Texto universitario

_____________________________
Módulo 6. Estadística bayesiana
6.1 Frecuentistas versus Bayesianos: la estadística moderna
A veces, a la luz de la nueva evidencia empírica, nos damos cuenta de que estábamos a la sombra del árbol equivocado. Otras veces simplemente refinamos una idea que resulta no estar equivocada, sino solo es una aproximación más que mejora para obtener una imagen más precisa de la realidad. Hay algunas áreas de la física fundamental con las que podríamos no estar del todo contentos, alli sabemos en el fondo que no hemos escuchado la última palabra, pero en las que, sin embargo, seguimos confiando por el momento porque son útiles. Un buen ejemplo de esto es la ley universal de la gravitación de Newton. Todavía se le conoce, grandilocuente, como una “ley” porque los científicos de la época estaban tan seguros de que era la última palabra sobre el tema, la elevaron en su estatus por encima de una mera “teoría”. El nombre se mantuvo, a pesar del hecho de que ahora sabemos que su confianza estaba fuera de lugar. La teoría general de la relatividad de Einstein (nótese que se llama teoría) reemplazó a la ley de Newton, porque nos da una explicación más profunda y precisa de la gravedad. Y, sin embargo, todavía usamos las ecuaciones de Newton para calcular las trayectorias de vuelo de las misiones espaciales. Las predicciones de la mecánica newtoniana pueden no ser tan precisas como las de la relatividad de Einstein, pero siguen siendo lo suficientemente buenas para casi todos los propósitos cotidianos.
Más que cualquier otra disciplina científica, la física progresa a través de la interacción continua entre la teoría y el experimento. Las teorías solo sobreviven a la prueba del tiempo mientras sus predicciones continúen siendo verificadas por experimentos. Una buena teoría es aquella que hace nuevas predicciones que se pueden probar en el laboratorio, pero si esos resultados experimentales entran en conflicto con la teoría, entonces tiene que ser modificada, o incluso descartada. Por el contrario, los experimentos de laboratorio pueden apuntar a fenómenos inexplicables que requieren nuevos desarrollos teóricos. Solo en la ciencia vemos esta asociación tan hermosa. Los teoremas en matemáticas puras se prueban con la lógica, la deducción y uso de verdades axiomáticas. No requieren validación en el mundo real. En contraste, la geología o la psicología del comportamiento son en su mayoría ciencias de la observación en las que los avances muestran comprensión y se realizan a través de la cuidadosa recopilación de datos del mundo natural, o a través de evidencias de laboratorio cuidadosamente diseñadas. Pero la ciencia puede progresar cuando la teoría y la experimentación trabajan de la mano en inferencias, cada una tirando arriba y apuntando al siguiente punto de apoyo hasta el acantilado. Existen dos escuelas de pensamiento predominantes para llevar a cabo este proceso de inferencia: frecuentista y bayesiana.
En las estadísticas frecuentistas o clásicas, suponemos que la muestra de datos es el resultado dentro de un número infinito de experimentos exactamente repetidos. Se supone que la muestra que vemos en este contexto es el resultado de algún proceso probabilístico. Cualquier conclusión que saquemos de este enfoque se basa en la suposición de que los eventos ocurren con probabilidades, que representan las frecuencias a largo plazo con las que ocurren esos eventos en una serie infinita de repeticiones experimentales. Por ejemplo, si lanzamos una moneda, tomamos la proporción de caras observadas en un número infinito de lanzamientos como la definición de la probabilidad de obtener caras. Los frecuentistas suponen que esta probabilidad realmente existe, y es fija para cada conjunto de lanzamientos de monedas que llevamos a cabo. La muestra de lanzamientos de monedas que obtenemos para un número fijo y finito de lanzamientos se genera como si fuera parte de una serie más larga (es decir, infinita) de lanzamientos repetidos de monedas.
En la estadística frecuentista, se supone que los datos son aleatorios y son resultados del muestreo de una distribución de población fija y definida. Para un frecuentista, el ruido que oscurece la verdadera señal del proceso de la población real es atribuible a la variación del muestreo: el hecho de que cada muestra que elegimos es ligeramente diferente y no es exactamente representativa de la población. Considere que podemos lanzar nuestra moneda 10 veces, obteniendo 7 caras incluso si la proporción a largo plazo de caras es 1/2. Para un frecuentista, esto se debe a que hemos elegido una muestra un poco inadecuada de la población de muchos lanzamientos repetidos. Si lanzamos la moneda otra 10 veces, es probable que obtengamos un resultado diferente porque luego elegimos una muestra diferente.
Los bayesianos no imaginan repeticiones de un experimento para definir y especificar una probabilidad. Una probabilidad se toma simplemente como una medida de certeza en una creencia particular. Para los bayesianos, la probabilidad de lanzar una “cara”, mide y cuantifica nuestra creencia subyacente antes de lanzar la moneda que aterrizará de esta manera. En este sentido, los bayesianos no ven las probabilidades como leyes subyacentes de causa y efecto. Son meras abstracciones que utilizamos para ayudar a expresar nuestra incertidumbre. En este marco de referencia, no es necesario que los eventos sean repetibles para definir una probabilidad. Por lo tanto, somos igualmente capaces de decir: la probabilidad de una cara sea de 0.5. La probabilidad se ve simplemente como una escala de 0 a, donde estamos seguros de que un evento no sucederá, a 1, donde estamos seguros de que sucederá.
Para los bayesianos, las probabilidades son vistas como una expresión de creencias subjetivas, lo que significa que pueden actualizarse a la luz de nuevos datos. La fórmula inventada por el reverendo Thomas Bayes proporciona la única manera lógica de llevar a cabo este proceso de actualización. La regla de Bayes es fundamental para la inferencia bayesiana mediante la cual usamos probabilidades para expresar nuestra incertidumbre en los valores de los parámetros después de observar los datos.
Los bayesianos asumen que, ya que somos testigos de los datos, son fijos, y por lo tanto no varían. No necesitamos imaginar que hay números infinitos de muestras posibles, o que nuestros datos son el resultado indeterminado de algún proceso aleatorio de muestreo. Nunca sabemos perfectamente el valor de un parámetro desconocido (por ejemplo, la probabilidad de que una moneda aterrice cara). Esta incertidumbre epistémica (es decir, la relacionada con nuestra falta de conocimiento) significa que en la inferencia bayesiana el parámetro se ve como una cantidad que es de naturaleza probabilística. Podemos interpretar esto de una de dos maneras. Por un lado, podemos ver el parámetro desconocido como verdaderamente fijo en algún sentido absoluto, pero nuestras creencias son inciertas, y por lo tanto expresamos esta incertidumbre usando la probabilidad. En esta perspectiva, vemos la muestra como una representación ruidosa de la señal y, por lo tanto, obtenemos resultados diferentes para cada conjunto de lanzamientos de monedas. Por otro lado, podemos suponer que no hay alguna probabilidad definitiva e inmutable de obtener una cara, por lo que por cada muestra que tomamos, sin saberlo, obtenemos un parámetro ligeramente diferente. Aquí obtenemos resultados diferentes de cada ronda de lanzamientos de monedas porque cada vez sometemos a nuestro sistema a una probabilidad ligeramente diferente de su aterrizaje cara a cara. Esto podría deberse a que alteramos nuestra técnica de lanzamiento o comenzamos con la moneda en una posición diferente. Aunque estas dos descripciones son diferentes filosóficamente, no son diferentes matemáticamente, lo que significa que podemos aplicar el mismo análisis a ambas.
Para los bayesianos, los parámetros del sistema se toman por variables, mientras que la parte conocida del sistema -los datos- se toma como dado. Los estadísticos frecuentistas por otro lado, ven la parte invisible del sistema -los parámetros del modelo de probabilidad- como fija y las partes conocidas del sistema -los datos- como variables. Cuál de estas visiones preferir, se reduce a cómo interpretar los parámetros de un modelo estadístico.
En el enfoque bayesiano, los parámetros se pueden ver desde dos perspectivas. O bien vemos los parámetros como realmente variables, o vemos nuestro conocimiento sobre los parámetros como imperfectos. El hecho de que obtengamos diferentes estimaciones de parámetros de diferentes estudios puede tomarse para reflejar cualquiera de estos dos puntos de vista.
En el primer caso, comprendemos que los parámetros de interés varían, tomando valores diferentes en cada una de las muestras que elegimos. Por ejemplo, supongamos que realizamos un análisis de sangre a un individuo en dos semanas consecutivas, y representamos la correlación entre el recuento de glóbulos rojos y blancos como un parámetro de nuestro modelo estadístico. Debido a los muchos factores que afectan el metabolismo del cuerpo, el recuento de cada tipo de célula variará un poco al azar, y por lo tanto del parámetro puede variar con el tiempo. En el segundo caso, vemos muestras de incertidumbre sobre el valor de un parámetro como la razón por la que estimamos valores ligeramente diferentes en diferentes muestras. Sin embargo, esta incertidumbre debería disminuir a medida que recopilamos más datos. Los bayesianos se inclinan más en el uso de parámetros como un medio para un fin, tomándolos no como constantes inmutables reales, sino como herramientas para ayudar a hacer inferencias sobre una situación dada.
La perspectiva frecuentista es menos flexible y asume que estos parámetros son constantes, o representan el promedio a un largo plazo -típicamente un número infinito- de experimentos idénticos. Hay ocasiones en las que podríamos pensar que se trata de una suposición razonable. Por ejemplo, si nuestro parámetro representó la probabilidad de que un individuo tomado al azar de la población de México tenga dislexia, es razonable suponer que hay un valor de población verdadero, o fijo, del parámetro en cuestión. Mientras la visión frecuentista puede ser razonable aquí, la visión bayesiana también puede manejar esta situación. En la estadística bayesiana estos parámetros se pueden suponer fijos, pero no se está seguro de su valor (aquí la verdadera prevalencia de la dislexia) antes de medirlos, y utiliza una distribución de probabilidad para reflejar esta incertidumbre.
Pero hay circunstancias en las que la visión frecuentista se encuentra en problemas. Cuando estamos estimando parámetros de una distribución compleja, normalmente, no los vemos como realmente existentes. A menos que vea el Universo como construido a partir de bloques de construcción matemático; entonces, parece incorrecto afirmar que un parámetro dado tiene una existencia más profunda que aquella con la que lo dotamos. La perspectiva bayesiana menos restrictiva aquí parece más razonable.
La visión frecuentista de los parámetros como un valor limitante de un promedio a través de una infinidad de experimentos idénticamente repetidos también tiene dificultades cuando pensamos en eventos únicos e irrepetibles en su contexto, por ejemplo, las elecciones electorales en una democracia.
El proceso de inferencia bayesiana es la única forma lógica y consistente de modificar nuestras creencias teniendo en cuenta nuevos datos. Antes de recopilar datos, tenemos una descripción probabilística de nuestras creencias, que llamamos a priori o anterior. Luego recopilamos datos, y junto con un modelo que describe nuestra teoría, la fórmula de Bayes nos permite calcular nuestros postdatos o creencia posterior. En la inferencia, queremos sacar conclusiones basadas puramente en las reglas de la probabilidad. Si queremos resumir nuestra evidencia para una hipótesis en particular, describimos esto utilizando lenguaje de probabilidad, como “la probabilidad de la hipótesis dados los datos obtenidos”. La dificultad es que cuando elegimos un modelo de probabilidad para describir una situación, nos permite calcular la “probabilidad de obtener nuestros datos dado que nuestras hipótesis es verdadera”, lo contrario de lo queremos. Esta probabilidad se calcula teniendo en cuenta todas las muestras posibles que se podrían haber obtenido de la inferencia estadística, común tanto a los frecuentistas como a los bayesianos, es como invertir esta probabilidad para obtener el resultado deseado.
Los frecuentistas se detienen aquí, usando esta probabilidad inversa como evidencia para una hipótesis dada. Asumen una hipótesis como cierta y sobre esta base calculan la probabilidad de obtener la muestra de datos observados. Si esta probabilidad es pequeña, entonces se asume que es poco probable que la hipótesis sea cierta, y la rechazan. Por ejemplo, si lanzamos la moneda 10 veces y siempre aterriza en cada lanzamiento cara, la probabilidad de que estos datos ocurran dado que la moneda es justa (la hipótesis), es pequeña. En este caso, los frecuentistas rechazaran la hipótesis de que la moneda es justa. Esencialmente, esto equivale a establecer P(Hipótesis|datos)=0. Sin embargo, si esta probabilidad no está por debajo de algún umbral arbitrario, entonces no rechazamos la hipótesis. Pero la inferencia frecuentista no está clara sobre qué probabilidad debemos atribuir a la hipótesis. No cabe duda de que no es cero, pero, ¿hasta qué punto confiamos exactamente en ello? En la inferencia frecuentista no obtenemos una acumulación de evidencia para una hipótesis en particular, a diferencia de la estadística bayesiana.
En realidad, la inferencia frecuentista es ligeramente diferente a lo que describimos. Dado que la probabilidad de obtener cualquier muestra de datos específica es muy pequeña, se calcula la probabilidad de obtener un rango de muestras posibles para obtener una probabilidad más utilizable. En particular, los frecuentistas calculan la probabilidad de obtener una muestra tan extrema o más extrema que la realmente obtenida, suponiendo que una determinada hipótesis sea cierta.
La fórmula de Bayes nos permite sortear estas dificultades invirtiendo la probabilidad frecuentista para obtener la probabilidad de la hipótesis dados los datos reales que obtuvimos. En la inferencia bayesiana no hay necesidad de un umbral arbitrario en la probabilidad para validar la hipótesis (posterior) y no hay necesidad de pruebas de hipótesis explícitas. Sin embargo, para usar la regla de Bayes para la inferencia, debemos proporcionar un elemento a priori, un elemento adicional en comparación con las estadísticas frecuentistas. El a priori es una distribución de probabilidad que describe nuestras creencias en una hipótesis antes de recopilar y analizar los datos. En la inferencia bayesiana, luego actualizamos esta creencia post analítica en la hipótesis.
