hecho de que ![]() depende de
depende de ![]() . Por el contrario, los valores sucesivos de una secuencia aleatoria no están correlacionados y aparecen como una nube de puntos que se dispersan al azar. Se pueden obtener utilizando lo que se conoce como un generador de números aleatorios que se incluye hoy en día con muchos paquetes de software destinados a computadoras personales. Proporcionan números "aleatorios" mediante un algoritmo no muy diferente en principio del empleado por el procedimiento mod 1: se proporciona una semilla inicial como un entero x0, y luego los enteros
. Por el contrario, los valores sucesivos de una secuencia aleatoria no están correlacionados y aparecen como una nube de puntos que se dispersan al azar. Se pueden obtener utilizando lo que se conoce como un generador de números aleatorios que se incluye hoy en día con muchos paquetes de software destinados a computadoras personales. Proporcionan números "aleatorios" mediante un algoritmo no muy diferente en principio del empleado por el procedimiento mod 1: se proporciona una semilla inicial como un entero x0, y luego los enteros ![]() para
para ![]() son producidos por un esquema iterativo determinista en el que el entero actualizado se toma mod m. Dado que los enteros generados no exceden de m, es bastante evidente que como máximo m pueden producirse valores enteros distintos de
son producidos por un esquema iterativo determinista en el que el entero actualizado se toma mod m. Dado que los enteros generados no exceden de m, es bastante evidente que como máximo m pueden producirse valores enteros distintos de ![]() y, por lo tanto, eventualmente, las iteraciones deben volver a algún número anterior. A partir de aquí, el procedimiento se repite. Cada iteración entera
y, por lo tanto, eventualmente, las iteraciones deben volver a algún número anterior. A partir de aquí, el procedimiento se repite. Cada iteración entera ![]() producida por el generador de números aleatorios se convierte en una fracción dentro del intervalo unitario dividiendo
producida por el generador de números aleatorios se convierte en una fracción dentro del intervalo unitario dividiendo ![]() por m. Los números
por m. Los números ![]() , que se encuentran entre 0 y 1, están representados por cadenas binarias de longitud finita, y pueden considerarse como truncamientos de una cadena infinita cuyos dígitos restantes se desconocen. Este granulado grueso, una deficiencia necesaria del espacio limitado de la memoria de la computadora, es lo que le da al algoritmo su naturaleza cíclica, ya que está obligado a volver a un valor anterior tarde o temprano. La idea es obtener un suministro de dígitos que no se repita sobre sí mismos durante mucho tiempo y, como mínimo, esto requiere que m sea lo suficientemente grande. En muchas versiones del algoritmo, m se establece en
, que se encuentran entre 0 y 1, están representados por cadenas binarias de longitud finita, y pueden considerarse como truncamientos de una cadena infinita cuyos dígitos restantes se desconocen. Este granulado grueso, una deficiencia necesaria del espacio limitado de la memoria de la computadora, es lo que le da al algoritmo su naturaleza cíclica, ya que está obligado a volver a un valor anterior tarde o temprano. La idea es obtener un suministro de dígitos que no se repita sobre sí mismos durante mucho tiempo y, como mínimo, esto requiere que m sea lo suficientemente grande. En muchas versiones del algoritmo, m se establece en ![]() , de hecho bastante grande, y si el esquema iterativo se elige con criterio, cada entero entre 0 y m −1 se obtendrá una vez antes del reciclaje. La recurrencia de dígitos muestra que las iteraciones son menos que aleatorias. A pesar de esta falla inherente, la secuencia de valores
, de hecho bastante grande, y si el esquema iterativo se elige con criterio, cada entero entre 0 y m −1 se obtendrá una vez antes del reciclaje. La recurrencia de dígitos muestra que las iteraciones son menos que aleatorias. A pesar de esta falla inherente, la secuencia de valores ![]() generalmente logra pasar una batería de pruebas de aleatoriedad. Por lo tanto, los números se califican como pseudoaleatorios, lo suficientemente satisfactorios para la mayoría de las aplicaciones. Muchos usuarios se arrullan a aceptar la falsa imprevisibilidad de estos números y simplemente invocan una instrucción como "x = rand" en algún código de computadora como C++ siempre que necesitan simular el funcionamiento del azar. Sin embargo, incluso los generadores de números aleatorios más sofisticados los traiciona su determinismo inherente. Si se grafican valores generados sucesivamente como pares o tripletes en un plano o en el espacio, los patrones espaciales ordenados aparecen como estrías o capas. “Los números aleatorios caen principalmente en los planos”, así lo expresó una vez el matemático George Marsaglia.
generalmente logra pasar una batería de pruebas de aleatoriedad. Por lo tanto, los números se califican como pseudoaleatorios, lo suficientemente satisfactorios para la mayoría de las aplicaciones. Muchos usuarios se arrullan a aceptar la falsa imprevisibilidad de estos números y simplemente invocan una instrucción como "x = rand" en algún código de computadora como C++ siempre que necesitan simular el funcionamiento del azar. Sin embargo, incluso los generadores de números aleatorios más sofisticados los traiciona su determinismo inherente. Si se grafican valores generados sucesivamente como pares o tripletes en un plano o en el espacio, los patrones espaciales ordenados aparecen como estrías o capas. “Los números aleatorios caen principalmente en los planos”, así lo expresó una vez el matemático George Marsaglia.
Por cierto, ¿qué tan aleatorio es el algoritmo de Janus? Aunque las iteraciones sucesivas se generan mediante un mecanismo de azar, también están correlacionadas secuencialmente. Esto implica un nivel de redundancia que la prueba ApEn del capítulo anterior debería poder destacar. Se utilizaron veinte iteraciones distintas de Janus, a saber, el algoritmo de Bartlett que comienza con ![]() , y una aplicación de ApEn (1) a esta cadena da 4.322, que es simplemente la entropía de un alfabeto fuente de 20 símbolos igualmente probables. (log 20 = 4.322). Sin embargo, ApEn (2) es simplemente 0.074, otra indicación clara de que existen patrones sustanciales entre las iteraciones.
, y una aplicación de ApEn (1) a esta cadena da 4.322, que es simplemente la entropía de un alfabeto fuente de 20 símbolos igualmente probables. (log 20 = 4.322). Sin embargo, ApEn (2) es simplemente 0.074, otra indicación clara de que existen patrones sustanciales entre las iteraciones.
Una secuencia verdaderamente aleatoria de ensayos de Bernoulli 1/2 consiste en bloques equiprobables de dígitos binarios de un tamaño dado. Esto también debería ser cierto a la inversa, ya que un simple intercambio entre 0 y 1 da como resultado Imag5 espejo de los mismos bloques. Por lo tanto, cualquier prueba de aleatoriedad en una dirección tendría que mostrar aleatoriedad cuando se mira al revés.
4.6 Janus y los demonios
Los "demonios" en cuestión son pequeñas criaturas hipotéticas invocadas en el siglo pasado para lidiar con paradojas que surgieron durante los primeros años de la termodinámica. El dilema del siglo XIX era que un conjunto de partículas microscópicas que se movían de manera determinista en algún recipiente confinado de acuerdo con las leyes del movimiento de Newton necesitaba reconciliarse con la idea de Ludwig Boltzmann de que la configuración completa de partículas se mueve, en promedio, de estados altamente ordenados a estados desordenados. Este inexorable movimiento hacia el desorden introduce un elemento de irreversibilidad que aparentemente contradice el movimiento reversible de las partículas individuales, y esta observación fue vista al principio como una paradoja. En el acalorado debate (sin juego de palabras) que a continuación, el físico James Clerk Maxwell introdujo un pequeño demonio en 1871 que supuestamente podría frustrar la irreversibilidad y así disipar la paradoja. El demonio, a quien Maxwell se refirió como "un tipo muy observador y de dedos ágiles", opera una pequeña puerta en una partición que separa un gas en movimiento térmico en dos cámaras. La diminuta criatura es capaz de seguir el movimiento de moléculas individuales en el gas y permite que solo las moléculas rápidas entren en una cámara, mientras que solo permite que salgan las lentas. Al clasificar las moléculas de esta manera, se crea una diferencia de temperatura entre las dos porciones del recipiente y, suponiendo que inicialmente la temperatura era uniforme, se crea un orden a partir del desorden (con esto quiero decir que se puede aprovechar una diferencia de temperatura para generar movimiento organizado, mientras que el movimiento desordenado de las moléculas a temperatura uniforme no se puede aprovechar de manera útil). En 1929, el físico Leo Szilard refinó este personaje de ficción e hizo una conexión con la idea de información y entropía que, por supuesto, encaja con uno de los temas de este libro. Antes de ver cómo opera el demonio de Szilard, debemos retroceder un poco. La física clásica nos dice que cada molécula en el contenedor tiene su movimiento futuro completamente determinado al conocer exactamente su posición y velocidad presentes. Por simplicidad, me limito a colocar y dividir el espacio dentro de la caja que contiene los miles de millones de moléculas del gas en un grupo de celdas más pequeñas de igual volumen y acepto identificar todas las moléculas dentro de la misma celda. De esta manera se establece un "granulado grueso" en el que las partículas individuales ya no se pueden distinguir entre sí, excepto para decir que pertenecen a una de un número finito N de células más pequeñas dentro del contenedor. A medida que las moléculas rebotan entre sí y chocan con las paredes de la caja, se mueven de una celda a otra, y cualquier configuración inicial improbable de moléculas, como tenerlas todas confinadas en una sola esquina del recinto, con el tiempo tenderá a moverse hacia una disposición más probable en la que las moléculas se dispersen por toda la caja de forma desordenada.