La regla de Bayes nos dice cómo actualizar nuestras creencias anteriores para derivar creencias mejores y más informadas sobre una situación a la luz de los nuevos datos. En la inferencia bayesiana, probamos hipótesis sobre el mundo real usando estas creencias posteriores. Como parte parte de este proceso, estimamos características que nos interesan, que llamamos parámetros, que luego se utilizan para probar tales hipótesis. A partir de este punto usaremos el símbolo de 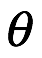 para expresar los parámetros desconocidos que queremos estimar.
para expresar los parámetros desconocidos que queremos estimar.
El proceso de inferencia bayesiana utiliza la regla de Bayes para estimar una distribución de probabilidad para esos parámetros desconocidos después de observar los datos. Por ahora es suficiente pensar en las distribuciones de probabilidad como una forma de representar la incertidumbre para cantidades desconocidas.
La regla de Bayes, tal como se usa en la inferencia estadística, es de la forma:
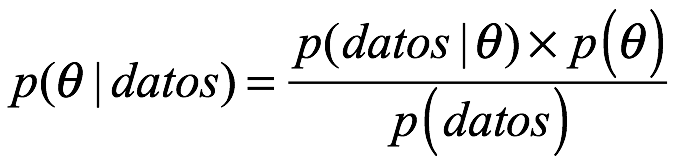
Donde usamos p para indicar una distribución de probabilidad que puede representar probabilidades o, más usualmente, densidad de probabilidad. En el numerador en el lado derecho de la expresión 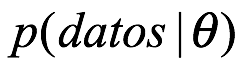 , lo llamamos la probabilidad, que es común tanto a los frecuentista como a los bayesianos. Esto nos dice la probabilidad de generar la muestra particular de datos si los parámetros en nuestro modelo estadístico fueran iguales a
, lo llamamos la probabilidad, que es común tanto a los frecuentista como a los bayesianos. Esto nos dice la probabilidad de generar la muestra particular de datos si los parámetros en nuestro modelo estadístico fueran iguales a 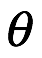 . Cuando elegimos un modelo estadístico, generalmente podemos calcular la probabilidad de resultados particulares, por lo que esto se obtiene fácilmente. Imagine que tenemos una moneda que creemos que es justa. Por justo, queremos decir que la probabilidad de que la moneda aterrice es
. Cuando elegimos un modelo estadístico, generalmente podemos calcular la probabilidad de resultados particulares, por lo que esto se obtiene fácilmente. Imagine que tenemos una moneda que creemos que es justa. Por justo, queremos decir que la probabilidad de que la moneda aterrice es 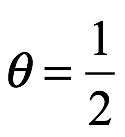 . Si lanzamos la moneda dos veces, podríamos suponer que los resultados son eventos independientes y por lo tanto podemos calcular las probabilidades de los cuatro resultados posibles multiplicando las probabilidades de los resultados individuales:
. Si lanzamos la moneda dos veces, podríamos suponer que los resultados son eventos independientes y por lo tanto podemos calcular las probabilidades de los cuatro resultados posibles multiplicando las probabilidades de los resultados individuales:
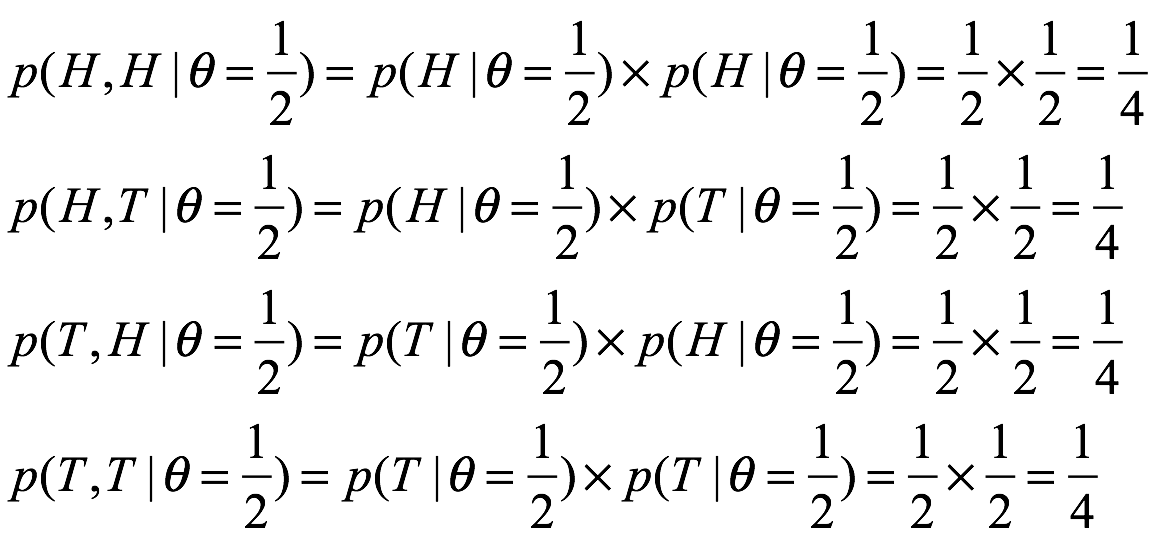
Antecedente o a priori
El siguiente término en el numerador de la expresión es 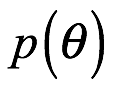 , es la parte más controvertida de la fórmula bayesiana, que llamamos distribución a priori o antecedente. Es una distribución de probabilidad que representa nuestras creencias previas a los datos a través de diferentes volares de los parámetros de nuestro modelo,
, es la parte más controvertida de la fórmula bayesiana, que llamamos distribución a priori o antecedente. Es una distribución de probabilidad que representa nuestras creencias previas a los datos a través de diferentes volares de los parámetros de nuestro modelo, 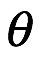 . Esto parece, al principio, ser contradictorio, especialmente si está familiarizado con el mundo de la estadística frecuentista y sus valores
. Esto parece, al principio, ser contradictorio, especialmente si está familiarizado con el mundo de la estadística frecuentista y sus valores 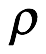 , que no requiere que declaremos nuestras creencias explícitamente (aunque siempre lo hacemos explícitamente, como lo discutiremos más adelante). Continuando con nuestro ejemplo de una moneda justa sesgada de antemano, por lo que supongamos que todos los valores posibles de
, que no requiere que declaremos nuestras creencias explícitamente (aunque siempre lo hacemos explícitamente, como lo discutiremos más adelante). Continuando con nuestro ejemplo de una moneda justa sesgada de antemano, por lo que supongamos que todos los valores posibles de 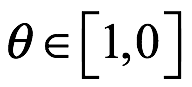 , que representa la probabilidad de que la moneda caiga de cara, son igualmente probables. Podemos representar estas creencias mediante una densidad de probabilidad uniforme continua en este intervalo. Sin embargo de manera más sensata, podríamos creer que las monedas se fabrican de tal manera que su distribución de peso se distribuye de manera bastante uniforme, lo que significa que esperamos que la mayoría de las monedas sean razonablemente justas. Estas creencias estarían representadas más adecuadamente por un a priori similar al que que muestra la línea roja de la figura siguiente:
, que representa la probabilidad de que la moneda caiga de cara, son igualmente probables. Podemos representar estas creencias mediante una densidad de probabilidad uniforme continua en este intervalo. Sin embargo de manera más sensata, podríamos creer que las monedas se fabrican de tal manera que su distribución de peso se distribuye de manera bastante uniforme, lo que significa que esperamos que la mayoría de las monedas sean razonablemente justas. Estas creencias estarían representadas más adecuadamente por un a priori similar al que que muestra la línea roja de la figura siguiente:
 23.30.58.png)
Podemos ver dos distribuciones diferentes, una previa uniforme, donde creemos que todos los valores de 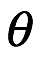 que corresponden a la probabilidad de lanzar una cara son igualmente probables (línea negra), y otra línea roja, donde creemos que la moneda es más probable que sea ligeramente no justa antes de lanzarla.
que corresponden a la probabilidad de lanzar una cara son igualmente probables (línea negra), y otra línea roja, donde creemos que la moneda es más probable que sea ligeramente no justa antes de lanzarla.
El término final en el lado derecho de la expresión en el denominador p(datos). Esto representa la probabilidad de obtener nuestra muestra particular de datos si asumimos un modelo particular y previo. Por el momento basta con decir que el denominador esta completamente determinado por nuestra elección de la función previa y de probabilidad. Si bien parece simple, esto es engañoso, y es en parte la dificultad con el cálculo de este término lo que lleva a la introducción de métodos computacionales que veremos más adelante.
El posterior, es el objetivo de la inferencia bayesiana. La distribución de probabilidad posterior , es nuestro propósito. Por ejemplo, podríamos querer calcular la distribución de probabilidad que representa nuestras creencias post-experimentales del seno inherente,
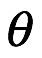 , de una moneda, dado que se volteó 10 veces y aterrizó 7 veces de cara. Si usamos la regla de Bayes, asumimos el modelo de probabilidad especificado
, de una moneda, dado que se volteó 10 veces y aterrizó 7 veces de cara. Si usamos la regla de Bayes, asumimos el modelo de probabilidad especificado
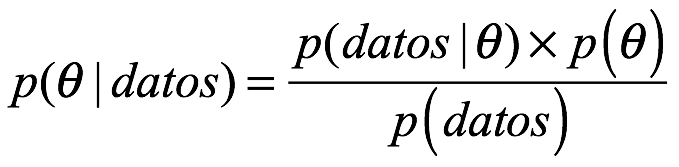
Y el a priori uniforme de linea negra
Entonces, el resultado es la distribución posterior que se muestra como la linea gris en del siguiente gráfico
 16.17.30.png)
Aquí, el pico de al distribución ocurre en 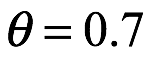 , que corresponde exactamente con el porcentaje de caras obtenidas en el experimento (la línea gris representa una distribución de probabilidad posterior (PDF)). Ambos posteriores PDF rojo y gris asumen una probabilidad binomial.
, que corresponde exactamente con el porcentaje de caras obtenidas en el experimento (la línea gris representa una distribución de probabilidad posterior (PDF)). Ambos posteriores PDF rojo y gris asumen una probabilidad binomial.
La distribución posterior resume nuestra incertidumbre sobre el valor de un parámetro. Si la distribución es más estrecha, entonces esto indica que tenemos mayor confianza en nuestras estimaciones de valores de parámetros. Se pueden obtener distribuciones posteriores más estrechas mediante la recopilación de más datos. En la figura anterior comparamos la distribución posterior para el caso anterior donde 7 de cada 10 veces la moneda aterrizó en cara con una muestra nueva; en una más grande, donde 70 de cada 100 veces la misma moneda aterriza cara. En ambos casos, obtuvimos la misma relación de caras y cruces, resultado en el mismo valor pico en 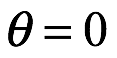 . Sin embargo, en este último caso, dado que tenemos más evidencia para apoyar nuestra afirmación, terminamos con una mayor certeza sobre el valor del parámetro después del experimento. La distribución posterior también se utiliza para predecir los resultados futuros de un experimento y para las pruebas de modelos.
. Sin embargo, en este último caso, dado que tenemos más evidencia para apoyar nuestra afirmación, terminamos con una mayor certeza sobre el valor del parámetro después del experimento. La distribución posterior también se utiliza para predecir los resultados futuros de un experimento y para las pruebas de modelos.
Subjetividad implícita versus explícita
Uno de los principales argumentos en contra de la estadística bayesiana es que es subjetiva debido a su dependencia del observador que especifica sus creencias pre-experimentales a través de los a priori. Se dice que este prejuicio del experimentador hacia ciertos resultados sesga los resultados de los tipos de resultados justos y objetivos resultantes de un análisis frecuentista.
Argumentos que todos los análisis implican un grado de subjetividad, que se declara explícitamente o, más a menudo, se asume implícitamente. En un análisis frecuentista, el estadístico típicamente selecciona un modelo de probabilidad que depende de un arma de posiciones. Estas suposiciones a menudo se justifican explícitamente, revelando su naturaleza sugerente. Por ejemplo, el modelo de regresión lineal simple se utiliza a menudo, sin justificación, en los análisis frecuentistas aplicados. Este modelo hace suposiciones sobre las relaciones entre las viables dependientes e independientes que pueden, o no, ser ciertas. En un enfoque bayesiano, construimos típicamente nuestros modelos desde cero, lo que significa que solo más conscientes de las suposiciones inherentes al enfoque.
En la investigación aplicada, existe una tendencia entre los científicos a elegir datos para incluir en su análisis que se adapten a las necesidades de uno, aunque esta práctica realmente debe desalentarse. La elección de qué puntos de datos incluir es subjetiva, y la lógica subyacente detrás de esta elección a menudo se mantiene opaca para el lector del artículo científico.
Otra fuente de subjetividad es la forma en que se comprueban y prueban los modelos. En los análisis, tanto frecuentistas como bayesianos, existe la necesidad de ejercer un juicio (subjetivo) al sugerir un metodología que se utilizará en este proceso. Argumentamos que el análisis bayesiano permite una mayor flexibilidad y una metodología más adecuada para este proceso porque explica la incertidumbre inherente en nuestras estimaciones.
En contraste, los priores bayesianos se declarar explícitamente. Esto hace que esta parte del análisis esté abiertamente disponible para el lector, lo que significa que puede ser interrogado y debatido. Esta naturaleza transparente de las estadísticas bayesianas ha llevado a algunos a sugerir que es honesta. Mientras que los análisis frecuentistas se esconden detrás de un falso velo de objetividad, los bayesianos reconocen explícitamente la naturaleza subjetiva del conocimiento.
Además, cuanto más datos se recopilen (en general), n menor será el impacto que el anterior ejerce sobre las distribuciones posteriores. En cualquier caso, si una ligera modificación de los antecedentes (priores) resulta en que se llegue a una conclusión diferente, debe ser informada por el investigador.
Finalmente, comparando los enfoques frecuentista y bayesiano con la búsqueda del conocimiento, encontramos que ambos enfoques requieren un juicio subjetivo para ser hechos. En cada caso, queremos obtener 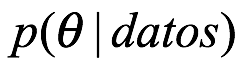 la probabilidad del parámetro o hipótesis bajo investigación, dado el conjunto de datos que se ha observado. En las pruebas de hipótesis frecuentistas no calculamos esta cantidad directamente, sino que usamos una regla general. Calculamos la probabilidad de que el conjunto de datos, de hecho, hubiera sido más extremo que los que realmente obtuvimos asumiendo que una hipótesis nula (dada por defecto) es verdadera. Si la probabilidad es lo suficientemente pequeña, normalmente menor que un corte de 5% o 1%, luego rechazamos el nulo. Esta elección de la probabilidad umbral, conocida como el tamaño de una prueba estadística, es completamente arbitraria y subjetiva. En la estadística bayesiana, en su lugar, usamos un subjetivo entes de invertir la probabilidad de
la probabilidad del parámetro o hipótesis bajo investigación, dado el conjunto de datos que se ha observado. En las pruebas de hipótesis frecuentistas no calculamos esta cantidad directamente, sino que usamos una regla general. Calculamos la probabilidad de que el conjunto de datos, de hecho, hubiera sido más extremo que los que realmente obtuvimos asumiendo que una hipótesis nula (dada por defecto) es verdadera. Si la probabilidad es lo suficientemente pequeña, normalmente menor que un corte de 5% o 1%, luego rechazamos el nulo. Esta elección de la probabilidad umbral, conocida como el tamaño de una prueba estadística, es completamente arbitraria y subjetiva. En la estadística bayesiana, en su lugar, usamos un subjetivo entes de invertir la probabilidad de 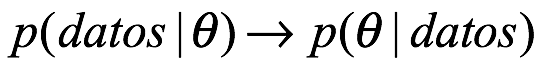 . No hay necesidad de aceptar o rechazar una hipótesis nula y considerar una alternativa, ya que toda la información está perfectamente resumida en la parte posterior. De esta manera, vemos una simetría en la elección del tamaño de la prueba frecuentista y los priores bayasianos; ambos están obligados a invertir la probabilidad de obtener un posterior.
. No hay necesidad de aceptar o rechazar una hipótesis nula y considerar una alternativa, ya que toda la información está perfectamente resumida en la parte posterior. De esta manera, vemos una simetría en la elección del tamaño de la prueba frecuentista y los priores bayasianos; ambos están obligados a invertir la probabilidad de obtener un posterior.
La inferencia estadística es el proceso requerido para pasar de un efecto (los datos) a una causa (el proceso o los parámetros). El problema con esta inversión es que generalmente es más fácil hacer las cosas al revés: pasar de una causa a un efecto. Los frecuentistas y bayesianos comienzan definiendo un modelo de probabilidad hacia adelante que puede generar datos (el efecto) a partir de un conjunto dado de parámetros (la causa). El método que cada uno de ellos utiliza para ejecutar este modelo a la inversa y determinar la probabilidad de una causa es diferente. Los frecuentistas asumen que si la probabilidad de generar los datos (en realidad datos tan extremos o más extremos que los obtenidos) a partir de una causa particular si es pequeña, entonces es un intervalo con cierta confianza que contiene la causa real con cierta medida de certeza. Los bayesianos en cambio llevan a cabo la inversión formalmente usando la regla de Bayes. Esto resulta en una acumulación de evidencia para cada causa, en lugar de un binario “si” o “no” como para el caso frecuentista.
Los frecuentistas y bayesianos también difieren en su punto de vista sobre las probabilidades. Los frecuentistas ven las probabilidades como la frecuencia a la que ocurre un evento en una serie infinita de repeticiones experimentales. En este sentido, los frecuentistas ven las probabilidades como leyes fijas que realmente existen independientemente del analista individual. Del mismo modo, en el punto de vista frecuentista, no tiene sentido definir probabilidades para eventos únicos, donde no es posible una serie infinita de reproducciones experimentales. Los bayesianos tienen una visión más general sobre las probabilidades. Ven las probabilidades como la medición de la fuerza de la creencia subyacente de un individuo, en la probabilidad de algún resultado. Para los bayesianos, las probabilidades solo se definen en relación con un analista particular y, por lo tanto, por su propia naturaleza, son subjetivas. Dado que las probabilidades miden las creencias, se pueden actualizar a la luz de nuevos datos. La única forma correcta de actualizar las probabilidades es a través de la regla de Bayes, que los bayesianos usan para hacer inferencia estadística. Debido a que las probabilidades bayesianas miden una creencia subjetiva en un resultado, desde aquellos que de alguna manera podrían repetirse infinitamente (por ejemplo lanzando una moneda) o eventos únicos ( por ejemplo, como las elecciones de gobernador).
Un argumento que a menudo se aplica contra el enfoque bayesiano de la inferencia, es que son subjetivos, en contraste con la objetividad supuesta de los frecuentistas. Argumentamos que todos los enfoques analíticos de la inferencia son inherentemente subjetivas en algún nivel. Comenzando por el proceso de selección de datos muestra, el analista a menudo hace un subjetivo juicio de qué datos incluir. La elección de un modelo de probabilidad específico también es inherentemente sugestivo y generalmente se justifica haciendo suposiciones sobre el proceso de generación de datos. En la inferencia frecuentista, la elección de la probabilidad umbral para la prueba de hipótesis nula también es arbitraria e inherentemente en un análisis. Que los priores se indiquen explícitamente significa que pueden ser debatidos e interrogados de manera transparente. Si buen los priores son inherentemente subjetivos, esto no significa que no pueden ser informados por los datos. De hecho, en los análisis que se repiten en diferentes puntos en el tiempo, a menudo tiene sentido utilizar el posterior de una análisis anterior como previo para uno nuevo. La fórmula de Bayes es el dogma central de la inferencia bayesiana. Sin embargo, para utilizar esta regla para los análisis estadísticos, es necesario comprender y, lo que es más importante, ser capaz de manipular las distribuciones de probabilidad.
Hay algunas ideas que estimamos que son verdaderas, y otras que sabemos que son falsas. Pero la mayoría de las ideas, no podemos estar seguros de ninguna manera; en estos casos, decimos que no estamos seguros. Y la forma correcta de cuantificar nuestra incertidumbre es utilizando el lenguaje de la probabilidad. En este sentido, la inferencia bayesiana utiliza la teoría de la probabilidad para permitirnos actualizar nuestras creencias inciertas a la luz de los datos.
Para comprender estos objetos abstractos, las distribuciones de probabilidad, primero definimos explícitamente lo que se entiende por ello. Este ejercicio es útil ya que la inferencia bayesiana intenta invertir una probabilidad, en sí misma no una distribución de probabilidad valida, por contrario, obtener una distribución probabilidad valida que llamamos posterior.
Antes de mirar por la ventana por la mañana, antes de obtener los resultados de nuestros exámenes de consciencia, antes de que se repartan las cartas del destino, no estamos seguros del mundo que nos espera. Para planificar y dar sentido a las cosas, queremos, queremos utilizar un marco adecuado para describir loa incertidumbre inherente a una variedad de situaciones. El uso de un marco particular para declarar explícitamente nuestros pensamientos, ilumina nuestro proceso de pensamiento y permite a otros interrogar nuestras suposiciones.
Variables de probabilidad y distribuciones de probabilidad
La teoría matemática de la probabilidad proporciona una lógica y un lenguaje que es el único marco completamente consistente para describir situaciones que involucran incertidumbre. La teórica de la probabilidad, describe el comportamiento de las variables aleatorias. Este es un término estadístico para las variables que asocian diferentes valores numéricos con cada uno de los posibles resultados de algún proceso aleatorio. Por aleatorio aquí no nos referimos al uso coloquial de este término para asignar algo que es completamente impredecible. Un proceso aleatorio es simplemente un proceso cuyo resultado no puede conocerse perfectamente de antemano (sin embargo, puede ser bastante predecible). Entonces, para un lanzamiento de una moneda, podemos crear una variable aleatoria “X” que toma el valor 1 si la moneda aterriza de cara y 0 para si aterriza cruz. Porque el lanzamiento del moneda puede producir solo un número contable de resultado (es este caso dos), “X” es una variable aleatoria discreta. Por el contrario, supongamos que medimos el peso de un individuo “Y”. En este caso, “Y” es una variable aleatoria continua, porque en principio puede tomar cualquier número real positivo. ¿Qué es una distribución de probabilidad?
6.2 Distribución estadística
Una distribución estadística es una función matemática que define cómo los resultados de un ensayo experimental ocurren aleatoriamente de una manera probable. Los resultados se denominan variables aleatorias y su región admisible se encuentra en un espacio muestral específico que está asociado con cada distribución individual. Las distribuciones estadísticas son principalmente de dos tipos: continuas y discretas. Las distribuciones de probabilidad continua se aplican cuando la variable aleatoria puede caer entre dos límites, como la cantidad de agua de lluvia que se acumula en un recipiente de cinco galones después de una lluvia. La distribución de probabilidad discreta se aplica cuando los resultados del experimento son valores específicos, como el número de puntos que aparecen en una tirada de dos dados. Las distribuciones también pueden clasificarse como univariadas o multivariadas. El univariado es cuando la distribución tiene solo una variable aleatoria; multivariado es cuando dos o más variables aleatorias están asociadas con la distribución. Las distribuciones estadísticas de este libro pertenecen a las distribuciones de probabilidad univariadas continuas y discretas de uso común, y a las distribuciones estadísticas continuas bivariadas aplicadas con mayor frecuencia, donde las distribuciones bivariadas tienen dos variables aleatorias relacionadas conjuntamente.
6.2.1 Distribuciones de probabilidad, variables aleatorias, notación y parámetros
Las distribuciones con la designación y los parámetros de cada una se enumeran a continuación:
Distribuciones continuas:
Uniforme continuo x ~ CU (a, b)
Exponencial x ~ Exp (θ)
Erlang x ~ Erl (k, θ)
Gamma x ~ Gam (k, θ)
Beta x ~ Beta (k1, k2, a, b)
Weibull x ~ We (k1, k2, γ)
Normal x ~ N (μ, σ2)
Lognormal x ~ LN (μy, σy2)
Normal truncado a la izquierda t ~ LTN (k)
Normal truncado a la derecha t ~ RTN (k)
Triangular x ~ TR (a, b, ~ x)
Distribuciones discretas:
Uniforme discreto x ~ DU (a, b)
Binomio x ~ Bin (n, p)
Geométrico x ~ Ge (p)
Pascal x ~ Pa (k, p)
Híper geométrico x ~ HG (n, N, D)
Poisson x ~ Po (θ)
Distribuciones bivariadas:
Normal bivariado x1, x2 ~ BVN (μ1, μ2, σ1, σ2, ρ)
Lognormal bivariado x1, x2 ~ BVLN (μy1, μy2, σy1, σy2, ρy)
Las distribuciones continuas, con un resumen de cada una, son las siguientes:
Uniforme continuo: la densidad es horizontal en todas partes.
Exponencial: la densidad alcanza su punto máximo en cero y luego desciende.
Erlang: muchas formas que van desde exponenciales a normales.
Gamma: muchas formas que van desde exponenciales a normales.
Beta: muchas formas que se inclinan hacia la izquierda, la derecha, la bañera y simétrico.
Weibull: muchas formas, desde exponenciales hasta normales.
Normal: campana simétrica.
Lognormal: picos cerca de cero y sesgos de extrema derecha.
Normal truncado a la izquierda: lo normal se trunca a la izquierda y se inclina hacia la derecha.
Truncado a la derecha normal: normal se trunca a la derecha y se sesga a la izquierda.
Triangular: la densidad aumenta a un pico y luego baja a cero.
Las distribuciones discretas, con un resumen de cada una, son las siguientes:
Uniforme discreto: la probabilidad es horizontal en todo momento.
Binomial: n ensayos con probabilidad constante de éxito por ensayo.
Geométrico: número de intentos hasta el éxito.
Pascal: número de ensayos hasta k éxitos.
Poisson: número de eventos cuando la tasa de eventos es constante.
Hipergeométrico: n muestras sin reemplazo de un lote de tamaño N.
Las distribuciones bivariadas, con un breve resumen, son las siguientes:
Normal bivariante: las distribuciones marginales tienen una forma normal.
Lognormal bivariado: las distribuciones marginales son log normal.
6.2.2 Fundamentos
Las distribuciones estadísticas continuas y discretas. Estas son las funciones de probabilidad, la media, la varianza, la desviación estándar, la moda y la mediana. Cuando se dispone de datos de muestra, se utilizan para ayudar al analista a estimar los valores de los parámetros de la distribución estadística en un estudio. Las estimaciones de muestra de las medidas son el mínimo, máx., promedio, varianza, desviación estándar, moda y mediana.
6.2.2.1 Distribución continua
Rango admisible. La distribución continua tiene una variable aleatoria, x, con un rango admisible como sigue:
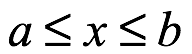
donde a podría ser menos infinito y b podría ser más infinito.