Aunque es remotamente concebible que se produzca exactamente el movimiento opuesto, Boltzmann estableció, como se mencionó anteriormente, que, en promedio, el movimiento es siempre de una disposición ordenada a otra menos ordenada de moléculas. Esta es una versión de la Segunda Ley de la Termodinámica, y está respaldada por la observación de que un antiguo templo abandonado en la jungla, con el tiempo, se derrumbará en ruinas, un montón de piedras. La probabilidad pi de encontrar una molécula en la i-ésima celda en un momento determinado es, para i = 1, 2,…, N, muy cercana a ![]() según la Ley de los números grandes, para N lo suficientemente grande, donde
según la Ley de los números grandes, para N lo suficientemente grande, donde ![]() es el número de moléculas realmente ubicadas en esa célula y T es el número total de moléculas dentro de todas las N células. En el capítulo anterior, encontramos que la entropía H por celda es el negativo de la suma de todas las celdas de
es el número de moléculas realmente ubicadas en esa célula y T es el número total de moléculas dentro de todas las N células. En el capítulo anterior, encontramos que la entropía H por celda es el negativo de la suma de todas las celdas de ![]() . Lo que Boltzmann estableció, en efecto, es que nunca se puede esperar que H disminuya y su máximo se alcanza cuando las moléculas están equidistribuidas entre las células (pi = 1 / N para todas); el desorden total se identifica con la máxima entropía y aleatoriedad. Esta "calle de un solo sentido" es la paradoja de la irreversibilidad. La ubicación exacta de cada molécula en un momento determinado se especifica mediante sus tres coordenadas de posición, y estos números se pueden representar mediante infinitas cadenas binarias, como hemos visto. Sin embargo, el granulado grueso de moléculas en N células significa que la posición exacta ahora se desconoce, y la ubicación de una molécula se caracteriza en cambio por una cadena binaria de longitud finita que etiqueta la celda particular en la que se encuentra, de manera muy similar como en el juego de “20 preguntas” donde un objeto que se coloca en un tablero dividido en 16 cuadrados está determinado por 4 binarios dígitos. Es esta imprecisión la que socava el determinismo; no hay incertidumbre sin grano grueso. Aquí puede resultar útil una analogía con la disposición aleatoria de cadenas binarias. Piense en los ceros y unos como si representaran la cara y la cruz de una moneda lanzada. En el nivel macroscópico de una cuerda individual, solo conocemos el número total de caras y colas, pero no su disposición dentro de la cuerda. Ésta es la analogía: las moléculas dentro de una célula se pueden organizar de muchas formas, pero a nivel de células, solo sabemos cuántas hay, pero no su paradero. Suponga que a uno se le da inicialmente una cadena de n ceros de un conjunto de
. Lo que Boltzmann estableció, en efecto, es que nunca se puede esperar que H disminuya y su máximo se alcanza cuando las moléculas están equidistribuidas entre las células (pi = 1 / N para todas); el desorden total se identifica con la máxima entropía y aleatoriedad. Esta "calle de un solo sentido" es la paradoja de la irreversibilidad. La ubicación exacta de cada molécula en un momento determinado se especifica mediante sus tres coordenadas de posición, y estos números se pueden representar mediante infinitas cadenas binarias, como hemos visto. Sin embargo, el granulado grueso de moléculas en N células significa que la posición exacta ahora se desconoce, y la ubicación de una molécula se caracteriza en cambio por una cadena binaria de longitud finita que etiqueta la celda particular en la que se encuentra, de manera muy similar como en el juego de “20 preguntas” donde un objeto que se coloca en un tablero dividido en 16 cuadrados está determinado por 4 binarios dígitos. Es esta imprecisión la que socava el determinismo; no hay incertidumbre sin grano grueso. Aquí puede resultar útil una analogía con la disposición aleatoria de cadenas binarias. Piense en los ceros y unos como si representaran la cara y la cruz de una moneda lanzada. En el nivel macroscópico de una cuerda individual, solo conocemos el número total de caras y colas, pero no su disposición dentro de la cuerda. Ésta es la analogía: las moléculas dentro de una célula se pueden organizar de muchas formas, pero a nivel de células, solo sabemos cuántas hay, pero no su paradero. Suponga que a uno se le da inicialmente una cadena de n ceros de un conjunto de ![]() cadenas binarias posibles de longitud n. Esta disposición poco probable puede ocurrir de una sola manera y corresponde a una configuración improbable y singularmente distinguible. Sin embargo, el número de celdas que tienen el mismo número de caras y colas es una cantidad muy grande, incluso para valores moderados de n. Esencialmente se trata de esto: hay muchas más formas de obtener cadenas con un número igual de 0 y 1 que las que hay para encontrar una cadena de todos ceros. Con n igual a 4, por ejemplo, hay una sola cadena 0000, pero se encuentran seis cadenas en las que 0 y 1 están en la misma proporción, a saber, 0011, 0101, 0110, 1001, 1010 y 1100. A medida que n aumenta la discrepancia entre cadenas ordenadas (con patrones) y desordenadas (aleatorias) crece enormemente. Simplemente duplicar n a 8, por ejemplo, da como resultado 70 cadenas que son macroscópicamente indistinguibles ya que la disposición de cabezas y colas es borrosa en este nivel.
cadenas binarias posibles de longitud n. Esta disposición poco probable puede ocurrir de una sola manera y corresponde a una configuración improbable y singularmente distinguible. Sin embargo, el número de celdas que tienen el mismo número de caras y colas es una cantidad muy grande, incluso para valores moderados de n. Esencialmente se trata de esto: hay muchas más formas de obtener cadenas con un número igual de 0 y 1 que las que hay para encontrar una cadena de todos ceros. Con n igual a 4, por ejemplo, hay una sola cadena 0000, pero se encuentran seis cadenas en las que 0 y 1 están en la misma proporción, a saber, 0011, 0101, 0110, 1001, 1010 y 1100. A medida que n aumenta la discrepancia entre cadenas ordenadas (con patrones) y desordenadas (aleatorias) crece enormemente. Simplemente duplicar n a 8, por ejemplo, da como resultado 70 cadenas que son macroscópicamente indistinguibles ya que la disposición de cabezas y colas es borrosa en este nivel.
Sin embargo, si las moléculas comienzan naturalmente en una configuración más probable, entonces la irreversibilidad es menos aparente; de hecho, ¡es posible observar un movimiento momentáneo hacia un orden incrementado! Es el artificio de comenzar con una configuración artificial (hecha por el hombre) y altamente inusual lo que crea la travesura. En el curso normal de eventos no manipulados, son los arreglos más probables que uno espera ver. Humpty-dumpty sentado precariamente en una pared es una vista rara; una vez dividido en muchos fragmentos, es poco probable que vuelva a reunirse sin alguna intervención, e incluso es posible que todos los hombres del Rey no puedan ayudar.
Esta breve discusión sobre la irreversibilidad proporciona otra ilustración de que una secuencia generada de manera determinista puede comportarse de manera aleatoria debido a nuestra ignorancia de todos los dígitos binarios excepto un número finito de un número semilla inicial. En el caso que nos ocupa, esto se debe a que se truncan las secuencias binarias que describen la posición exacta de cada molécula, agrupando todas ellas en un número finito de células. Volvamos ahora a Szilard y su demonio y finalmente hagamos una conexión con el algoritmo de Janus. Se coloca una sola molécula en un recipiente cuyos dos extremos están bloqueados por pistones y que cuenta con una delgada partición removible en el centro (Fig. 4.15). Inicialmente, el demonio observa en qué lado de la partición está la molécula y lo registra con un dígito binario, 0 para el lado izquierdo y 1 para el derecho. El pistón del lado que no contiene la molécula se empuja suavemente hacia la partición, que luego se retira. Esto se puede lograr sin un gasto de energía, ya que la cámara a través de la cual se comprime el pistón está vacía.
 15.20.47.png)
Fig. 4.15 El motor Szilard. Un demonio observa una molécula en la cámara de la derecha y empuja suavemente el pistón de la izquierda hacia la partición central, que luego se retira. La molécula en movimiento choca contra el pistón y lo desliza hacia la izquierda. Esto crea un trabajo útil y reduce la entropía. Entonces el ciclo comienza de nuevo.
4.7 El borde de la aleatoriedad
Y entonces se puede decir que la misma fuente de perturbación fortuita, de "ruido", que en un sistema no viviente (es decir, no replicativo) conduciría poco a poco a la desintegración de toda estructura, es el progenitor de la evolución en la biosfera y da cuenta de su libertad irrestricta de creación, gracias a la estructura replicativa del ADN: ese registro del azar, ese conservatorio sordo donde se conserva el ruido junto con la música.
Chance and Necessity, de Jacques Monod
Valentine: es todo muy, muy ruidoso ahí fuera. Muy difícil de detectar la melodía. Como un piano en la habitación de al lado, está tocando tu canción, pero desafortunadamente está fuera de control, faltan algunas cuerdas y el pianista está sordo y borracho, quiero decir, ¡el ruido! ¡imposible!
Hannah: ¿Qué haces?
Valentine: Empiezas a adivinar cuál podría ser la melodía. Intenta sacarla del ruido. Intentas esto, intentas aquello, comienzas a obtener algo, está a medio cocer, pero comienzas a poner notas que faltan o no son las notas correctas ... y poco a poco ... ¡el algoritmo perdido!
Arcadia, de Tom Stoppard
Hasta ahora hemos intentado captar la elusiva noción de azar observando cadenas binarias, la imagen más ingeniosa de una sucesión de sucesos sensoriales. Dado que la mayoría de las cadenas binarias no se pueden comprimir, se podría concluir que la aleatoriedad es omnipresente. Sin embargo, los flujos de datos de nuestra conciencia, de hecho, exhiben cierto nivel de coherencia. El cerebro procesa Imag5 sensoriales y desentraña la masa de datos que recibe, de alguna manera ancla nuestras impresiones al permitir que surjan patrones del ruido. Si lo que observamos no es completamente aleatorio, no significa, sin embargo, que sea determinista. Es solo que las correlaciones que aparecen en el espacio y el tiempo conducen a patrones reconocibles que permiten, como dice el poeta Robert Frost, “una permanencia temporal frente a la confusión”. En el mundo que observamos, es evidente que existe una tensión entre orden y desorden, entre sorpresa e inevitabilidad. Deseamos ampliar estos pensamientos volviendo a las cadenas binarias, pensando en ellas ahora como la codificación de las fluctuaciones de algún proceso natural. En este contexto, la noción de complejidad algorítmica nos preocupó en la discusión a anterior que nuestra mente no capta la idea de complejidad en la naturaleza o en los asuntos cotidianos, como se suele percibir. Considere si la salida aleatoria de un mono en un teclado es más compleja que un soneto de Shakespeare de la misma longitud. La estrecha estructura organizativa del soneto nos dice que su complejidad algorítmica es menor que la narración producida por el simio. Evidentemente, necesitamos algo menos ingenuo como medida de complejidad que simplemente la longitud de un programa que reproduce el soneto. Charles Bennett ha propuesto, en cambio, medir la complejidad de una cadena como el tiempo requerido, es decir, el número de pasos computacionales necesarios, para replicar su secuencia de alguna otra cadena de programa[10].