Densidad de probabilidad. La función de densidad de probabilidad de x es:
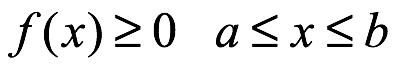
Donde
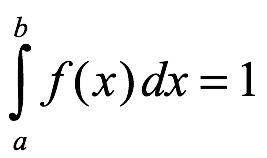
Distribución acumulada. La función de distribución acumulada de x es:
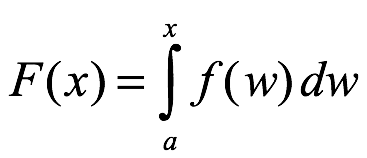
Esto da la probabilidad acumulada de x menor o igual a xo, digamos, como se muestra a continuación:
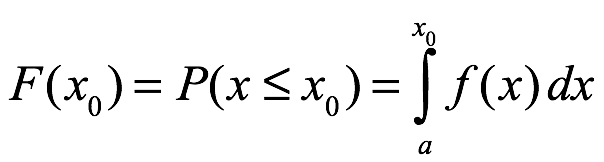
Probabilidad complementaria. La probabilidad complementaria en x mayor que xo se obtiene de la siguiente manera:
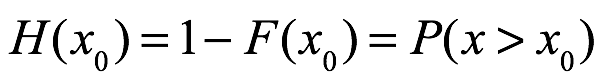
Valor esperado. El valor esperado de x, E (x), también llamado media de x, μ, se deriva de la siguiente manera:
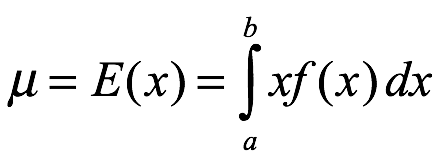
Varianza y desviación estándar. La varianza de x, σ2, se obtiene de la siguiente manera:
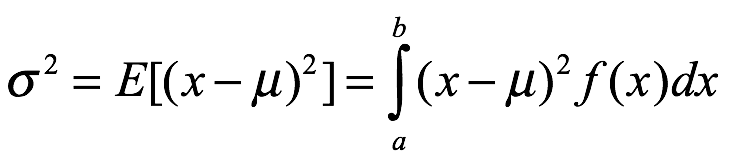
La desviación estándar, σ, es simplemente,
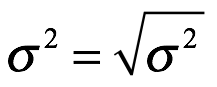
Mediana. La mediana de x, denotada por μ0.5, es el valor de x con probabilidad acumulada de 0.50 como se muestra a continuación:
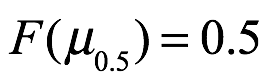
Moda. La moda, 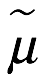 , es el valor más probable de x y está ubicado donde la densidad de probabilidad es más alta en el rango admisible, como se muestra a continuación:
, es el valor más probable de x y está ubicado donde la densidad de probabilidad es más alta en el rango admisible, como se muestra a continuación:
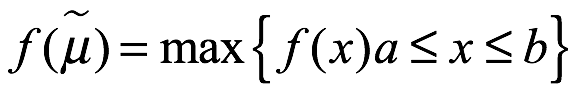
El α-punto porcentual de x, denotado como xα, se obtiene mediante la función inversa de F (x), donde,
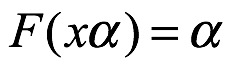
Coeficiente de variación. El coeficiente de variación, cov, de x es la relación de la desviación estándar sobre la media, como se muestra a continuación:
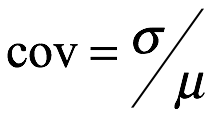
6.2.2.2 Distribuciones discretas
La distribución discreta tiene una variable aleatoria, x, con rango admisible,
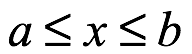
Para simplificar, el rango en este manuscrito se limita a variar en incrementos de uno, es decir,
rango =(a,a+1,…,b-1,b)
Función de probabilidad. La función de probabilidad de x, P(x), es la siguiente:

Donde
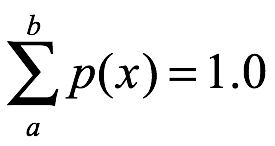
Probabilidad acumulada. La función de probabilidad acumulada de x, F (x), es la siguiente:
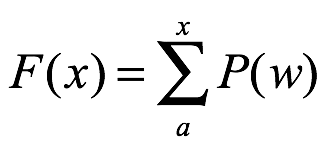
Probabilidad complementaria de xo es la probabilidad de que x sea mayor que xo de la siguiente manera:
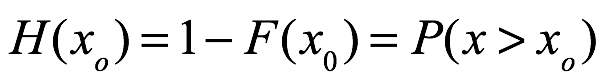
Valor esperado y media. El valor esperado de x, E(x), también llamado la media de x, μ, se deriva de la siguiente manera:
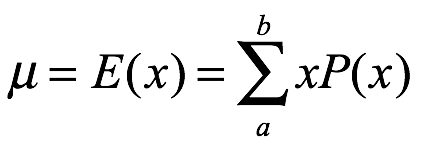
Varianza y desviación estándar. La varianza de x, σ2, se obtiene de la siguiente manera:
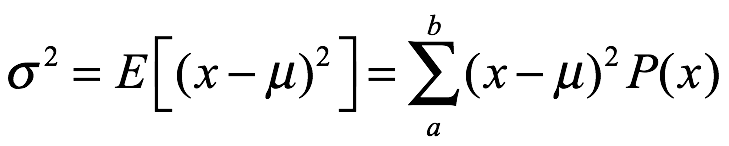
La desviación estándar, σ, se calcula a continuación:
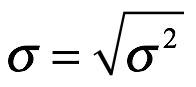
Mediana. La mediana de x, denotada por μ0.5, es el valor de x con probabilidad acumulada de 0.50 como se muestra a continuación:
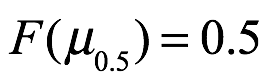
Moda. La moda, 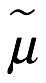 , es el valor más probable de x y está ubicado donde la densidad de probabilidad es más alta en el rango admisible, como se muestra a continuación:
, es el valor más probable de x y está ubicado donde la densidad de probabilidad es más alta en el rango admisible, como se muestra a continuación:
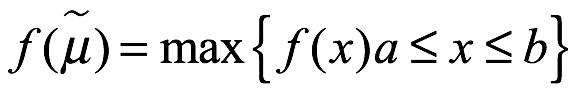
Relación de Lexis. La relación de Lexis, τ, de x es la relación de la varianza sobre la media, como se muestra a continuación:
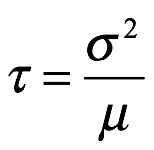
6.3 Datos de muestra estadísticas básicas
Cuando se recopilan n datos de muestra, (x1,..., xn), se pueden calcular varias medidas estadísticas como se describe a continuación:
n= tamaño de muestra
x(1)= min de (x1,..., xn)
x(n)= max de (x1,..., xn)

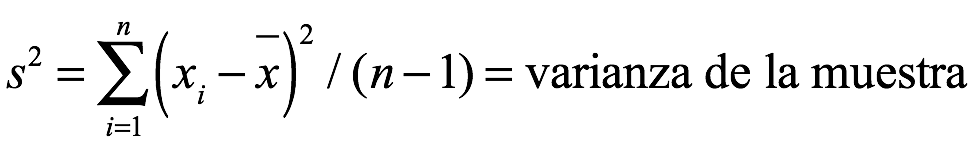
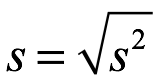 desviación estándar de la muestra
desviación estándar de la muestra
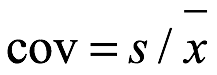 coeficiente de variación de la muestra
coeficiente de variación de la muestra
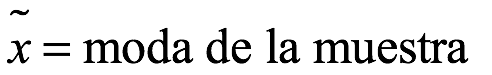
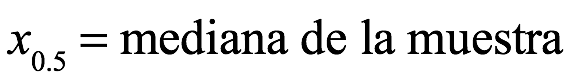
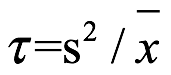 relación de Lexis de la muestra
relación de Lexis de la muestra
La mediana de la muestra es el valor medio del conjunto de datos ordenados (x1,..., xn). El ordenado las entradas se enumeran como: x(1), x(2),. . ., x(n). Si el número de muestras es impar, la muestra la mediana es
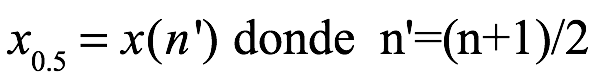
Si n es par, la mediana es:
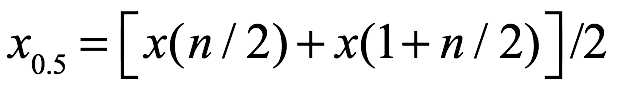
La moda de la muestra, 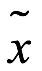 , es el valor de datos más frecuente de los datos de muestra. A veces pueden aparecer dos o más modas y, en ocasiones, no se encuentra ninguna moda. Para encontrar la moda, el analista debe ordenar los datos y elegir el valor que aparece más. Si ningún valor aparece más que otros, los datos podrían agruparse y el promedio del grupo con más entradas podría elegirse como la moda.
, es el valor de datos más frecuente de los datos de muestra. A veces pueden aparecer dos o más modas y, en ocasiones, no se encuentra ninguna moda. Para encontrar la moda, el analista debe ordenar los datos y elegir el valor que aparece más. Si ningún valor aparece más que otros, los datos podrían agruparse y el promedio del grupo con más entradas podría elegirse como la moda.
6.4 Métodos de estimación de parámetros
Cuando un analista desea aplicar una distribución de probabilidad en un estudio de investigación, a menudo no se conocen los valores de los parámetros y es necesario estimarlos. Las estimaciones se obtienen generalmente a partir de datos de muestra (x1,..., xn) que se han recopilado. Dos métodos populares para estimar el parámetro a partir de las entradas de datos son el estimador de máxima verosimilitud y el método de momentos. A continuación, se incluye una breve descripción de cada uno.
6.4.1 Estimador de máxima verosimilitud (MLE)
Este método formula una función de verosimilitud utilizando datos muestrales (x1,..., xn) y los parámetros de la distribución en estudio, y busca el valor del parámetro (s) que maximizan esta función. Por ejemplo, cuando una distribución estadística tiene un parámetro, θ, la búsqueda es por el valor de θ que maximiza la probabilidad de que las n muestras hubieran producido esos números, y este valor se denomina estimación de máxima verosimilitud.
6.4.2 Método de Momentos (MoM)
Este método encuentra los momentos teóricos de una distribución a partir de la función de probabilidad, y los momentos muestrales de la contraparte de los datos muestrales (x1,...,xn) se obtienen de la misma función de probabilidad. Una combinación de los momentos teóricos produce los parámetros de población (μ, σ, θ, etc.). Sustituyendo los momentos muestrales correspondientes en los momentos teóricos se obtienen las estimaciones muestrales de las estimaciones de los parámetros 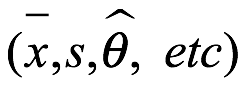 , y esta estimación se denomina estimación del método de momentos.
, y esta estimación se denomina estimación del método de momentos.
6.4.3 Transformación de variables
A veces es necesario convertir los datos muestrales originales (x1,..., xn) de manera que permita una identificación más fácil de la distribución de probabilidad que mejor se ajusta a los datos muestrales. Dos métodos son especialmente útiles, la conversión a un conjunto de datos de cero y mayor, y la conversión a un conjunto de cero y uno. Ambos métodos se describen a continuación.
6.4.4 Transformar datos a cero o más grandes
El analista con datos de muestra (x1,..., xn) puede encontrar útil convertir las entradas a cero o más grandes. Esto es aplicando:
y=x-x(1)
a cada entrada, y donde x(1) es el valor mínimo del conjunto de datos x. El nuevo conjunto de n entradas de datos se convierte en: (y1,..., yn). La media y la desviación estándar del nuevo conjunto de datos y se convierten en las siguientes:
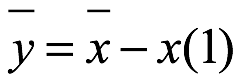
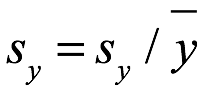
A veces, se necesita el coeficiente de variación, covy, del conjunto de datos y para ayudar a identificar la distribución de probabilidad que se ajusta a los datos de la muestra. El coeficiente de variación para el nuevo conjunto de datos y se convierte en:
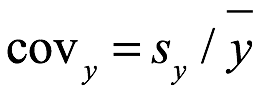
6.4.5 Transformar datos en cero y uno
A veces es conveniente convertir los datos de muestra en un nuevo conjunto que se encuentre dentro del rango de cero a uno. Esto se logra aplicando lo siguiente:
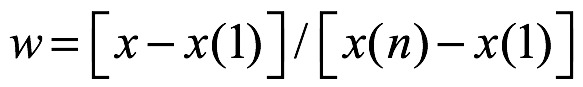
a cada entrada en el conjunto de datos de muestra, y donde x(1) es el valor mínimo y x(n) el valor máximo. El nuevo conjunto de datos se convierte en: (w1,..., wn). Este método produce la desviación estándar y media de w como se muestra a continuación:
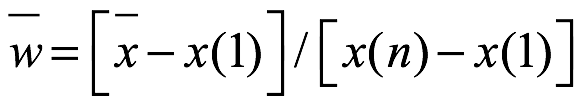
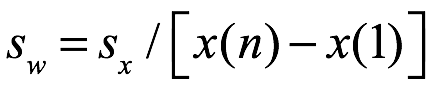
El coeficiente de variación del conjunto de datos w se convierte en:
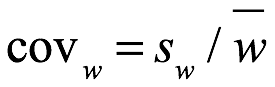
Con w dentro de (0, 1), el cov que emerge a veces, es útil para identificar la distribución de probabilidad del conjunto de datos.
Ejemplo 1.1 Considere los datos de muestra con 11 entradas enumeradas como:
(x1,..., X11)=(23, 14, 26, 31, 27, 22, 15, 17, 31, 29, 34). Las medidas estadísticas básicas de los datos se enumeran a continuación:
> s<-c(23, 14, 26, 31, 27, 22, 15, 17, 31, 29, 34)
> length(s)
[1] 11
n = 11
> min(s)
[1] 14
x(1) = 14
> max(s)
[1] 34
x(11) = 34
> mean(s)
[1] 24.45455
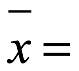 24.45
24.45
> var(s)
[1] 46.87273
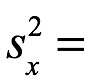 46. 87
46. 87
> sd(s)
[1] 6.846366
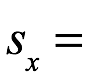 6:85
6:85
> install.packages("FinCal")
> library(FinCal)
> coefficient.variation (sd=sd(s), avg = mean(s))
[1] 0.2799629
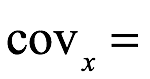 0.28
0.28
> median(s)
[1] 26
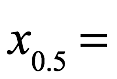 26
26
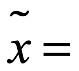 31
31
Si queremos visualizar el número de veces que se repite cada dato también podemos crear un gráfico de barras:
> barplot(table(s), col = c(4, rep("gray", 4)))
> legend("topright", "Moda", fill = 4)
 13.10.25.png)
El resumen es:
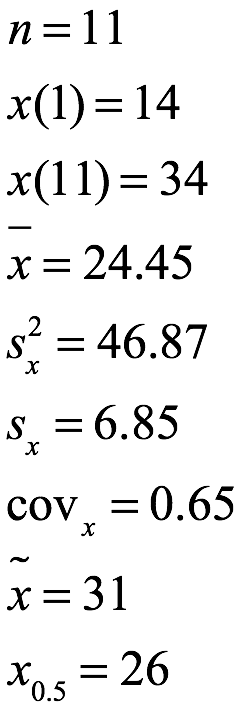
Ejemplo 1.2 Suponga que el analista de los datos del ejemplo 1.1 quiere convertir los datos para obtener un nuevo conjunto donde ![]() . Esto se logra tomando min = x (1) = 14 y aplicando y = (x - 14) a cada entrada. El conjunto de 11 entradas de datos con variable x y la contraparte con variable y se enumeran a continuación:
. Esto se logra tomando min = x (1) = 14 y aplicando y = (x - 14) a cada entrada. El conjunto de 11 entradas de datos con variable x y la contraparte con variable y se enumeran a continuación:
> s<-c(23, 14, 26, 31, 27, 22, 15, 17, 31, 29, 34)
> y<-(s-14)
> y
[1] 9 0 12 17 13 8 1 3 17 15 20
Las medidas estadísticas básicas para el conjunto de datos revisado de y se enumeran a continuación. Tenga en cuenta que las únicas medidas del conjunto y que siguen siendo las mismas que el conjunto x son el número, la varianza y la desviación estándar.
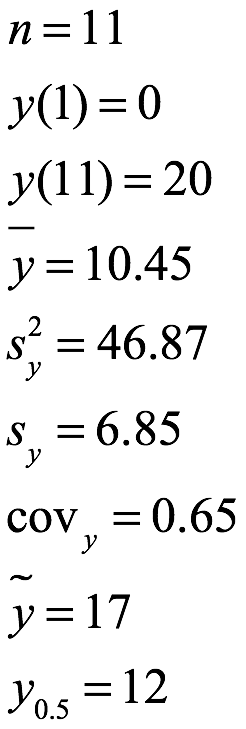
Ejemplo 1.3 Suponga que el analista de los datos del ejemplo 1.1 quiere transformar los datos para que estén entre 0 y 1. Esto se logra tomando los valores mínimo = x (1) = 14 y el máximo = x (11) = 34 y aplicando w = (x -14) / (34 -14) a cada una de las entradas. A continuación se enumeran los valores originales de x y el conjunto transformado de w.
> w<-((s-14)/(34-14))
> w
[1] 0.45 0.00 0.60 0.85 0.65 0.40 0.05 0.15 0.85 0.75 1.00
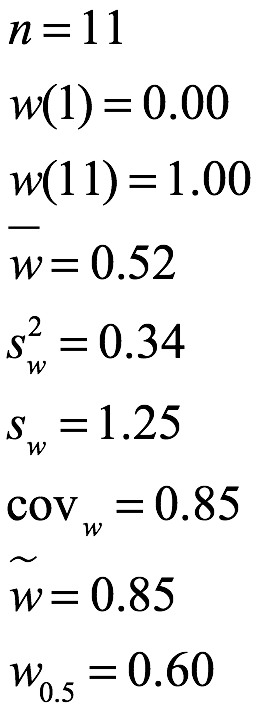
6.5 Los datos
Las ciencias en su infancia principalmente hacen observaciones y mediciones sistemáticas en un área temática. La ciencia madura con la experiencia y con el desarrollo tecnológico de las bases de datos. En esta etapa más avanzada de desarrollo, las observaciones se generalizan, se formulan hipótesis de trabajo y se busca convertir los datos en evidencia. Los datos pueden ser hechos que aún no se entienden en el contexto de una teoría integral. Los hechos podrían ser coherentes con muchas propuestas posibles. Pero si los datos finalmente llegan a ser claramente entendidos en términos de una hipótesis en particular mientras que son claramente inconsistentes con todas las hipótesis rivales, entonces lo datos son evidencia para la hipótesis plausible. Como ejemplo, considere la importancia de algunos hechos sobre un crimen. La policía podría saber que el crimen tuvo lugar a las 9:30 pm del martes en una ciudad con 2.5 millones de habitantes y aún más visitantes y trabajadores. Este hecho por sí solo no reduce la búsqueda a un individuo único. Por el contrario, supongamos que la policía encuentra un rastro de sangre del criminal en la escena del crimen. Ahora se conoce el ADN del criminal. Este segundo hecho tiene un alto valor probabilístico, porque está vinculado de forma exclusiva al criminal y no a nadie más.
Las estadísticas desempeñan un papel importante tanto en la organización de datos como en el proceso de hacer inferencias más amplias sobre los datos. El paradigma bayesiano hace inferencia estadística, en nuestra opinión, el sistema más coherente para analizar datos, construir evidencia para hipótesis válidas, incluso si la hipótesis es la información de que no hay diferencia entre dos condiciones. En muchas disciplinas científicas, las estadísticas bayesianas se utilizan. El enfoque bayesiano de las estadísticas en sí es bastante general, por lo que se puede utilizar en cualquier disciplina.
Al principio es útil distinguir entre tipos de datos amplios. Estos son: 1) relación categórica; 2) ordinal, 3) intervalo y 4) racional o cociente. Las estadísticas no paramétricas o sin distribución se organizan en gran medida en términos de estos tipos de datos; aunque en la mayoría de los casos, la distinción entre las mediciones de intervalo y relación no afectan a las operaciones estadísticas. Por lo tanto, en muchas disciplinas, los datos de intervalo y relación se describen simplemente como datos continuos.
6.5.1 Datos de relación categórica
Para los datos categóricos, también denominados datos nominales, las observaciones se agrupan en una de varias categorías etiquetadas. Por ejemplo la decisión Si versus No para sondeos. Alto versus Bajo. El investigador hace categorizaciones de la realidad, por atributos, propiedades o comportamientos. La decisión de la categoría que toman los datos es analítica. A lo largo de los periodos de pruebas se registran las frecuencias con la que se produce cada respuesta de categoría.
Los estadísticos llaman a la estructura de datos con recuentos de frecuencia para cada uno de un número de categoría no superpuestas de datos multinominales. Este tipo de datos es una medida gruesa, pero también tiene una propiedad estadística muy deseable que se discutirá aquí. La disposición más simple es cuando hay dos categorías, que se llama el modelo binomial. El análisis estadístico del modelo binomio es el foco de atención en el análisis bayasiano.
Datos clasificados
Para datos ordinales, que también se denominan datos clasificados, se ha medido alguna propiedad básica, pero la única información que se conserva es el orden de clasificación de las observaciones. A veces los vínculos, pueden producirse con datos clasificados si la propiedad continua subyacente es equivalente.
Datos de intervalos y relación
Los datos de intervalo o relación se miden con un instrumento calibrado para que los cambios incrementales en la escala del instrumento de prueba tenga el mismo significado independientemente del nivel general de la propiedad. Para las escalas de intervalo, el cero de escala se define arbitrariamente, como en el caso de los grados Celsius. A diferencia de una escala de intervalo, una escala de relación es una escala de intervalo donde el valor cero es de hecho un verdadero cero para esa propiedad. Como para el caso del grados Kelvin. Para las estadísticas, las técnicas de análisis son las mismas para los datos de escala de intervalo y relación. No obstante, esta distinción entre estas escalas es importante tenerle en cuenta para interpretar resultados.
Para las estadísticas paramétricas, el científico tiene una cantidad de escala de intervalo o relación. Aunque el contenido informativo es superior al de la información de orden de clasificación, el proceso de hacer una inferencia de los datos de la muestra a la población requiere hacer suposiciones sobre la distribución de la población desconocida. La inferencia es más robusta cuando no se requieren suposiciones sobre la población. Por lo tanto, hay muchos métodos no paramétricos que analizan datos de escala de intervalo o relación, pero el analista ignora los valores de las métricas con el fin de realizar una evaluación estadística sobre las diferencias de condición. Sin embargo, la información métrica no se pierde; se utiliza para clasificar la medida o para agrupar la medida en categorías.
6.6 Probabilidad
La base de las estadísticas es la teoría de la probabilidad. En consecuencia, tenemos que introducirnos al tema asociado con el significado de la probabilidad. Las estadísticas se ocupan de organizar y resumir las propiedades de los datos obtenidos a partir de una muestra, así como con el proceso de inferencia sobre las características de una población de mayor interés científico. Es necesario afinar el lenguaje en este espacio de significado. Población: es el conjunto completo de todos los valores potenciales de interés científico que están asociados con una propiedad específica que potencialmente se puede medir bajo un conjunto explícito o Muestra. Es un subconjunto de observaciones de una población. Procedimiento de muestreo, conseguir una muestra representativa y aleatoria. El interés científico tiene que ver con las características de la población. En uno de los procesos más notables del aprendizaje inductivo, realmente podemos, con las herramientas de probabilidad y estadística, aprender mucho sobre esa población a partir de una muestra trivialmente pequeña. Tal vez con solo unas pocas docenas de observaciones en una muestra representativa, es posible sacar algunas conclusiones fuertes sobre la población.
¿Qué es una muestra representativa y por qué importa? La segunda parte de esta pregunta es obvia. Sin una muestra representativa, podríamos ser engañados por los resultados del estudio. A veces, los investigadores piden a los estadísticos que corrijan algunos posibles sesgos de muestreo que se produjeron. Como testimonio de la inteligencia de los estadísticos, a menudo se puede hacer una corrección para abordar un problema de procedimiento. Sin embargo, las correcciones estadísticas posteriores a los hechos siguen siendo menos deseables que un plan de investigación mejor diseñado que elude el problema en primer lugar. Afortunadamente suelen ser cuidadosos y emplean protocolos de pruebas razonables. Los científicos eventualmente deben defender sus procedimientos de investigación cuando presentan sus trabajo para revisión a sus pares escépticos de su disciplina. En consecuencia, con la guía específica de los estadísticos, los científicos a menudo son muy cuidadosos con sus protocolos de muestreo.
La respuesta a esta pregunta tienen muchos componentes. El investigador tiene como propósito hacer del estudio estadístico de una muestra representativa como un marco válido para sacar conclusiones sobre la población. La investigación implica una cantidad de juicio humano y la incorporación de la sabiduría colectiva aprendida de estudios anteriores. En consecuencia una buena parte de lo que hace un investigador es inferencia válida apoyada en buenas prácticas de investigación que se basan en la disciplina científica. En el contexto del muestreo que incorpora una práctica sólida de investigación, se puede definir formalmente con la idea de muestra representativa.
Definición de muestra representativa de tamaño n. Si Sndenota un conjunto de n unidades que se obtuvieron con un conjunto de criterios de selección coherente. Sn es una muestra representativa de la población objetivo si el investigador es indiferente (antes de hacer cualquier medición) entre esta colección frente a cualquier otra colección obtenida de forma similar que podría haber sido muestreada de la misma población con los mismos criterios de selección.
El término muestra representativa utilizado aquí, tiene el mismo significado que lo que otros llaman una muestra aleatoria simple. El procedimiento está diseñado para recopilar datos de la población objetivo de una manera que no sobre o se rebase la representación de ninguna parte en particular de la población. Para este tipo de muestra existen otros tipos de procedimientos de muestreo, como el muestreo estratificado y el muestreo en línea. El muestreo estratificado es en realidad un muestreo aleatorio simple con la restricción de que los subgrupos específicos se muestran por igual. El muestreo en línea utiliza un procedimiento en el que los sujetos responden a solicitudes en línea para participar en un experimento o encuesta en línea. Tenga en cuenta que para cada uno de estos planes de muestreo, se puede definir una población más grande que esté vinculada con el método de muestreo. Por lo tanto, con la definición adecuada de la población objetivo, la muestra es un subconjunto de la población.
Para aclarar el proceso de inferencia estadística es conveniente hacer algunas definiciones adicionales e introducir algunas notaciones matemáticas. Los parámetros son propiedades (o funciones) de los valores de la población. Los parámetros se indican con letras del alfabeto griego. Las funciones estadísticas son propiedades aplicadas de los valores de la muestra, se suelen denotar con letras latinas.
La teoría matemática de la probabilidad tuvo un desarrollo relativamente tardío en comparación con algunas otras ramas de la matemática, que tuvieron sus orígenes en la antigüedad. La aleatoriedad y el azar como ahora pensamos en ellas surgieron en los siglos XVI y XVII, cuando a los matemáticos se les hicieron preguntas sobre los problemas del juego. No es un accidente que los lanzamientos de dados, monedas, y tarjetas se usaran para ilustrar y explicar las ideas probabilísticas. El estudio de la probabilidad comenzó con el análisis matemático de los juegos de azar, pero ha crecido para desempeñar un papel central en las ciencias modernas. La probabilidad también es la base de las estadísticas.
Se aprendió mucho sobre la probabilidad antes de que los matemáticos delinearan formalmente los axiomas fundamentales para el tema. Los axiomas en matemáticas generalmente vienen después de que se hace un trabajo considerable en asistencia de principios fundamentales. Por ejemplo, los axiomas de Euclides para la geometría llegaron muchos siglos después de que los matemáticos griegos anteriores comenzaron a explorar la geometría. Al igual que con la geometría, la base axiomática para la probabilidad proporciona claridad y rigor al sujeto. Pero antes de discutir el axioma fundamental para la probabilidad, es importante definir otros términos: pregunta direccionable, espacio de muestra de una pregunta direccionable y un evento.
Una pregunta direccionable es cualquier declaración que puede dar lugar a resultados mutuamente excluyentes y para la cual la recopilación de información puede ayudar a responder a la pregunta. Por lo tanto, cualquier experimento o procedimiento definido puede considerarse una pregunta direccionable.
El término direccionable simplemente significa cualquier pregunta en la que la recopilación de información pueda ayudar con la respuesta. Por ejemplo, si la pregunta es cuál de los dos candidatos ganará una elección en la ciudad para presidente municipal, entonces una encuesta muestra, proporciona cierta información sobre las posibilidades para los dos candidatos. Eventualmente la celebración de la elección resultará en una respuesta a la pregunta.