Recuerde la probabilidad algorítmica que se definió como una suma de todos los programas que generan cadenas binarias s. Evidentemente, esta probabilidad está ponderada a favor de los programas cortos, ya que contribuyen más a la suma que los más largos. Si la mayor parte de la probabilidad proviene de programas cortos para los que el número de pasos necesarios para calcular s es grande, se dice que la cadena s tiene profundidad lógica.
El prolongado proceso creativo que condujo al soneto de Shakespeare lo dota de una profundidad lógica que supera con creces el tecleado inconsciente del mono, aunque el soneto tiene menos complejidad algorítmica debido a las redundancias, algunas obvias y otras más sutiles, que surgen en el uso del lenguaje. Aunque el contenido de información del soneto puede ser limitado, revela un mensaje único que es profundo e inesperado. Permitiendo que una cadena larga y aleatoria s solo pueda ser replicada por un programa de aproximadamente la misma longitud que s, las instrucciones “copy s” pueden, no obstante, llevarse a cabo de manera eficiente en unos pocos pasos. De manera similar, una cadena totalmente ordenada como 01010101… requiere solo unos pocos pasos computacionales para ejecutar "copiar 01 n veces" ya que una instrucción de copia simple se repite muchas veces una y otra vez. Claramente, cadenas como estas que implican una complejidad algorítmica muy grande o muy pequeña son superficiales en el sentido de tener poca profundidad lógica: se necesita poco ingenio para ejecutar los pasos del programa. Por lo tanto, las cadenas que poseen profundidad lógica deben residir en algún lugar entre estos extremos, entre el orden y el desorden. Como dijo Charles Bennett: el valor de un mensaje parece no residir en su información (sus partes absolutamente impredecibles), no en su obvia redundancia (repeticiones textuales, frecuencias de dígitos desiguales), sino más bien en lo que podríamos llamar su redundancia: partes predecibles solo con dificultad.
Otro ejemplo sorprendente de profundidad lógica lo proporcionan las secuencias de ADN. Esta familiar hebra de doble hélice está formada por nucleótidos que consisten en azúcares y fosfatos conectados a una de cuatro bases diferentes designadas simplemente como el alfabeto A, C, G, T. Cada triplete de este alfabeto de símbolos codifica uno de los 20 aminoácidos que están unidos entre sí para formar proteínas. Algunas de estas proteínas son enzimas que, de manera autorreferencial, regulan la forma en que el ADN se despliega para replicarse, y otras enzimas regulan cómo el ADN transcribe su mensaje para producir más proteínas. Escribir cada uno de los cuatro símbolos en forma binaria como 00, 01, 10, 11 muestra al ADN como una cadena binaria larga (alrededor de 3 mil millones de símbolos en los seres humanos). Dado que hay 43 = 64 posibles tripletes de nucleótidos A, C, G, T, llamados codones, y solo 20 aminoácidos, existe cierta duplicación en la forma en que tiene lugar la transcripción. Además, algunos fragmentos de la cadena de ADN se repiten muchas veces y también parece haber correlaciones a largo plazo entre diferentes partes de la cadena, lo que sugiere que existe una redundancia considerable. Por otro lado, algunas secuencias de codones parecen ser basura, sin tener un papel reconocible, posiblemente causado por acumulaciones fortuitas durante el lapso del tiempo evolutivo. De ello se deduce que el ADN se encuentra entre la aleatoriedad y la estructura, y su profundidad lógica debe ser sustancial, ya que la evolución del código tuvo lugar durante varios millones de años. Por lo tanto, una cadena de ADN=s puede ser replicada por una cadena de programa más corta s∗, pero es probable que el modelo del código más sucinto s∗ sea complicado, requiriendo mucho trabajo para descomprimirlo en una descripción completa de la cadena s. La maquinaria genética de una célula proporciona no solo la copia del ADN, indirectamente, su propia replicación, sino que además controla el inicio del crecimiento de un organismo a través de las proteínas codificadas por el ADN. Las células se combinan para formar organismos y los organismos luego interactúan para formar ecosistemas. El proceso mecánico de la replicación del ADN se ve interrumpido de vez en cuando por mutaciones aleatorias, y estas mutaciones funcionan como materia prima para la selección natural; la evolución se alimenta de la aparición fortuita de mutaciones que favorecen o inhiben el desarrollo de determinados individuos.
El azar también se entromete más allá del nivel de los genes, ya que los organismos tienen encuentros inesperados y a veces perturbadores con el mundo que los rodea, lo que afecta la reproducción y supervivencia de individuos y especies. Algunos de estos eventos contingentes, es lo que el físico Murray Gell-Mann llama "accidentes congelados[11]", tienen consecuencias a largo plazo porque encierran ciertas regularidades que persisten para proporcionar a los organismos sucesivos, individual y colectivamente, características que poseen un ancestro común reconocible. La acumulación de accidentes congelados da lugar a la complejidad de las formas que observamos a nuestro alrededor. La estructura helicoidal del ADN y las formas orgánicas como los caracoles puede ser una consecuencia de tales accidentes. Jacques Monod expresó la misma idea de manera más evocadora como aleatoriedad atrapada, preservada y reproducida por la maquinaria de la invariancia y, por lo tanto, convertida en orden, regla, necesidad[12]. Algunos accidentes de la naturaleza permiten adaptar piezas existentes a nuevas funciones. El paleontólogo Stephen Jay Gould comenta cómo la casualidad brinda una oportunidad para la selección cuando argumenta que la complejidad de las formas se debe a un ajuste deficiente, un diseño peculiar y, sobre todo, la redundancia... la redundancia generalizada hace posible la evolución[13]. Si los animales fueran perfeccionados de manera ideal, con cada parte haciendo una cosa a la perfección, entonces la evolución no ocurriría, porque nada podría cambiar y la vida terminaría rápidamente a medida que los entornos se modificaran y los organismos no respondieran. Es poco probable que las piezas totalmente formadas se fabriquen desde cero, pero son producto de la casualidad de la naturaleza. Los eventos catastróficos, como los impactos de grandes meteoritos, también pueden alterar el curso de la evolución al extinguir algunas especies y otorgar una ventaja selectiva a otros habitantes anteriormente marginales. La redundancia en el ADN y en los organismos que genera los hace menos frágiles a las alteraciones. Lo mismo ocurre a nivel de ecosistemas, que aparentemente pueden lograr diversidad de especies debido a la heterogeneidad espacial y las fluctuaciones en el medio ambiente.
La perturbación de una comunidad ecológica permite que nuevas especies colonicen áreas que normalmente estarían habitadas por un competidor más agresivo, y las incursiones esporádicas como inundaciones, tormentas o incendios pueden dejar a su paso un paisaje irregular en el que habitan más especies de las que habrían de otra manera. Sería posible en un entorno más estable en el que la depredación y la competencia garantizarían el dominio de unas pocas especies. El ecologista G. Evelyn Hutchinson reflexionó sobre "la paradoja del plancton" según la cual varias especies de plancton en competencia pueden coexistir, en lugar de que una especie sobreviva a expensas de las otras, y de manera similar concluyó que esto era posible porque la turbulencia en las aguas desaloja la estructura de la comunidad del equilibrio[14].
Ya sea a nivel de células, organismos o ecosistemas, el azar y el orden se mezclan para desplegar el vasto panorama del mundo viviente. Esto subraya la utilidad de la aleatoriedad para mantener la variabilidad y la innovación mientras se preserva la coherencia y la estructura. Varios pensadores han ido más allá al sugerir cómo puede surgir cierta apariencia de orden y coherencia a partir de interacciones irregulares y accidentales dentro de los sistemas biológicos. La idea es que grandes conjuntos de moléculas y células tienden a organizarse en estructuras más complejas, flotando dentro de los extremos de, por un lado, encuentros totalmente aleatorios donde reina la confusión y no es posible el orden y, por el otro, estrecha y rígidamente interacciones reguladas donde se excluye el cambio. Las células y los organismos aislados, excluidos de la posibilidad de innovación, se desvían hacia la descomposición y la muerte. El biólogo Stuart Kauffman cree que la selección ... no es la única fuente de orden en biología, y los organismos no son solo artilugios arreglados, sino expresiones de leyes naturales más profundas ... se está descubriendo un orden profundo en grandes, complejos y sistemas aparentemente aleatorios[15]. Cree que este orden emergente subyace no solo en los orígenes de la vida misma, sino en gran parte del orden que se observa en los organismos de hoy.
Para el físico Per Bak, el orden emergente ocurre no solo en el ámbito de los fenómenos biológicos, sino que es desenfrenado en los mundos de la experiencia física y social[16]: el comportamiento complejo en la naturaleza refleja la tendencia a evolucionar hacia un estado crítico equilibrado, muy fuera de balance, donde perturbaciones menores pueden conducir a eventos, llamados avalanchas, de todos los tamaños... la evolución a este estado tan delicado ocurre sin el diseño de ningún agente externo. El estado se establece únicamente debido a las interacciones dinámicas entre los elementos individuales del sistema: el estado crítico se autoorganiza. Kauffman subraya estos sentimientos cuando dice que parece muy probable que la especiación y la extinción reflejen la dinámica espontánea de una comunidad de especies[17]. La misma lucha por sobrevivir, por adaptarse a pequeños y grandes cambios ... puede, en última instancia, llevar a algunas especies a la extinción mientras crea nuevos nichos para otras. La vida, entonces, se desenvuelve en una interminable procesión de cambio, con pequeñas y grandes explosiones de especiaciones, pequeñas y grandes explosiones de extinciones, resonando lo viejo, resonando en lo nuevo... estos patrones... de alguna manera están autoorganizados, de alguna manera fenómenos colectivos emergentes, de alguna manera expresiones naturales de las leyes de la complejidad.