El término mutuamente excluyente en la definición, es una característica importante de la definición, ya que separa la probabilidad clásica de otros tipos de incertidumbre. Mutuamente excluyente significa que si se produce un resultado, entonces no se produjeron otros resultados posibles. Si el resultado de un volteo de monedas es una cruz, entonces el resultado no puede ser también un sol. Es un resultado u otro. Pero en el mundo de la mecánica cuántica, esta propiedad mutuamente excluyente no se presenta. ¿Es un fotón una partícula o una onda? El fotón no es puramente una partícula ni es puramente una onda. En consecuencia, la teoría clásica de la probabilidad no es una descripción precisa para los fenómenos mecánicos cuánticos.
Las preguntas direccionales también pueden ser declaraciones e hipótesis. Teóricos como von Mises, concluyeron que no existe ninguna probabilidad para una hipótesis porque una hipótesis no es un colectivo de eventos repetibles[1]. Sin embargo, el científico sabe que hay incertidumbre en cualquier experimento, pero sin embargo el científico quiere saber la probabilidad de la hipótesis. Es una restricción innecesaria descartar la hipótesis simplemente porque no se puede repetir infinitamente un experimento. La ciencia en general está tratando de encontrar la hipótesis que tiene la mayor probabilidad de ser correcta. Los requisitos de que solo las secuencias repetibles pueden tener una probabilidad es una falta muy grave para comprender lo que está involucrando la inferencia estadística. Si las estadísticas y la teoría de probabilidad son para ayudar con el objetivo de construir evidencia para una hipótesis plausible sobre otras hipótesis rivales, entonces una hipótesis debe ser capaz de tener un valor de probabilidad. Si adoptamos el concepto de pregunta direccional como marco, entonces una hipótesis tendrá un valor de probabilidad.
Muchos contextos son eventos únicos que no se pueden repetir. El acusado en un juicio penal es un caso único. El sistema de justicia busca certidumbre en sus decisiones, pero reconoce cierto nivel de incertidumbre. Las decisiones sobre eventos únicos se están tomando rutinariamente en la sociedad y no todos los resultados son igualmente probables. Por consiguiente, la palabra elección da idea de una pregunta dirigible, evita deliberadamente hacer una restricción artificial sobre la naturaleza de la pregunta. Las preguntas direccionales pueden ser acerca de una secuencia de hechos que se pueden repetir sin límite, como el lanzar dados, pero las preguntas direccionales también pueden ser acerca de hipótesis asociadas con los parámetros de población.
Espacio de muestra y eventos
Dada una idea de una pregunta direccional, se pude definir el concepto de un espacio de muestra. Un espacio de muestra, se denota como S, es la lista completa de todos los posibles resultados mutuamente excluyentes para la pregunta direccionable.
El espacio de muestra para el lanzamiento único de una moneda es 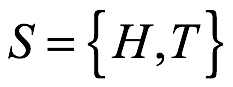 , donde H denota cara y T cruz. El espacio de muestra para tres lanzamientos de una moneda es
, donde H denota cara y T cruz. El espacio de muestra para tres lanzamientos de una moneda es  , donde se muestra el orden de los resultados para los tres lanzamientos. Tenga en cuenta que hay ocho resultados elementales para este espacio. Pero también podríamos escribir los resultados del procedimiento sin tener en cuenta el orden como
, donde se muestra el orden de los resultados para los tres lanzamientos. Tenga en cuenta que hay ocho resultados elementales para este espacio. Pero también podríamos escribir los resultados del procedimiento sin tener en cuenta el orden como 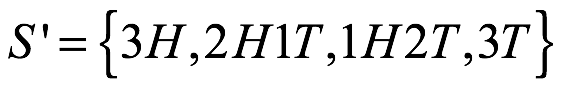 . Dos de los resultados de esta lista son resultados compuestos que pueden producirse de varias maneras. Por ejemplos 2H1T consiste en tres resultados HHT, HTH,THH en el espacio muestra S. La distinción elemental versus compuesta será importante al hacer problemas de probabilidad más adelante.
. Dos de los resultados de esta lista son resultados compuestos que pueden producirse de varias maneras. Por ejemplos 2H1T consiste en tres resultados HHT, HTH,THH en el espacio muestra S. La distinción elemental versus compuesta será importante al hacer problemas de probabilidad más adelante.
El evento  es un subconjunto del espacio muestra. En la notación de teoría de conjuntos
es un subconjunto del espacio muestra. En la notación de teoría de conjuntos  . Dado que cada resultado en el espacio muestra es un subconjunto de todo el espacio muestra, se deduce que los resultados individuales también se pueden llamar eventos. El número de resultados elementales para S y
. Dado que cada resultado en el espacio muestra es un subconjunto de todo el espacio muestra, se deduce que los resultados individuales también se pueden llamar eventos. El número de resultados elementales para S y  son respectivamente denotados por
son respectivamente denotados por 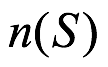 y
y 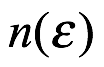 .
.
6.6.1 Axiomas de probabilidad de Kolmogorov
Pasaron 279 años después del intercambio Pascual-Fermat, que activó el análisis de la probabilidad, antes de que se formularan los axiomas fundamentales por Kolmogorov 1933/1959. El documento original del Kolmogorov definió tres axiomas, pero estos se pueden combinar en una sola declaración de la siguiente manera:
Axioma 1.1 Dado un espacio muestra para una pregunta direccional 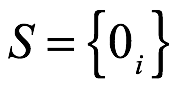 , i=1,2,…, existen valores de probabilidad reales y no negativos
, i=1,2,…, existen valores de probabilidad reales y no negativos 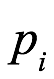 para estos resultados mutuamente excluyentes respectivos, de modo que en todos los resultados
para estos resultados mutuamente excluyentes respectivos, de modo que en todos los resultados 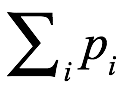 sea igual a 1, y la probabilidad de cualquier evento que sea la unión de eventos mutuamente excelentes es igual a la suma de las probabilidades para los eventos individuales.
sea igual a 1, y la probabilidad de cualquier evento que sea la unión de eventos mutuamente excelentes es igual a la suma de las probabilidades para los eventos individuales.
Discutamos los aspectos de este axioma 1.1. Números de valor real componen el axioma 1.1, se estipula 1) que existen probabilidades para cualquier espacio muestra de una pregunta direccional y 2) que estas probabilidades son números reales y no negativos. El axioma se basa en un espacio muestra asociado a una pregunta direccional. El argumento de los teóricos como el de von Mises, de que solo algunos espacios muestra pueden tener probabilidades es incompatible con el axioma. La suposición del axioma es que hay probabilidades para los resultados de cualquier espacio muestra de una pregunta direccionable. Además, ningún resultado puede tener una probabilidad negativa, ni puede ser un número complejo o imaginario. Es un valor real, pero puede ser ser cero.
6.6.2 La unidad
La suma de todas las probabilidades en el espacio muestra es 1. Así se deduce que cualquier evento A que 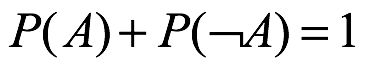 . Otra implicación de la característica de la medida unitaria del axioma es que las probabilidades tiene límites, es decir, deben estar en el intervalo [0,1].
. Otra implicación de la característica de la medida unitaria del axioma es que las probabilidades tiene límites, es decir, deben estar en el intervalo [0,1].
6.6.3 Aditividad
Todas las reglas para combinar probabilidades pueden derivarse del axioma de probabilidad. Pero aquí es valioso discutir con más detalle la aditividad de los conocimientos. Si hay dos eventos desarticulados o mutuamente excluyentes A y B, entonces conocemos 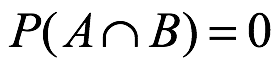 y
y 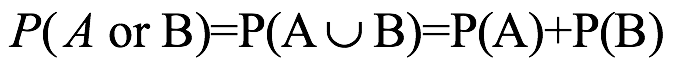 . Pero supongo que los dos eventos no son mutuamente excluyentes. Si
. Pero supongo que los dos eventos no son mutuamente excluyentes. Si 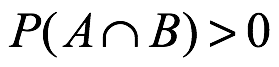 , entonces
, entonces 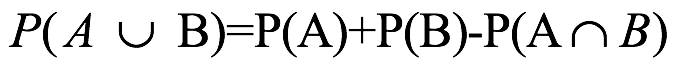 . La suma de las probabilidades para los eventos individuales da como resultado duplicar el peso de probabilidad para los resultados que están en común entre los dos eventos. En consecuencia, esta sobre representación de los resultados superpuestos se corrige mediante la resta de la probabilidad superpuesta de
. La suma de las probabilidades para los eventos individuales da como resultado duplicar el peso de probabilidad para los resultados que están en común entre los dos eventos. En consecuencia, esta sobre representación de los resultados superpuestos se corrige mediante la resta de la probabilidad superpuesta de 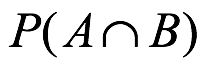 . Por otra parte, se puede demostrar que la probabilidad de la unión de tres eventos que nos son mutuamente excluyentes es:
. Por otra parte, se puede demostrar que la probabilidad de la unión de tres eventos que nos son mutuamente excluyentes es:
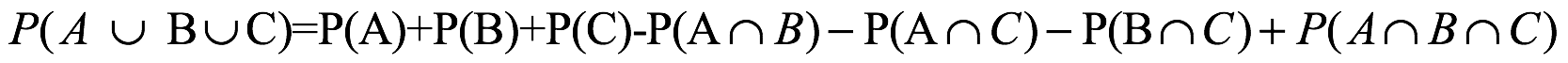
La adición de las probabilidades para los eventos individuales duplica el peso de la probabilidad para los resultados que se superponen a cualquiera de los dos eventos. Este exceso se corrige mediante los tres términos negativos. Sin embargo, la resta de esas tres intersecciones de dos eventos corrige demasiado la probabilidad que se superpone a los tres eventos; por lo tanto el último término añade esa probabilidad. Aunque la unión de eventos que no son mutuamente excluyentes es un reto, la unión de cualquier número de eventos desarticulados o mutuamente excluyentes es trivial:
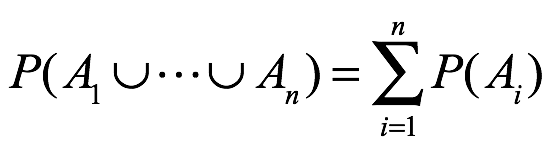
6.6.4 Corolario de monotonia
Hay otro corolario del axioma de Kolmogorov que debe ponerse atención. El contexto es el subconjunto de eventos denotados como 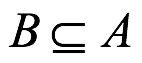 , lo que significa que B es un subconjunto adecuado (denotado como
, lo que significa que B es un subconjunto adecuado (denotado como 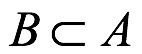 o es igual a A). Se puede probar que por el axioma Kolmogorov que si
o es igual a A). Se puede probar que por el axioma Kolmogorov que si 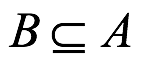 , entonces se deduce que
, entonces se deduce que 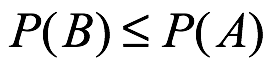 .
.
6.6.5 Pensamiento de modelos bayesianos
En los últimos años, ha habido una tendencia a basar la investigación científica en condiciones de información incompleta, es decir, la mayor parte de la ciencia biológica descansa en la teoría de la probabilidad[2]. Este es el enfoque que adoptamos también en este manuscrito. Nuestro objetivo es mostrar cómo la definición de todas las incertidumbres en el modelado son distribuciones de probabilidad que permite una reducción rigurosa de esas incertidumbres cuando se dispone de nuevos datos. El enfoque que presentamos se conoce en la literatura con muchos nombres diferentes, incluida la calibración bayesiana, la asimilación de datos, la fusión de modelos y datos y, el modelado inverso. Si bien los diferentes nombres se refieren a diferentes aplicaciones de modelado, todos comparten la idea de especificar distribuciones de probabilidad que se modifican de acuerdo con las reglas de la teoría de la probabilidad (en particular, el teorema de Bayes) cuando llegan nuevos datos. Es esta idea la que facilita el análisis integral de errores e incertidumbres. Lindley expresó la importancia de la teoría de la probabilidad de la siguiente manera[3]: “La probabilidad, se ha dicho, es simplemente el sentido común reducido al cálculo. Es la herramienta básica para apreciar la incertidumbre, y la incertidumbre no puede manejarse adecuadamente sin un conocimiento de la probabilidad”. Y es posible demostrar formalmente que el pensamiento racional y coherente implica utilizar las reglas de la teoría de la probabilidad[4].
6.6.6 Pensamiento Bayesiano
Los conceptos básicos del pensamiento bayesiano son simples. Hay solo tres elementos, conectados por la teoría de la probabilidad. Los elementos son: (1) su creencia previa (a priori) sobre una cantidad o proposición, (2) nueva información, (3) su creencia posterior. La teoría de la probabilidad proporciona la conexión lógica desde los dos primeros elementos hasta el último. Entonces, todo lo que necesitamos aprender es cómo expresar creencias y nueva información en forma de distribuciones probabilidad, y luego simplemente podemos seguir las reglas de la teoría de la probabilidad.
¡Eso es todo! Si bien la simplicidad del pensamiento bayesiano es un hecho, eso no significa que sea necesariamente fácil de aprender. Pensar constantemente en términos de la teoría de la probabilidad no es algo natural para todos. Y no existe una forma única y sencilla de enseñarle al estudiante universitario el pensamiento bayesiano. Todo depende de sus antecedentes y de su modo favorito de pensamiento racional. ¿Algunos prefieren comenzar con conceptos abstractos, luego ecuaciones matemáticas, luego ejemplos? O desea comenzar con acertijos o anécdotas y aprender cómo se pueden abordar todos de la misma manera ¿Quizás le gustaría comenzar con su conocimiento de la estadística clásica y aprender cómo sus métodos siempre se pueden interpretar, y a menudo mejorar, de una manera bayesiana? Pero aquí comenzamos con una breve historia de detectives...