El químico Ilya Prigogine, incluso antes, había dado rienda suelta a ideas similares cuando defendía una visión de la naturaleza alejada del equilibrio en la que la evolución y la complejidad creciente están asociadas con la autoorganización de sistemas que se alimentan del flujo de materia y energía proveniente de la Tierra[18] y el entorno exterior correspondiente a una delicada interacción entre el azar y la necesidad, entre fluctuaciones y leyes deterministas. Contrasta estos nichos de entropía decreciente con la degradación y muerte irrevocables que implica la Segunda Ley de la Termodinámica. Las estructuras complejas compensan el inevitable deslizamiento cuesta abajo hacia la desintegración al ver su propia descomposición en el sistema abierto que las nutre. Recuerde al demonio Szilard que es capaz de disminuir la entropía y aumentar el orden, poco a poco, acumulando un registro de dígitos basura que normalmente deben borrarse para restaurar la pérdida de entropía. Pero si estos dígitos se desperdician sin ceremonias en el medio ambiente, se crea una bolsa de orden a nivel local incluso cuando el desorden aumenta a nivel global. La tesis de la complejidad autoorganizada es una idea controvertida que encuentra hoy su voz más ardiente en el Instituto Santa Fe en Nuevo México, y no es nuestra intención involucrarnos en la polémica en curso con respecto a la validez de esta y las ideas de complejidad que compiten entre sí y está molestando a estos pensadores. Esto se revisa mejor en una serie de libros que han aparecido en los últimos años, uno de los cuales es el esfuerzo de Bak en How Nature Works[19].
En cambio, el acepto de esta idea es como una metáfora provocativa de cómo el azar y el orden conspiran para proporcionar una visión de la complejidad en la naturaleza y en los artefactos del hombre. Un paradigma estrechamente relacionado de cómo la naturaleza se organiza entre el orden y el desorden es que la simetría, una manifestación del orden, tiende a ser contrarrestada en los sistemas biológicos por moléculas orgánicas asimétricas, incluida la asimetría especular descubierta por Louis Pasteur y otros en el siglo XIX. Mucho más tarde, Erwin Schrodinger fue clarividente al intuir que la estructura de las moléculas genéticas tendría que ser a-periódica y no cristales periódicos[20]. La asimetría como una forma de desorden iniciado por eventos fortuitos es omnipresente en los sistemas biológicos.
Esa aleatoriedad da lugar a la innovación, y la diversidad en la naturaleza se refleja en la noción de que el azar es también la fuente de la invención en las artes y los asuntos cotidianos en los que los procesos que ocurren naturalmente se equilibran entre una organización estrecha, donde la redundancia es primordial, y la volatilidad, en qué poco orden es posible. Se puede argumentar que existe una diferencia de tipo entre las elecciones inconscientes, y a veces conscientes, hechas por un escritor o artista al crear una cadena de palabras o notas musicales y la sucesión accidental de eventos que tienen lugar en el mundo natural. Sin embargo, lo que importa es la percepción de ambigüedad en una cadena, y no el proceso que la generó, ya sea por el hombre o por la naturaleza en general. Vimos que el lenguaje no está completamente ordenado, lo que lo haría predecible y aburrido, ni tan desestructurado que se vuelva incomprensible. Es la fructífera interacción entre estos extremos lo que da a cualquier lenguaje su riqueza de matices. Lo mismo ocurre con la música de Bach, por mencionar un solo compositor, que se encuentra entre la sorpresa y la inevitabilidad, entre el orden y la aleatoriedad. Muchos arquitectos intentan combinar el ingenio con la seriedad del diseño para crear edificios que sean divertidos y atractivos a la vez que cumplen con los requisitos funcionales dictados por el uso previsto de estos edificios. En un libro sobre misterio y romance, John Cawelti afirma que si buscamos orden y seguridad, es probable que el resultado sea aburrimiento y simetria. Pero al rechazar el orden en aras del cambio y la novedad trae peligro e incertidumbre... la historia de la cultura puede interpretarse como una tensión dinámica entre estos dos impulsos básicos ... entre la búsqueda del orden y la huida del aburrimiento[21].
La oportunidad para la novedad y la complejidad y la formación de patrones lejos del equilibrio se basa en el cliché, popularizado por John Guare en su obra “Seis grados de separación[22]”, todos estamos conectados con todos los demás en el mundo a través de un máximo de seis conocidos intermedios. Un estudio del matemático Duncan Watts muestra que un conjunto de entidades estrechamente entretejidas en grupos puede expandirse rápidamente en una red global tan pronto como algunos enlaces se vuelvan a conectar aleatoriamente a través de la red[23]. Abundan los ejemplos para mostrar estructuras tan diversas como la comunidad global de humanos, las redes de energía eléctrica y las redes neuronales que han evolucionado para residir en algún lugar entre una estructura cristalina de conectividad local y desorden aleatorio. Todos estos ejemplos recuerdan una deliciosa acuarela del artista del siglo XVIII Pietro Fabris, uno de una serie utilizada para ilustrar una obra llamada Campi Phlegraei[24] por el erudito y diplomático urbano Sir William Hamilton, enviado británico al entonces Reino de Nápoles. En el color del agua, Hamilton está apoyado en su bastón debajo del cráter del Vesubio, viendo cómo la piedra pómez sulfurosa es lanzada al azar desde el respiradero de eructos reflejando al parecer, el delicado equilibrio entre el tumulto y la anarquía del volcán indómito y el cielo azul sereno más allá, entre el capricho de la vida ordinaria y el mundo de la razón, un retrato exquisito de la vida en equilibrio entre el orden y el desorden.
 19.17.48.png)
Campi Phlegraei, October 1767
4.8 Leyes de complejidad y potencias
Como vimos, el principio organizador central en la teoría de probabilidad convencional es la Ley Normal que nos dice, aproximadamente, que las sumas de muestras aleatorias independientes con un promedio común tienden a distribuirse como una curva normal en forma de campana. Por ejemplo, si las muestras son las alturas de las personas, entonces el promedio representa un tamaño característico de la población y la mayoría de los individuos no se desvían demasiado de esa longitud de escala típica. Por otro lado, existen numerosos conjuntos de variables que no tienen una escala típica, ya que abarcan un amplio intervalo y no existe un valor característico para su distribución. Uno piensa en el tamaño de las ciudades, que va desde pequeños pueblos de varios miles de habitantes hasta grandes metrópolis cuya población se mide en millones. En cierto sentido, para precisar momentáneamente, estar libre de escala es un atributo de lo que se llama una Ley de Poder (o ley de potencias) en la que hay muchos eventos de tamaño pequeño a mediano intercalados por un número menor de eventos extremos.
El estudio de tales distribuciones libres de escala proporciona un ancla estadística para una gran variedad de datos que carece de un tamaño característico y, como tal, sirve como un principio organizador que es similar, en algunos aspectos, al de la curva normal en el modelo tradicional de la teoría. Sin embargo, si bien la teoría convencional se asienta sobre una base matemática sólida, debe admitirse que parte de lo que se informa sobre las leyes de energía es especulativo, aunque ciertamente hay un núcleo de validación matemática y al menos parte de ella está respaldada en parte por datos empíricos de evidencia. Se han propuesto varios mecanismos para la existencia de leyes de poder, pero esencialmente lo que parece funcionar aquí es que un gran número de variables que representan eventos contingentes interactúan en una amplia gama de factores temporales y escalas espaciales. Esto se manifiesta en una distribución de la frecuencia de tallas que poseen lo que generalmente se llama colas gordas. Esto significa que la ocurrencia de eventos extremos, aunque no son frecuentes, es mucho más común de lo que se esperaría de la curva normal. Como veremos, muchos procesos naturales siguen esta distribución, al igual que los patrones creados por el hombre, como los mercados financieros. Los sucesos catastróficos, como los grandes terremotos y las crisis financieras, se pueden anticipar con más regularidad de lo que los modelos de probabilidad convencionales harían creer.
Una relación que asigna un valor a alguna cantidad positiva x se dice que es una ley de potencia si es proporcional, para todo x suficientemente grande, al recíproco de alguna potencia b de x, a saber, 1/xb con un número b que generalmente es entre uno y tres. Un atributo importante de las relaciones de la ley de potencia es que son invariantes en escala, lo que significa que si uno estira o contrae la variable x en algún factor s, de modo que ahora la medimos en una escala diferente, entonces la forma de la relación permanece esencialmente inalterada.
 12.55.41.png)
Fig. 4.16 Ley de potencias 1/x. Las partes sombreadas tienen áreas iguales que indican que muchos eventos pequeños son equivalentes a algunos eventos más grandes.
Si la relación es entre la magnitud de un evento y la tasa de ocurrencia x de ese evento, entonces, por ejemplo, hay tanta energía disipada en muchos terremotos pequeños como en unos pocos eventos sísmicos grandes, y lo mismo puede decirse de la energía en la turbulencia del viento donde hay unas pocas ráfagas grandes intercaladas entre muchas bocanadas más pequeñas. Los tamaños de los cráteres lunares son otro ejemplo porque hay impactos de meteoritos pequeños y grandes, y hay tantas extinciones de especies pequeñas en el registro geológico como grandes[25]. Estos casos de auto-semejanza y muchos otros en la naturaleza se han verificado empíricamente como en la gráfica de datos de plancton exhibida en la Fig. 4.17 en la cual hay muchas oscilaciones de alta frecuencia de masa de plancton de tamaño moderado y algunas oscilaciones de gran magnitud de baja frecuencia. Esta figura no parece una ley de potencia en su forma actual; lo que falta es la conversión de los datos del plancton en una magnitud al cuadrado de la oscilación, la ilustración es familiar a donde consideramos las fluctuaciones de las ganancias acumuladas en un juego de cara y cruz. Si una gráfica de 5000 lanzamientos se amplía por un factor de 10, de modo que ahora solo se ven 500 lanzamientos, aparece un patrón similar de fluctuaciones en esta nueva escala, y el grupo de puntos ahora muestra grupos adicionales dentro de ellos que no eran visible antes. Los grupos son en realidad grupos dentro de grupos, hasta el nivel de un solo lanzamiento (Fig. 18). Al observar las brechas entre rendimientos a ganancias cero, nuevamente encontramos una ley de potencia que relaciona la magnitud (longitud) de las brechas con su frecuencia: muchas brechas pequeñas intercaladas por algunas más largas. Otros dos ejemplos son la ramificación de los bronquios en el pulmón y la ramificación de la cuenca de un río en riachuelos más pequeños.
 13.02.38.png)
Fig. 4.17 Recuento de células de plancton por mililitro de agua del océano como promedio diario, durante un período de casi 1 año. Los datos se obtuvieron en un amarre frente a la plataforma continental de la costa este de Estados Unidos.
 13.08.18.png)
Fig. 4.18 Fluctuación en el total de ganancias (o pérdidas) en un juego de cara y cruz con 4000 lanzamientos, representados cada décimo valor (mitad superior) y un primer plano de la misma cifra de 1 a 500 (mitad inferior). La misma cantidad de detalles es visible en la trama ampliada 10 veces que en el original.
La auto-similitud de las estructuras fractales implica que existe cierta redundancia debido a la repetición de detalles en todas las escalas. Aunque algunas de estas estructuras parezcan oscilar al borde de la aleatoriedad, en realidad representan sistemas complejos en la interfaz del orden y el desorden. La razón para discutir los fractales y las leyes de poder es que, como verá pronto, hay una firma identificable de auto-similitud que nos permite hacer una conexión con las nociones de autoorganización de sistemas complejos ya discutidos.
En todos los casos, hay eventos poco frecuentes que tienen un gran impacto junto con muchos eventos que tienen poca o ninguna consecuencia. ¡Podemos decir, en definitiva, que es normal no ser normal! Una razón fundamental para las leyes de potencia se conoce como criticidad autoorganizada y, a menudo, se explica en términos del modelo de pila de arena. Aquí, los granos de arena se dejan caer sobre una superficie plana hasta que los lados inclinados de la pila alcanzan una cierta inclinación crítica más allá de la cual cualquier grano nuevo comienza a deslizarse un poco o mucho. En algún momento, la caída de un grano provoca una avalancha. Es la confluencia de miríadas de pequeños eventos contingentes lo que da lugar a una avalancha de cualquier tamaño, y no se puede atribuir a ningún movimiento único dentro de la pila. A partir de entonces, cuando el temblor cede, la pila comienza a acumularse nuevamente hasta alcanzar un estado crítico una vez más, y es en este sentido que se autoorganiza. Se muestra que la distribución de tamaños es una ley de potencia. La perturbación causada por granos adicionales son eventos contingentes, y se argumenta que la pila es un paradigma de muchos procesos naturales que se organizan a sí mismos en un estado crítico equilibrado en el que perturbaciones menores pueden desencadenar una gran avalancha. Los terremotos, los incendios forestales y la extinción de especies se citan como ejemplos de esto. En cada caso, la huella de una ley de escala indica un proceso complejo organizado al borde de la aleatoriedad simplemente como resultado de las interacciones entre los elementos individuales del sistema.
Muchos sistemas en la naturaleza que siguen una ley de poder oscilan entre el orden y el desorden y cada movimiento es la confluencia de muchos efectos, algunos pequeños y otros grandes, sin una escala espacial o temporal característica, que conducen a cambios sin una causa discernible. Simplemente suceden. Una presión externa significativa puede sacudir un sistema y ponerlo en movimiento, pero lo que ocurre a continuación es imprevisto. Otra manifestación de aleatoriedad. El uso de 1 / xb como ancla estadística para organizar una masa de fenómenos aparentemente no relacionados encuentra eco en los dos siglos anteriores, cuando se intentó por primera vez domar el azar apelando a la "ley de los errores", la ley de Gauss. Sin embargo, existen algunas diferencias notables. La curva en forma de campana de Gauss describe la distribución de superposiciones de eventos no relacionados, como el promedio de la muestra, en el que se suman los resultados e independientes, y estos totales se extienden sobre el promedio de la población, con la mayoría cerca del promedio y menos más lejos. Por el contrario, los fenómenos de la ley de potencias dependen de la contingencia. Si se emplea una escala logarítmica tanto en el eje horizontal como en el vertical, la curva 1 / xb aparecerá como una línea recta inclinada hacia abajo de izquierda a derecha. En esta escala, la disminución de la volatilidad de eventos de magnitud grande a pequeña, a medida que aumenta la frecuencia, se convierte en una firma reconocible instantáneamente de cómo la magnitud de las fluctuaciones es causada por la confluencia de muchos eventos contingentes que se distribuyen por una regla de auto-semejanza. De hecho, la aparición de una línea tan recta en una escala logarítmica es a menudo la primera pista de que uno está mirando una ley de potencia.
Para considerar solo un ejemplo, la figura 5.19 muestra el diagrama log-log de los datos del plancton de la figura 4.17 (después de que se haya convertido adecuadamente). No es una línea recta debido a errores de muestreo inherentes, pero, no obstante, revela los orígenes de la ley de potencias. Los datos que se ajustan a las leyes 1 / x son decididamente no gaussianos en varios otros aspectos. Debido a la auto-similitud, hay muchas más fluctuaciones pequeñas que muy grandes, como hemos visto, por lo que la fluctuación promedio dependerá de la proporción de componentes grandes a pequeños. El promedio de la muestra tenderá a aumentar sin límite o reducirse a cero a medida que se incluyen más y más datos, y la Ley de los números grandes, que tenía los datos bajo control, ya no es operativa. Además, la dispersión sobre el promedio de la población en el caso de Gauss ahora está mal definida, ya que la dispersión aumenta a medida que se extiende el tiempo debido al hecho de que se incluyen fluctuaciones cada vez mayores.
 13.16.22.png)
Fig. 4.19 La magnitud de una señal frente a la frecuencia, representada en una escala logarítmica.
Así como la ley gaussiana establece una forma de orden en su dominio, las leyes 1/x proporcionan un principio organizador de firmas para una categoría diferente de eventos. La aparición de una huella 1/x indica un proceso complejo organizado al borde de la aleatoriedad. El libro del físico Per Bak, es un himno a la ubicuidad de las leyes de poder en la naturaleza, en un momento desenfrenado, exclama que la criticidad autoorganizada es una ley de la naturaleza de la que no hay dispensa[26]. Esto se puede comparar con el comentario igualmente desenfrenado de Francis Galton, un siglo antes sobre la Ley Normal en el que termina escribiendo: cuanto más grande es la turba, y mayor es la anarquía aparente, más perfecta es su dominio. Es la ley suprema de la sinrazón. Los procesos casi aleatorios dotados, como están, de patrones de orden cambiantes, pueden ser posiblemente la consecuencia de códigos relativamente cortos que proporcionan reglas de replicación y redundancia como consecuencia de la auto-semejanza estadística en una amplia gama de escalas temporales y espaciales. Las reglas en una escala engendran reglas similares en otras escalas que conducen al surgimiento de estructuras cada vez más complejas. Esto es parodiado por el verso de Jonathan Swift al revés: entonces, observan los naturalistas, una pulga tiene pulgas más pequeñas que se alimentan de él, y estas tienen pulgas más pequeñas para picarlas, y así proceder ad infinitum[27].
4.9 ¿Qué buena es la aleatoriedad?
Nuestro repaso a través de los muchos matices de la aleatoriedad en este manuscrito llega a su fin en el presente apartado al proponer que usted piensa en la incertidumbre como algo más que una elusiva molestia o una rareza de las matemáticas. En la antigüedad, la aleatoriedad se consideraba una causa de desorden y desgracia, que alteraba el poco orden que los individuos y la sociedad habían logrado forjar en su entorno. El mundo de hoy todavía lidia con la incertidumbre y el riesgo en forma de desastres naturales, actos de terrorismo, caídas del mercado y otras escandalosas riquezas de la fortuna, pero también existe una visión más edificante de la aleatoriedad como catalizador de cambios que mejoran la vida. La incertidumbre es una fuente bienvenida de innovación y diversidad, que proporciona la materia prima para la evolución y renovación de la vida. Debido a que la incertidumbre conduce a la descomposición y la muerte, las fluctuaciones fortuitas pueden garantizar la viabilidad de los organismos y la resiliencia de los ecosistemas. Y, posiblemente, el azar ofrece un refugio temporal de la inexorable Segunda Ley de la Termodinámica al permitir que emerjan estructuras complejas a través de la explotación de accidentes fortuitos. Finalmente, los hechos fortuitos alivian el tedio de la rutina y aportan el elemento sorpresa que hace de los lenguajes, las artes y los asuntos humanos en general, una fuente de fascinación sin fin.
4.10 Engañado por la casualidad
Con las cadenas binarias, planteamos la cuestión de cómo las personas perciben la aleatoriedad. La tendencia es que los individuos rechacen patrones tales como una larga serie de caras de moneda en una secuencia binaria como no típicas de la aleatoriedad y compensen esto juzgando que las alternancias frecuentes entre ceros y unos son más típicas del azar; los experimentos que piden a los sujetos que produzcan o evalúen una sucesión de dígitos revelan un sesgo a favor de más alternancias de las que se puede esperar que tenga una cadena aleatoria aceptable; la gente tiende a considerar una agrupación de dígitos como un patrón de orden característico cuando, de hecho, la cadena se genera aleatoriamente.