6.6.7 Un misterio sobre un asesinato
Llaman a un detective a una casa de campo: el dueño ha sido encontrado asesinado en la biblioteca. Los tres posibles sospechosos son su esposa, su hijo y el mayordomo. Antes de seguir leyendo, ¿quién cree que cometió el crimen? Y no diga: "No puede responder eso, aún no he inspeccionado la evidencia". Eres un detective bayesiano, por lo que puedes establecer tus probabilidades previas. Su hijo dice “lo opuesto a lo que la esposa dice”, pero encuentra ese sesgo tonto. Usted ve al mayordomo como el principal sospechoso, y daría una probabilidad de 3:1 de que es el culpable. Encuentra a la esposa tan improbable como al hijo. Entonces, su distribución de probabilidad anterior para mayordomo-esposa-hijo es 80-10-10%. Por supuesto, en realidad no apostaría dinero por el resultado del caso (usted es un profesional), pero primero decide investigar al mayordomo. Para su sorpresa, descubre que el mayordomo tiene una coartada perfecta. ¿Cuál es su distribución de probabilidad ahora? La respuesta es que la coartada del mayordomo no tiene nada que ver con la esposa o el hijo, por lo que son candidatos igualmente probables y su distribución de probabilidad se convierte en 0–50–50%.
A continuación, inspecciona la biblioteca y descubre que el asesinato se cometió con un instrumento contundente. ¿Cómo cambia eso tus probabilidades? Evalúa que la probabilidad de que un hombre elija un arma homicida de este tipo es dos veces mayor que la de una mujer. Entonces eso cambia sus probabilidades a 0–33–67%.
Los dejo para terminar la historia hasta una conclusión lógica en la que se haya procesado suficiente evidencia para identificar al asesino más allá de toda duda razonable. Pero, ¿qué nos enseña este misterioso asesinato? Bueno, nuestra historia es ficción, pero contiene los tres pasos de cualquier análisis bayesiano: asignar una distribución de probabilidad previa, se adquiere nueva información, actualizar su distribución de probabilidad siguiendo las reglas de la teoría de la probabilidad. Todo en este manuscrito, y en las estadísticas bayesianas en general, trata sobre uno o más de estos tres pasos. Entonces, si encontró plausible el razonamiento del detective, ¡entonces ya es bayesiano! De hecho, existe una rica literatura en el campo de la psicología que muestra que los seres humanos, al menos hasta cierto punto, toman decisiones de manera bayesiana.
6.6.8 Teorema de Bayes
El teorema de Bayes se remonta al siglo XVIII (Bayes 1763), y su uso en ciencia se ha explicado en libros de texto y artículos tutoriales. Entonces, ¿cuál es el teorema? Para expresarlo, necesitamos introducir algo notación. Escribimos p[A|B] para la probabilidad condicional de que A sea verdadera dado que B es verdadera. Entonces, el teorema se escribe de la siguiente manera:
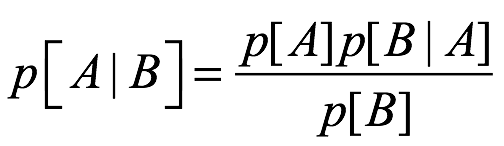 (1.1)
(1.1)
Los cuatro términos de la ecuación (1.1) son probabilidades o densidades de probabilidad, y el teorema es verdadero independientemente de lo que denoten A y B. A es lo que nos interesa. Puede representar “lloverá mañana” o el rendimiento de la cosecha superará las 10 toneladas por hectárea o el parámetro de densidad de biomasa tiene un valor de 900 (kg m−3). Queremos cuantificar la probabilidad de que el enunciado A sea verdadero dada alguna información B, y escribimos esta probabilidad condicional como p[A|B]. En aplicaciones científicas, A a menudo se refiere a un parámetro o vector de parámetro cuyo valor verdadero θ queremos saber, por lo que A podría representar “θ = 1” o “θ = 2”, o cualquier otro valor de parámetro. Y entonces B podría ser la declaración "mi sensor me da el valor y". Tenga en cuenta que en tales casos, el teorema de Bayes en realidad nos da infinitos enunciados de probabilidad correctos y diferentes a la vez, porque siguen siendo válidos para cada valor de parámetro posible θ y cualquier dato y. En otras palabras, el teorema de Bayes define la distribución de probabilidad condicional completa para el valor del parámetro dado los datos. Aquí está el teorema de Bayes nuevamente usando estos símbolos más comunes:
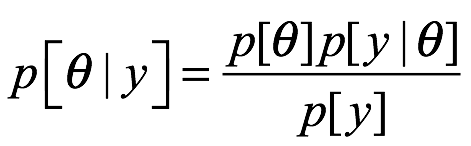 (1.2)
(1.2)
Los cuatro términos del teorema tienen un nombre: p[θ|y] es la distribución de probabilidad posterior para el parámetro θ, p[θ] es su distribución previa, p[y|θ] es la función de verosimilitud y p[y] es la evidencia. Su trabajo en un análisis bayesiano será definir la distribución previa de probabilidad, y la evidencia se definirá automáticamente también (como explicaremos más adelante), después de lo cual el Teorema de Bayes nos da la distribución posterior que deseamos.
También podemos escribir el teorema de Bayes con solo tres términos. En la mayoría de las aplicaciones, se da el valor de los datos y, y no podemos cambiarlos. Pero podemos considerar muchos valores posibles diferentes del parámetro θ. Entonces p[y] es constante, pero, los otros tres términos varían dependiendo del valor de θ. En términos de cantidades variables, podemos decir que la posterior distribución es proporcional al producto de la anterior y la probabilidad:
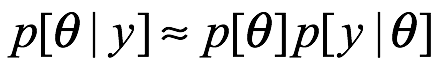 (1.3)
(1.3)
6.6.8.1 Implicaciones del teorema de Bayes
Tenga en cuenta que en nuestra historia, permitimos la posibilidad de que el detective y quizá su asistente, asignen diferentes probabilidades previas de culpabilidad a los tres sospechosos. Este aspecto subjetivo de la probabilidad de hecho se aplica a todas las probabilidades previas y las funciones de verosimilitud que asignamos informalmente. Diferentes personas tienen diferentes conocimientos y antecedentes, por lo que podemos esperar que asignen diferentes probabilidades a los eventos del mundo real. Pero una vez que hemos especificado nuestra probabilidad anterior, no tenemos más remedio que aceptar la distribución posterior que nos da el Teorema de Bayes: no hay subjetividad en ese paso. En un contexto científico, debemos dar cuenta de todas las subjetividades inevitables siendo transparentes sobre ellas (es decir, mencionar qué a priori y qué probabilidad usamos) y, cuando sea posible, minimizar la subjetividad utilizando métodos formales para especificar la distribución a priori.
El teorema de Bayes como está escrito en (1.2) o (1.3) tiene algunas consecuencias inmediatas. Primero, si se asigna una probabilidad previa de cero a ciertos valores de los parámetros θ, entonces cualquier evidencia que pueda aparecer posteriormente, esos valores de parámetros siempre serán imposibles. El producto de cero por cualquier otro valor es siempre cero. Por ejemplo, si tiene parámetros que a priori se consideran positivos, incluso una plétora de valores de medición negativos no se conducirán en estimaciones negativas.
Del mismo modo, una vez que haya encontrado evidencia que implique una probabilidad cero para ciertos valores de parámetros, esos valores permanecen excluidos para siempre. Por lo tanto, solo deberíamos descartar los valores de los parámetros, en su función previa o de probabilidad, si estamos 100% seguros de que esos valores son imposibles. Por otro lado, si tenemos esa certeza, entonces un previo restringido puede hacer que el análisis posterior sea mucho más eficiente. Ahora tenemos el aparato formal para abordar los problemas de una manera bayesiana. Volvamos brevemente a nuestra historia de detectives anterior y veamos cómo encaja el teorema de Bayes.
La historia del detective es un problema de estimación de parámetros. Solo hay un parámetro, θ, con solo tres valores posibles: θ ∈ {esposa, hijo, mayordomo}. Entonces, nuestro a priori es una distribución de probabilidad discreta. La primera prueba es la coartada del mayordomo, que equivale, en lenguaje probabilístico, a una probabilidad de cero para θ = mayordomo. Si el mayordomo fuera culpable, entonces esa evidencia no podría haberse encontrado. Lo escribimos simbólicamente como p [coartada | θ = mayordomo] = 0. Ahora puede reescribir la historia usted mismo como una secuencia de aplicaciones del Teorema de Bayes donde la distribución posterior después de la primera pieza de evidencia se convierte en la anterior al procesar la segunda pieza de información, etc. Así Bayes formaliza el proceso de aprendizaje.
6.6.8.2 La forma de probabilidades del teorema de Bayes y una aplicación simple
En este punto, mostramos otra forma matemáticamente equivalente del teorema de Bayes que es especialmente útil cuando nuestro parámetro puede tener solo dos valores posibles, por ejemplo, 0 o 1, verdadero o falso, esposa o hijo. En tales casos, la forma de probabilidades del teorema de Bayes es útil. Las probabilidades de un evento son la probabilidad de que suceda dividido por la probabilidad de que no suceda: O[evento] = p [evento] / (1 - p [evento]). Derivemos las probabilidades posteriores para un parámetro θ ∈ {a, b}. Usamos notación abreviada: en lugar de escribir p [θ = a], escribimos p[a] etc. Entonces, las probabilidades anteriores de a son O [a] = p [a] / (1 - p [a]) = p [orden de busca y captura]. Entonces:
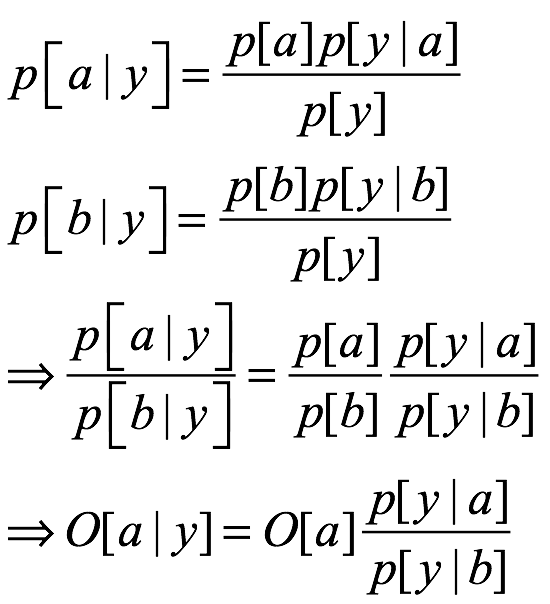 (1.4)
(1.4)
Así que esto nos da una forma muy simple de expresar el teorema de Bayes: las probabilidades posteriores son las probabilidades anteriores multiplicadas por la razón de verosimilitud. Usemos esta forma de probabilidades del teorema de Bayes en una aplicación simple. Ya hemos utilizado el pensamiento bayesiano en nuestro misterio de asesinato, pero ahora pasamos a un ejemplo en el que el teorema de Bayes se utiliza de forma más formal y cuantitativa. Es quizás el ejemplo más popular utilizado en los tutoriales bayesianos: cómo interpretar un diagnóstico médico. Digamos que ha comenzado una epidemia y el 1% de las personas está infectado. Existe una prueba de diagnóstico que da el resultado correcto en el 99% de los casos. Tenemos la prueba realizada y el resultado es positivo, lo cual es una mala noticia porque para los diagnosticadores "positivo" significa "infectado". Pero, ¿cuál es la probabilidad de que realmente tenga la enfermedad?
Ahora damos la respuesta. Como para todo análisis bayesiano, debemos especificar nuestra creencia previa y su probabilidad. Nuestra probabilidad previa de estar infectado es del 1%, por lo que nuestras probabilidades previas son O[infectado] = 1/99. Nuestra función de probabilidad es: {p [positivo | infectado] = 99%, p [positivo | no afectado] = 1%}, entonces nuestra razón de verosimilitud es 99. Sus probabilidades posteriores al tener la enfermedad son O[infectado | positivo] = 1/99 veces. Estas probabilidades uniformes significan que, quizás sorprendentemente dada la alta precisión de la prueba de diagnóstico, la probabilidad posterior de tener la enfermedad sigue siendo solo del 50%. Esto se debe a que la pequeña probabilidad de error de la prueba se corresponde con una probabilidad previa igualmente pequeña de tener la enfermedad.
6.6.8.3 Medición, modelización y ciencia: las tres ecuaciones básicas
En ciencia, utilizamos modelos para ayudarnos a aprender de los datos. Pero siempre trabajamos con la teoría incompleta y mediciones que contienen errores. La consecuencia de esto es que debemos reconocer las incertidumbres al intentar extraer información de las mediciones utilizando modelos. Ni una sola medida, ni una sola explicación o predicción es completamente correcta, y nunca podremos saber con exactitud qué tan equivocadas son. Este texto trata sobre cómo extraer mejor información de los datos utilizando modelos, reconociendo todas las incertidumbres relevantes. Nuestro enfoque general se refleja en tres ecuaciones. La primera es la ecuación de medición, que reconoce el error de observación:
ECUACIÓN DE MEDIDA: 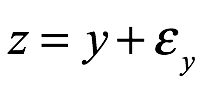 (2.1)
(2.1)
donde z es el valor verdadero, y es el valor medido y 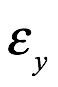 es el error de medición. La segunda ecuación es la ecuación de modelado y expresa la presencia de un tipo de error diferente:
es el error de medición. La segunda ecuación es la ecuación de modelado y expresa la presencia de un tipo de error diferente:
ECUACIÓN DE MODELADO: 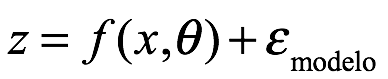 (2.2)
(2.2)
donde f es el modelo, x son las condiciones ambientales para las que ejecutamos el modelo, θ son los valores de los parámetros del modelo, y el término final modelo representa el error del modelo 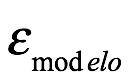 que surge porque f, x y θ serán todos incorrectos hasta cierto punto. Todos los términos en las ecuaciones anteriores pueden ser escalares (valores únicos) pero más comúnmente son vectores (multidimensionales). Dependiendo de la disciplina y, a veces, del autor individual o del problema, las condiciones ambientales x se denominan de diversas maneras impulsoras, covariables, predictores, condiciones de contorno, variables explicativas o independientes. Su característica definitoria es que las tratamos como dadas en lugar de tratar de estimarlas.
que surge porque f, x y θ serán todos incorrectos hasta cierto punto. Todos los términos en las ecuaciones anteriores pueden ser escalares (valores únicos) pero más comúnmente son vectores (multidimensionales). Dependiendo de la disciplina y, a veces, del autor individual o del problema, las condiciones ambientales x se denominan de diversas maneras impulsoras, covariables, predictores, condiciones de contorno, variables explicativas o independientes. Su característica definitoria es que las tratamos como dadas en lugar de tratar de estimarlas.