Estrechamente relacionada con este defecto cognitivo está la falacia del jugador de suponer que después de una larga serie de fracasos, hay una probabilidad de éxito mayor que la que justifican los ensayos de Bernoulli. La evaluación de la aleatoriedad de un individuo en los lanzamientos de una moneda justa parece basarse en la equiprobabilidad de los dos resultados juntos con alguna irregularidad en el orden de aparición. Hay una ilustración a menudo contada de cómo la gente malinterpreta el éxito en el lanzamiento de una moneda. El primer día de un curso de probabilidad, el instructor pide a sus estudiantes que registren 200 lanzamientos de una moneda justa. Por supuesto, algunos pueden hacer trampa y simplemente hacer una secuencia de lanzamientos al azar. Al día siguiente, el instructor asombra a la clase mirando cada uno de los trabajos de los estudiantes e informando, en casi todos los casos, cuáles son verdaderos lanzamientos de monedas a partir de datos falsos. Su capacidad para hacerlo se basa en el sorprendente hecho de que en una secuencia de 200 lanzamientos, es muy probable que ocurra una serie de seis o más caras o cruces consecutivas, como muestro continuo. No obstante, una mirada más cuidadosa a estas ejecuciones secuenciales indica que se puede atribuir algún vestigio de validez a estas falacias, como discutiremos en un momento. Pero primero necesitamos establecer una fórmula para la probabilidad de éxito de ocurrencias de un tamaño dado. Daremos los ingredientes principales del argumento aquí, debido a Berresford[28]. Defina una corrida de eventos, grupo o racha de tamaño k en una serie de n lanzamientos de moneda como una secuencia de exactamente k caras sucesivas. Queremos calcular la probabilidad P (n, k) de encontrar corridas de tamaño no menor que k. Para hacer esto, consideramos dos eventos mutuamente excluyentes cuyas probabilidades separadas luego se suman:
(i) Hay corridas de tamaño no menor que k entre los primeros n - 1 lanzamientos.
(ii) No hay corridas de tamaño no menor que k en los primeros n - 1 lanzamientos, pero los últimos k lanzamientos de n forman un grupo.
Tenga en cuenta que (ii) es la intersección de dos eventos independientes, el primero es que los últimos k + 1 lanzamientos son de la forma cola seguida de k caras (si estos k + 1 lanzamientos fueran todos cara, habría una corrida de tamaño no menos de k entre los primeros n - 1 lanzamientos, que excluimos), y el segundo evento es que no hay carrera dentro de los primeros n - k - 1 lanzamientos. Debido a la independencia, las probabilidades de estos eventos se multiplican.
Ahora calculemos P(200, 6) para dar una respuesta a la pregunta planteada al principio de este apartado, aquella en la que el instructor pidió a sus alumnos que lanzaran una moneda 200 veces. La probabilidad de que haya un grupo de caras de tamaño igual o superior a 6 es 0.8009, una probabilidad superior al 80%, y hay una probabilidad mejor que igualada, 0.5437, de una corrida de cabezas de longitud no inferior a 7.
Estos resultados inesperados son los que confundieron a los estudiantes. Para poner las fórmulas en su contexto más simple, enumero aquí las dieciséis cadenas asociadas con n = 4 y miramos las corridas del dígito uno de varias longitudes:
 22.36.33.png)
De la fórmula para P(n, k), encontramos que P (4, 2) = 0.5 y P (4, 3) = 0.1875 y estos valores son inmediatamente verificables de la tabla anterior ya que hay ocho corridas de tamaño. no menos de 2, lo que da una probabilidad de 8/16 = 0.5, y tres series de tamaño no menos de 3, lo que lleva a una probabilidad de 3/16 = 0.1875.
Dijimos que se espera que una secuencia binaria aleatoria tenga ejecuciones de una longitud más larga de lo que se anticiparía en una secuencia inventada. Sin embargo, hay una salvedad. Un cálculo igualmente válido establece que, en promedio, alrededor de una cuarta parte de todos los lanzamientos son alternados a cara a cruz[29]. Pero una secuencia con demasiados sencillos tiende a tener un menor número de espacios disponibles para tiradas largas, entonces, ¿dónde reside el fracaso de la verdadera aleatoriedad, en la escasez de series exitosas largas o en la escasez de sencillas? Resulta que estos dos requisitos son de hecho compatibles y puede tener un cuarto de lanzamientos sin comprometer la aparición de largas rayas de caras y cruces. Si preguntamos por la probabilidad de que el sucesor inmediato de una cara elegida al azar en una secuencia de lanzamientos sea también una cara, sabemos, por la independencia de los lanzamientos, que se produce una cara o una cruz con la misma frecuencia. Ahora presentaremos un acertijo que tomamos de un artículo llamativo de Miller y Sanjurjo[30] en el que encontramos a un compañero Rogelio lanzando una moneda equilibrada en la que hay la misma probabilidad de obtener cara o cruz en cada lanzamiento. Genera una secuencia relativamente corta de tales lanzamientos y luego miramos esos lanzamientos que siguen a una cabeza. Por ejemplo, si tenemos THTH, entonces T sigue a H, mientras que en HHTH, una cabeza sigue a una cabeza una vez y una cruz una vez. Los giros que siguen inmediatamente a una corrida de caras de longitud uno deben ser una cruz. Se espera un número considerable de singularidades como se acaba de señalar. Para corridas de caras de longitud dos, una cara sucede a una cara solo una vez y una cruz una vez y así sucesivamente para corridas más largas (pero también más raras). Esto conduce a una sobrerrepresentación de cruces después de tiradas cortas. No obstante, nuestro lanzador espera que la proporción de caras que siguen a una cara siga siendo 1/2. Miller y Sanjurjo escriben “sorprendentemente, Rogelio está equivocado; la proporción media de caras es inferior a 1/2".
Para descifrar lo que está sucediendo, calculemos el porcentaje de caras que siguen a una cara, el porcentaje de HH o, de manera equivalente, el HH promedio que es la fracción de HH entre todos los giros que siguen a una cara en una secuencia de lanzamientos dada. Se ignoran las secuencias sin H’s o con una sola H en la última posición ya que en estos casos no hay posibilidad de HH. Entonces, por ejemplo, en la secuencia HTTH, no hay HH (porcentaje cero), mientras que para HHTT hay un solo HH entre las dos cabezas (promedio 1/2 o 50%). Con n lanzamientos, hay 2n secuencias posibles, todas con la misma probabilidad de ocurrencia ya que la moneda es justa. Para cada uno de estos, se calcula el porcentaje de HH. Dividiendo por n - 2 (excluimos la secuencia con todas las cruces y la que solo tiene una cara en la última posición, como ya se señaló), obtenemos el número promedio de caras que siguen a una cara, una estimación de la probabilidad de HH. Todo el procedimiento equivale a lanzar una moneda justa n veces, calcular el HH promedio y luego repetir este procedimiento un gran número de veces; cada una de las 2n secuencias aparecerá aproximadamente el mismo número de veces si n es lo suficientemente grande. Al formar la media muestral de los promedios individuales, se obtiene la probabilidad aproximada de HH, al igual que antes. Lamentablemente, esta probabilidad será inferior a 1/2. Algo está terriblemente mal, ya que sabemos que en lanzamientos independientes de una moneda justa, una H o una T sigue a una H con la misma probabilidad. El rompecabezas se puede ilustrar con un ejemplo simple al considerar el caso de tres lanzamientos que conducen a ocho secuencias posibles. En la siguiente tabla, vemos estas 8 secuencias seguidas, en la segunda columna, por el número de giros que siguen a una cabeza. La tercera columna registra la proporción de frecuencia HH o HH promedio entre los giros anotados en la segunda columna. El valor esperado, o proporción, de las frecuencias individuales es 2 +1/2 dividido por 6 secuencias elegibles es igual a 5/12 = 0.416 y esto es menor que 0.5.
Un ejemplo familiar ilustra lo que está sucediendo. Suponga que en una determinada comunidad, 10.000 propietarios de viviendas poseen una sola residencia, pero que otros 300 propietarios también tienen una segunda residencia. El 40% de los propietarios de viviendas individuales tienen ingresos familiares anuales de $ 100 000 o más, mientras que todos los propietarios de viviendas múltiples tienen esos ingresos. Entonces, para la comunidad en general, el promedio no ponderado de los ingresos familiares promedio de los dos grupos es la suma del 40% y el 100% dividido por 2, es decir, el 70%. Esto da el resultado absurdo de que 7,210 familias tienen ingresos de $ 100,000 o más cuando sabemos que solo 4000 más 300 equivalen a 4300 tienen tales ingresos. El número correcto se encuentra dando la misma ponderación a cada hogar, lo que implica tomar un promedio ponderado de 0,4 × 10, 000 más otro 1,0 × 300 para obtener 4,300 familias con ingresos superiores a $ 100.000. Eso está mucho mejor.
Por lo tanto, volver a los lanzamientos de monedas dando el mismo peso a las secuencias de lanzamientos en lugar de a los lanzamientos en sí es problemático porque tomar un promedio no ponderado de promedios es un procedimiento estadístico poco sólido. Piense en los propietarios de viviendas individuales como lanzamientos de monedas y los grupos en los que se dividieron como dos secuencias. Dar el mismo peso a cada grupo de propietarios corresponde a dar el mismo peso a cada una de las seis secuencias de giros. Entonces, si uno se enfoca en las secuencias y no en los giros individuales, obtenemos un promedio sesgado. La razón es que, al igual que con los propietarios, algunas secuencias tienen más caras que otras. Sin embargo, tenga en cuenta que, aunque nuestra estimación de la probabilidad de HH está sesgada, no niega el hecho irrefutable de que H seguirá una cara con tanta frecuencia como T. En la tabla anterior, hay un número igual de HH y HT, seis de cada uno. De hecho, si uno hubiera elegido un giro al azar en lugar de una secuencia, dado que la distribución de caras es desigual, las secuencias no se habrían elegido con la misma probabilidad y la frecuencia HH habría sido un promedio ponderado; en este caso, la probabilidad de HH es de hecho 1/2.
 13.41.28.png)
El cálculo artificial de HH conduce a una interpretación interesante de la falacia del jugador, la creencia de que una sucesión de caras en el lanzamiento de una moneda pronto se revertirá. La frecuencia a largo plazo de caras/cruces tenderá a igualar como se discutió anteriormente, pero se considera incorrectamente que esta igualación a largo plazo se mantiene incluso en corridas relativamente cortas. En el artículo de Miller y Sanjurjo, los autores sugieren que lo que parece estar sucediendo es que los jugadores observan muchas secuencias cortas de juegos completos aplicando un peso igual a cada una de estas secuencias o juegos obteniendo lo que en efecto es un promedio no ponderado de la porcentajes de una caras que sigue a una caras. Esto subestima la probabilidad real de que una H siga a una H o, de manera equivalente, una sobreestimación de que una cruz seguirá una serie de caras, lo que brinda apoyo a la sensación intuitiva de que después de una sucesión de caras, hay una mayor probabilidad. el próximo tirón será una cruz. Citando a Miller y Sanjurjo nuevamente, esto confirma una creencia en un cambio de suerte que es consistente con la falacia del jugador.
4.11 El modelo de aleatoriedad de Poisson
Para dar más información sobre la naturaleza de la aleatoriedad, introduzcamos algo llamado distribución de Poisson que lleva el nombre del matemático francés de principios del siglo XIX, Simeon Denis Poisson, quien lanzó el concepto esencial en un libro publicado en 1837 en el que analiza la selección del jurado en casos penales junto con otros temas en materia legal. Imagine eventos que tienen lugar de manera impredecible durante un lapso de tiempo o sobre una extensión de espacio, llámelos "llegadas", con la propiedad de que el número de tales llegadas en períodos de tiempo inconexos (o regiones distintas del espacio) son independientes entre sí y, además, no depende de qué intervalo temporal o espacial se mire. Cuando decimos "llegadas", esta es generalmente otra forma de hablar sobre la ocurrencia de un "éxito" o un "éxito" de algún tipo en el que un éxito ocasional ocurre esporádicamente al azar entre muchos de "fracasos". Los ejemplos que siguen darán vida a esta terminología. Defina N(T) como el número de las llamadas llegadas durante algún período de tiempo de duración T; las llegadas son secuenciales en el tiempo, y N(T) cuenta cuántas aparecieron realmente durante T. Suponemos que N(0) = 0 y que las llegadas son eventos aislados; a lo sumo, un evento tiene lugar en cualquier instante particular y, como ya se mencionó, el número de llegadas en intervalos de tiempo no superpuestos es independiente en el sentido de que el número de inicios en un intervalo no dice nada sobre lo que sucedió en un intervalo diferente.
Aunque no se muestra aquí, existe una expresión para la probabilidad de exactamente k éxitos en un intervalo dado, y define lo que se conoce como distribución de Poisson, denotada por Pk. Dicho de otra manera, prob (N(T) = k) = Pk, para k = 0, 1, 2,… Existe una expresión correspondiente N(A) que cuenta ocurrencias fortuitas dentro de una región espacial (también podríamos considerar volúmenes pero el área es suficiente aquí), y Pk es ahora la probabilidad de k llegadas en una región del área A. Permítanme señalar que Pk depende de un parámetro λ que designa el número medio de llegadas, como se verá en los ejemplos siguientes. La distribución de Poisson es útil por varias razones, una de las cuales es que precisa la noción de que las cosas están sucediendo de una manera totalmente fortuita sin una causa discernible.
La idea es esta. Imagine una superficie cuadrada (puede tener cualquier forma, en realidad, o simplemente un intervalo de tiempo). Dispersas un montón de bolitas pequeñas sobre él al azar, lo que significa que cada lanzamiento es independiente del lanzamiento anterior y sin sesgo a favor de una parte de la superficie u otra. Dicho de una manera ligeramente diferente, cada punto de la superficie tiene la misma probabilidad de ser golpeado que cualquier otro. ¿Que ves? Uno podría pensar que los gránulos están distribuidos de manera bastante uniforme en el cuadrado, pero, de hecho, la distribución de puntos se vería muy irregular con grupos de ellos aquí y allá, algunos pequeños y otros grandes, intercalados por algunos puntos en blanco, algo como Fig. 4.20. Supongamos que dispersó n gránulos atropelladamente, donde n puede ser cualquier número. Ahora divida el cuadrado (o cualquier región o período de tiempo para el caso) en un grupo M de cuadrados más pequeños todos del mismo tamaño, y pregunte por la probabilidad de que cualquiera de estos subcuadrados tenga k bolitas, donde k puede ser 0, 1, 2 o cualquier número hasta el total n. Esto se transmite por la cantidad de Poisson Pk que se definió anteriormente. Para n razonablemente grande, da una aproximación cercana a la probabilidad de que un subcuadrado tenga exactamente k gránulos rociados sobre él. Sea Mk el número de estas subregiones que contienen exactamente k gránulos de modo que la suma de Mk sobre todo k, para k = 0, 1, 2,…, n, es igual a M. Según la ley de los números grandes, Pk es aproximadamente igual a la media muestral Mk / M.
 9.01.25.png)
Fig. 4.20 Dispersión espacial de "llegadas" de un proceso de Poisson
Ahora, “grumo” es, por supuesto, un eufemismo para cualquier cantidad, como la ubicación de accidentes automovilísticos en una ciudad durante el mes o cráteres en la superficie de la luna. No tiene por qué ser espacio. Llegadas de autobuses a una parada en particular en una ciudad concurrida durante las horas pico, e incluso eventos extraños como ataques de tiburones a lo largo de la costa de Veracruz durante el verano y el extraño caso de muertes por patadas de caballo en la caballería prusiana durante un período de 10 años, las vacantes de los magistrados de la Corte Suprema de 1950 a 2021, y el número de homicidios diarios en Inglaterra y Gales de 2014 a 2016 serían ejemplos verificables. Y, si es espacial, puede ser de cualquier dimensión, no solo de una superficie, como las pasas en un pastel. Entiende la idea. William Feller proporciona una aplicación sorprendente de la aproximación espacial de Poisson en su libro clásico sobre teoría de la probabilidad, en el que se encuentran los datos sobre dónde cayeron n = 537 bombas voladoras (cohetes) sobre Londres durante la Segunda Guerra Mundial[31]. Para probar si los aciertos ocurrieron al azar de acuerdo con la distribución de Poisson, el Toda el área del sur de Londres se dividió en M = 576 enclaves de 14 kilómetros cuadrados cada uno, y la siguiente tabla muestra el número de subáreas Mk que sufrieron exactamente k impactos:
 13.53.00.png)
Usando la distribución de Poisson con M = 576 intentos y 537 aciertos y siendo λ el número de aciertos por unidad de área, es decir, n / M 537/576 .9323, y recordando que Pk es aproximadamente Mk / M, se encontró que
 13.53.03.png)
El estrecho acuerdo entre la teoría y los datos exhibidos aquí sugiere que una hipótesis de aciertos aleatorios no se puede excluir a pesar de que un residente en una de las áreas más afectadas podría haber sentido una extraña coincidencia que su vecindario fuera señalado mientras que otras partes de la ciudad salieron ilesas, mientras que un residente de una de estas áreas más afortunadas podría haber razonado que su vecindad se salvó porque allí es donde se escondían los agentes enemigos. La agrupación inesperada de aciertos puede parecer sospechosa a pesar de que tales ráfagas de actividad son características de procesos aleatorios. Lo que muestra un ajuste cercano a la distribución de Poisson es que uno debería estar dispuesto a aceptar que la propensión a que las bombas impacten en una parte de la ciudad sea la misma que en cualquier otra parte. La agrupación que uno observa es simplemente una firma del azar. El mismo razonamiento muestra que no es incompatible con la aleatoriedad tener regiones en México en las que existe una incidencia inusualmente alta de algún cáncer específico. Estos grupos de cáncer ocurren en varias partes del país y llevar a la creencia entre algunos residentes de estas comunidades de que debe haber una fuente antinatural para la tasa de neoplasias más alta de lo habitual, como desechos tóxicos vertidos secretamente en el suministro de agua por industrias locales o agencias gubernamentales que conspiran en una conspiración de silencio. Parece demasiada coincidencia.
Las agencias de salud pública a menudo son engatusadas para que investiguen lo que los residentes de un municipio objetivo consideran con sospecha, sin tener en cuenta el hecho de que hay muchos lugares de este tipo en todo el país, algunos de los cuales pueden ni siquiera saber que alguna tasa de cáncer está por encima del promedio. Una vez más, se trata de ignorar que la probabilidad de que se produzca un cúmulo de este tipo, en algún lugar, no solo en su patio trasero, puede no ser tan pequeña. Como muestra la aproximación de Poisson, es probable que ocurra un clúster en algún lugar y afectará a alguien que no sea usted y su comunidad. Cuando le sucede a usted, induce escepticismo y desconfianza. Un ejemplo más puede ser de interés, ya que se trata de sucesos temporales más que espaciales.
4.12 Ilusiones cognitivas
La cualidad espeluznante de las coincidencias rara vez deja de fascinar y confundir a las personas que las experimentan. Lo que espero mostrar es que muchas, quizás la mayoría, las coincidencias inesperadas son menos sorprendentes de lo que parecen ser. El problema es que hay muchos eventos posibles y no solo los que nos llaman la atención. Tendemos a centrarnos en aquellos que son importantes para nosotros. En efecto, cuando aparece una coincidencia que nos damos cuenta, lo que se ignora aquí es el mayor número de otros eventos que también conducen a coincidencias sorprendentes pero que no pudimos detectar. La fuente de asombro en una extraña coincidencia es nuestra selectividad al elegir aquellos eventos que nos atrapan.
Para una ilustración simple, si lanza dos dados equilibrados idénticos (un cubo con lados numerados del uno al seis), el espacio de posibilidades consta de 36 posibles resultados equi-probables para el número de puntos que aparecen en cada dado. Por alguna razón u otra, está obsesionado con el número tres, tal vez porque su hija cumplió tres hoy. Se lanzan los troqueles. Preguntamos cuál es la probabilidad de obtener el par (3, 3). Aquí solo hay una posibilidad, por lo que la probabilidad de que esto suceda es de 1/36. Sin embargo, esto es diferente de preguntar por la probabilidad de que aparezca el mismo número en cada dado, cualquier número del uno al seis, porque ahora hay seis posibilidades a considerar: (1, 1), (2, 2),…, (6, 6), por lo que la probabilidad de este evento es 6/36 = 1/6 . Aquí hay seis coincidencias, cualquiera de las cuales podría ser especial para alguien. Visto de esta manera, te das cuenta de que la probabilidad de que dos caras salgan iguales no es tan especial después de todo. Los informes selectivos son fuente de coincidencias. El cerebro humano simplemente no puede resistirse a buscar patrones y se apodera de ciertos eventos que considera significativos, ya sea que realmente son[32]. Y al hacerlo, ignora todos los eventos vecinos que lo ayudarían a juzgar qué tan probable o improbable es realmente la coincidencia percibida ". Para proporcionar una guía para los fenómenos de coincidencia, considero primero una generalización del problema familiar de cumpleaños en el que un grupo de k personas se reúnen de manera bastante arbitraria (es decir, al azar) y uno pregunta cuál es la probabilidad de que al menos dos de estos los individuos tienen la misma fecha de nacimiento. Aquí se hace una suposición modesta, que no es del todo cierta, que todos los cumpleaños tienen la misma probabilidad de ocurrir en cualquier día del año, y que un año consta de 365 días. Para hacer el problema más interesante, ampliamos esta pregunta para preguntar, además, cuál es la probabilidad de que al menos dos personas tengan un cumpleaños con no más de un día de diferencia (casi coincidencia).
Estas probabilidades se pueden calcular explícitamente, y esto es lo que encontramos: cuando k es tan pequeño como 23, hay una probabilidad mejor que incluso de que dos o más de estos 23 individuos reporten el misma fecha de nacimiento! En varias ocasiones en las que se probó este experimento en un aula de aproximadamente 30 estudiantes, solo una vez no logramos llegar a un acuerdo sobre las fechas de nacimiento de dos o más personas en la clase. La sorpresa aquí es que la mayoría de los estudiantes creen que se necesitaría una población mucho mayor de individuos para lograr tal concordancia. También es cierto que hay más probabilidades que incluso de que al menos dos personas de un pequeño grupo de 14 tengan el mismo cumpleaños o un cumpleaños con un día de diferencia. El problema del cumpleaños puede parecer sorprendente porque algunas personas que lo escuchan por primera vez responden a la pregunta incorrecta, una que suena superficialmente como el problema del cumpleaños, a saber, "¿cuál es la probabilidad de que alguien más tenga el mismo cumpleaños que el mío?". El problema real es si dos personas en una habitación tienen el mismo cumpleaños, y hay muchas más posibilidades de que esto suceda; nos engañan al pensar en la coincidencia como algo que sucede entre nosotros y otra persona en lugar de entre dos elegidos al azar. Con el fin de demostrar cuán diferente es la probabilidad de que al menos una de las n personas elegidas al azar tenga el mismo cumpleaños que yo, tenga en cuenta que se necesitan n = 253 personas antes de obtener una probabilidad uniforme de coincidencia, y este número encaja mejor con el intuición de la mayoría de las personas que se encuentran por primera vez con el problema del cumpleaños.
Se hace una breve mención de la probabilidad condicional. Recuerde que para dos eventos A y B en el espacio muestral, la probabilidad de A dado que B ha tenido lugar está indicada por Prob (A dado B) que se abrevia a Prob (A | B). Para ello, conviene introducir primero la noción de probabilidades como una forma alternativa y, a veces, más intuitiva de formular preguntas sobre probabilidad. Las probabilidades a favor de un evento A son la razón de Prob (A) a Prob (~ A), donde ~ A indica la negación de A, el conjunto de todas las posibilidades en las que A nunca ocurre. Por lo tanto, las probabilidades (A) = Prob (A) / Prob (~ A). Algunos ejemplos de probabilidades: si el espacio muestral contiene 8 cadenas binarias equiprobables de longitud 3 y A denota el evento que ocurre 010 o 101, entonces aunque la probabilidad de A es 2/8=1/4, las probabilidades de A son 1/4 dividido por 6/8= 3/4, es decir, 1/3 indica un resultado favorable para tres desfavorables. (Nota: estas probabilidades se leen como "uno a tres" y algunas veces se escriben "1:3".) Es fácil calcular que las probabilidades de 1/1 corresponden a una probabilidad de 1/2, las probabilidades de 2/1 coinciden con una probabilidad de 273 y, para un ejemplo más, una probabilidad de 3/7 marca con una probabilidad de 3/10. Es necesario ver más fondo el teorema de Bayes.
Referencias
[1] https://es.wikipedia.org/wiki/Probabilidad_condicionada
[2] Chokr, Nader. (1985). Nelson Goodman: On Truth. Indian Philosophical Qarterly. 12. 163-175.
[3] Borges J.L(2017) Borges esencial. Real Academia Española. Penguin Random House: Barcelona
[4] Lauria, Vincent. (2021). The cult and iconography of the goddess Fortuna in Rome and Latium
[5] Martinez Adame, Carmen. (2015). Breve historia del Ars Conjectandi. Miscelánea Matemática. 60. 1-23.
[6] Moivre, A.. (2020). The Doctrine of Chances: A Method of Calculating the Probabilities of Events in Play. 10.4324/9780203041352.
[7] Chibisov, D.. (2016). Bernoulli's Law of Large Numbers and the Strong Law of Large Numbers. Theory of Probability & Its Applications. 60. 318-319. 10.1137/S0040585X97T987696.
[8] Gordienko, Evgueni. (2021). Andrey Kolmogorov: Eí ultimo gran matemático universal.
[9] Dyson, Ben & Musgrave, Cecile & Rowe, Cameron & Sandhur, Rayman. (2019). Behavioural and neural interactions between objective and subjective performance in a Matching Pennies game. International Journal of Psychophysiology. 147. 10.1016/j.ijpsycho.2019.11.002.
[10] Lipton, Richard. (2013). Charles Bennett: Quantum Protocols. 10.1007/978-3-642-41422-0_63.
[11] Frozen Accidents: Why the Future Is So Unpredictable. https://fs.blog/2016/11/frozen-accidents/
[12] Ullmann, Agnes. (2011). In Memoriam: Jacques Monod (1910–1976). Genome biology and evolution. 3. 1025-33. 10.1093/gbe/evr024.
[13] Gross, P.R.. (2002). The apotheosis of Stephen Jay Gould. The New Criterion. 21. 77-80.
[14] Skelly, David & Post, David & Smith, Melinda. (2010). The Art of Ecology: Writings of G. Evelyn Hutchinson.
[15] Hordijk, Wim. (2019). A History of Autocatalytic Sets: A Tribute to Stuart Kauffman. Biological Theory. 14. 10.1007/s13752-019-00330-w.
[16] Kamberaj, Hiqmet. (2016). Thermodynamics of Biological Phenomena. 10.1007/978-3-030-35702-3_4.
[17] Otto, Sarah. (2018). Adaptation, speciation and extinction in the Anthropocene. Proceedings of the Royal Society B: Biological Sciences. 285. 20182047. 10.1098/rspb.2018.2047.
[18] Novaes, Marcel. (2010). Ilya Prigogine: A critical assessment. Revista Brasileira de Ensino de Física. 32. 1306-1304. 10.1590/S1806-11172010000100006.
[19] Zelinka, Ivan & Sanayei, Ali & Zenil, Hector & Rossler, Otto. (2013). How Nature Works.
[20] Danilova, Tatiana. (2020). Nobel prize winner Erwin Schrodinger: the physicist, philosopher, and godfather of molecular biology and genetics. The Ukrainian Biochemical Journal. 92. 93-100. 10.15407/ubj92.03.093.
[21] Asheim, Lester. (1977). Adventure, Mystery, and Romance: Formula Stories as Art and Popular Culture John G. Cawelti. The Library Quarterly. 47. 83-85. 10.1086/620632.
[22] Seifert, Kim. (2020). Guare, John: Six Degrees of Separation. 10.1007/978-3-476-05728-0_5408-1.
[23] Holzer, Boris. (2019). Watts (1999). Networks, Dynamics, and the Small World Problem. 10.1007/978-3-658-21742-6_129.
[24] https://www.gla.ac.uk/myglasgow/library/files/special/images/exhibitions/month/Bm1/Bm11_6b.jpg
[25] Many Small Events May Add Up to One Mass Extinction (1997) https://www.nytimes.com/1997/09/02/science/many-small-events-may-add-up-to-one-mass-extinction.html
[26] Cox, Edward. (1997). Book Review:How Nature Works: The Science of Self-Organized Criticality. Per Bak. Quarterly Review of Biology - QUART REV BIOL. 72. 10.1086/419866.
[27] Woolley, James. (2017). The circulation of verse in Jonathan Swift’s Dublin. Eighteenth-Century Ireland. 32. 136-150. 10.3828/eci.2017.10.
[28] Berresford, G.: Runs in coin tossing: randomness revealed.
Coll. Math. J. 33, 391–394 (2002)
[29] Bloom, D.: Singles in a sequence of coin tosses. Coll. Math.
J. 29, 120–127 (1998)
[30] Miller, J., Sanjurjo, A.: A bridge from Monty Hall to the hot
hand: the principle of restricted choice. J. Econ. Perspect.
33, 144–162 (2019)
[31] Feller, William. (2015). William Feller and Twentieth Century Probability. 10.1007/978-3-319-16859-3_2.
[32] Johns, Christopher. (2016). It’s Automatic, Isn’t It?. 10.1007/978-1-137-54100-0_4.
Autores:
Eduardo Ochoa Hernández
Nicolás Zamudio Hernández
Berenice Yahuaca Juárez
Erasmo Cadenas Calderón
Abraham Zamudio Durán
Lizbeth Guadalupe Villalon Magallan
Pedro Gallegos Facio
Gerardo Sánchez Fernández
Rogelio Ochoa Barragán
Monica Rico Reyes