Cuando combinamos la ecuación de medición y modelado llegamos a la ecuación científica:
ECUACIÓN CIENTÍFICA: 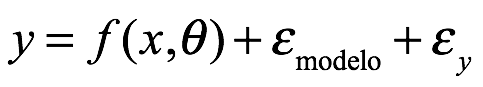 (2.3)
(2.3)
La ciencia es el intento de explicar las observaciones y utilizando un modelo f en el que intentamos minimizar el error del modelo 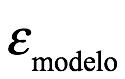 y el error de medición
y el error de medición 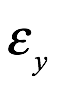 y, para que el modelo se pueda utilizar para hacer predicciones sobre el mundo real (z). El enfoque bayesiano de la ciencia reconoce y cuantifica las incertidumbres sobre los seis elementos de la ecuación científica: y, f, x, θ,
y, para que el modelo se pueda utilizar para hacer predicciones sobre el mundo real (z). El enfoque bayesiano de la ciencia reconoce y cuantifica las incertidumbres sobre los seis elementos de la ecuación científica: y, f, x, θ, 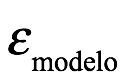 y
y 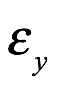 . Regresaremos a estas ecuaciones en varios puntos del texto (y las expandiremos), pero lo principal a notar por ahora es que reconocemos errores tanto en la medición como en el modelado, lo que hace que sea difícil encontrar los mejores valores de parámetro θ y la mejor forma de modelo f.
. Regresaremos a estas ecuaciones en varios puntos del texto (y las expandiremos), pero lo principal a notar por ahora es que reconocemos errores tanto en la medición como en el modelado, lo que hace que sea difícil encontrar los mejores valores de parámetro θ y la mejor forma de modelo f.
6.6.8.4 Confusión terminológica
Dado que este texto se centra en las incertidumbres en la medición y el modelado, debemos adoptar un lenguaje de la teoría de la probabilidad y la estadística. El problema es que a muchos conceptos se les han dado nombres muy confusos. Quizás el término más confuso para los científicos es variable aleatoria. Tomemos la afirmación que se escucha comúnmente: “para los bayesianos, cada parámetro es una variable aleatoria que obedece a una distribución de probabilidad específica". Esa afirmación no es estrictamente incorrecta, pero es muy engañosa. Sugiere que los parámetros pueden saltar, asumir valores arbitrarios. Pero los bayesianos no creen eso. Creen que todos los parámetros tienen valores específicos que, sin embargo, nunca podremos conocer con precisión infinita. Entonces, una variable aleatoria es solo una propiedad del mundo real sobre la cual tenemos un conocimiento incompleto. La aleatoriedad no dice nada sobre la propiedad, dice algo sobre el estado de conocimiento del investigador. Y ese estado de conocimiento diferirá entre las personas, por lo que diferentes investigadores cuantificarán sus incertidumbres con diferentes distribuciones de probabilidad. Intentaremos evitar el término en este texto y solo hablaremos de incertidumbres. Por supuesto, la terminología nunca puede ser perfecta. Este manuscrito combina trabajos de matemáticas, lógica, teoría de la probabilidad y estadística, informática y programación y, ciencias. Estas disciplinas a menudo usan los mismos términos con diferentes significados y, a menudo, usan términos diferentes para referirse a lo mismo. Incluso los términos más básicos, como modelo, parámetro y proceso, tienen diferentes definiciones en los diferentes campos. La siguiente lista define nuestro uso de estos y otros términos.
Error, residual, incertidumbre, variabilidad. Estos son términos que tienen diferentes significados, pero que a menudo se confunden. El error se define como la diferencia entre una estimación (medida o modelada) y el valor verdadero o real. Entonces en la ecuación (2.1), el término 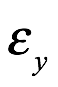 representa el error de medición, y en la ecuación (2.2), el
representa el error de medición, y en la ecuación (2.2), el 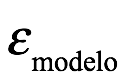 representa el error de modelado. Un residuo es la diferencia entre un valor medido y modelado. Con referencia a las mismas dos ecuaciones, los residuos se definen como y - f (x, θ). La incertidumbre es tener un conocimiento incompleto sobre una cantidad. La incertidumbre siempre se puede representar mediante una distribución de probabilidad, denotada como p[…]. Entonces, la distribución de probabilidad
representa el error de modelado. Un residuo es la diferencia entre un valor medido y modelado. Con referencia a las mismas dos ecuaciones, los residuos se definen como y - f (x, θ). La incertidumbre es tener un conocimiento incompleto sobre una cantidad. La incertidumbre siempre se puede representar mediante una distribución de probabilidad, denotada como p[…]. Entonces, la distribución de probabilidad 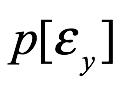 define qué valores de error de medición consideramos posibles y sus probabilidades relativas de ocurrir. Digamos que nuestro instrumento es preciso (imparcial) pero tiene solo un 50% de precisión. Entonces no estamos muy seguros del error y podríamos escribir
define qué valores de error de medición consideramos posibles y sus probabilidades relativas de ocurrir. Digamos que nuestro instrumento es preciso (imparcial) pero tiene solo un 50% de precisión. Entonces no estamos muy seguros del error y podríamos escribir 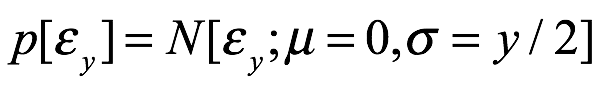 , que representa una distribución normal (o gaussiana) con
, que representa una distribución normal (o gaussiana) con 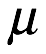 media cero y
media cero y 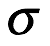 desviación estándar igual a la mitad del valor observado. Distribuciones de probabilidad condicionales, por ejemplo, para θ dado un cierto valor de y, se denotan en la forma estándar como p [θ | y]. Note que usamos corchetes para probabilidades, distribuciones de probabilidad y verosimilitudes y paréntesis para funciones como f (…). La variabilidad es la presencia de diferencias en un conjunto de valores. La variabilidad puede conducir a errores de muestreo de magnitud incierta. Digamos que tomamos muestras al azar de 100 árboles de un bosque grande, medimos el diámetro del tronco en cada uno y recolectamos los 100 valores en el vector y. La desviación estándar
desviación estándar igual a la mitad del valor observado. Distribuciones de probabilidad condicionales, por ejemplo, para θ dado un cierto valor de y, se denotan en la forma estándar como p [θ | y]. Note que usamos corchetes para probabilidades, distribuciones de probabilidad y verosimilitudes y paréntesis para funciones como f (…). La variabilidad es la presencia de diferencias en un conjunto de valores. La variabilidad puede conducir a errores de muestreo de magnitud incierta. Digamos que tomamos muestras al azar de 100 árboles de un bosque grande, medimos el diámetro del tronco en cada uno y recolectamos los 100 valores en el vector y. La desviación estándar 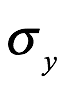 es entonces una medida de la variabilidad en la muestra. Si todas las mediciones son muy precisas, habrá poca incertidumbre sobre esa variabilidad. Pero si utilizamos la media de la muestra como una estimación del diámetro medio de todos los árboles del bosque, habrá un error de muestreo desconocido. En este ejemplo, la incertidumbre sobre el error de muestreo bien puede estar representada por una distribución normal con media cero y desviación estándar igual a
es entonces una medida de la variabilidad en la muestra. Si todas las mediciones son muy precisas, habrá poca incertidumbre sobre esa variabilidad. Pero si utilizamos la media de la muestra como una estimación del diámetro medio de todos los árboles del bosque, habrá un error de muestreo desconocido. En este ejemplo, la incertidumbre sobre el error de muestreo bien puede estar representada por una distribución normal con media cero y desviación estándar igual a 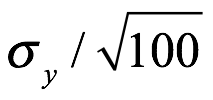 .
.
Modelo, entrada, salida. Cada modelo es una función que opera sobre entradas y las convierte en salidas. Las entradas típicas son parámetros y variables independientes. Tanto las entradas como las salidas pueden ser escalares (unidimensionales) pero con mayor frecuencia son vectores (multidimensionales). Las variables independientes pueden ser el tiempo, las coordenadas espaciales o impulsores ambientales, como series de tiempo de variables climáticas o intervenciones humanas en el sistema modelado. Los modelos se utilizan con dos propósitos: explicar el pasado y predecir el futuro. En ambos casos, el modelo es solo una herramienta para extraer información de las mediciones. El análisis de varianza, por ejemplo, es un modelo estadístico para extraer información de experimentos multifactoriales. Un modelo climático global complejo es una herramienta para extrapolar mediciones pasadas del clima y otras partes del sistema terrestre al cambio climático futuro. No hay una diferencia fundamental entre el ANOVA y el GCM, ambos son procesadores de datos imperfectos que supuestamente apuntan a relaciones causales en la naturaleza. La única diferencia es que el GCM es más complejo.
Modelo dinámico. Un modelo con el tiempo como variable.
Modelo basado en procesos (PBM). Los PBM son modelos dinámicos deterministas que simulan procesos del mundo real. Por lo general, tienen dos tipos de entrada: controladores y parámetros. Los impulsores son variables ambientales (clima, perturbaciones, gestión) mientras que los parámetros son propiedades constantes del sistema.
Modelo empírico. Un modelo que no simula procesos dinámicamente, entonces, en este texto, usamos PBM y, modelos empíricos como términos complementarios. Cada modelo pertenece a la primera o la segunda categoría.
Modelo determinista. Un modelo que para cualquier entrada específica siempre produce la misma salida.
Modelo estocástico. Un modelo que produce una salida diferente cada vez que se ejecuta, incluso si la entrada sigue siendo la misma. Es un término complementario al modelo determinista: todo modelo es uno o el otro.
Modelo estadístico. Un modelo que representa explícitamente la incertidumbre sobre los errores mediante distribuciones de probabilidad. Tanto los PBM como los modelos empíricos pueden integrarse en un modelo estadístico. Este texto muestra cómo un modelo estadístico se puede envolver alrededor de cualquier modelo, independientemente de si el modelo central está basado en procesos o es empírico, determinista o estocástico.
 14.00.23.png)
6.7. Modelos basados en procesos versus modelos empíricos
Toda la metodología que presentamos en este manuscrito se puede aplicar a cualquier tipo de modelo: simple o complejo, basado en sitio o en área, determinista o estocástico, basado en procesos o empírico. La mayoría de los textos que explican los métodos bayesianos utilizan ejemplos de pequeños conjuntos de datos y modelos bastante simples, y en la mayoría de los casos también lo haremos. Es un enfoque válido porque el pensamiento bayesiano (definir las creencias previas y probabilidades, derivar posterior) es el mismo en todos los casos. Sin embargo, la complejidad del modelo afecta la facilidad del cálculo bayesiano. Y, por lo tanto, algunos de nuestros ejemplos se extraerán de la literatura sobre modelado determinista de ecosistemas basado en procesos. Esta es una clase de modelos dinámicos que simula el crecimiento de la vegetación como parte de los ciclos del carbono, el agua y los nutrientes en el sistema de atmósfera suelo-árbol[5]. Estos modelos basados ??en procesos (PBM) se pueden utilizar para la evaluación de múltiples servicios ecosistémicos[6]. Los PBM tienden a ser ricos en parámetros y computacionalmente exigentes. Explicaremos cómo estas características obstaculizan la aplicación integral del enfoque probabilístico a las incertidumbres y qué soluciones se han propuesto. Los PBM son particularmente útiles para el estudio de sistemas adaptativos complejos de los que se conocen importantes procesos y mecanismos internos, por lo que no es necesario tratarlos como cajas negras. Los PBM tienen como objetivo representar mecanismos reales, es decir, relaciones causales. Se puede decir que los modelos empíricos también lo hacen, pero a medias[7].
La literatura ofrece al modelador una desconcertante variedad de técnicas y enfoques, con grandes nombres como Asimilación de datos, Fusión de datos de modelo, Filtrado de Kalman, Calibración bayesiana, etc.; sin embargo, la literatura estadística rara vez muestra aplicaciones a modelos dinámicos (incluyendo PBM), por lo que para tales modeladores la aplicabilidad de la perspectiva bayesiana puede no estar clara[8]. Aquí esperamos mostrar cómo la multitud de técnicas y enfoques presentados son, de hecho, relaciones familiares entre sí. La perspectiva bayesiana proporciona un tratamiento unificado de los problemas de los datos del modelo, independientemente del tipo de modelo o datos.
6.7.1 Errores e incertidumbres en el modelado
El enfoque bayesiano es esencial para los científicos porque permite una representación formal y una cuantificación completa de las incertidumbres, así como un aprendizaje riguroso de las observaciones. Los errores son inevitables en el modelado, pero no estamos seguros de su magnitud. Las entradas (parámetros, impulsores ambientales) nunca se pueden conocer perfectamente, y cada modelo es una simplificación de la realidad y, por lo tanto, tiene errores estructurales. Cuantificamos nuestra incertidumbre acerca de estos errores en forma de distribuciones de probabilidad y proponemos estas incertidumbres a los resultados del modelo, es decir, evaluar cuán exactas y precisas son las predicciones de nuestro modelo. Usamos datos y el teorema de Bayes para reducir las incertidumbres sobre el error del modelo. Para poder utilizar los métodos bayesianos, debemos tener una comprensión clara de los diferentes tipos de error. Así que hablemos de ellos en detalle.
6.7.2 Errores e incertidumbres en los controladores de modelos
Como se describió anteriormente, los controladores son las condiciones ambientales que se ingresan en un modelo (la x en la Ecuación de modelado (2.2)). Metodológicamente, los impulsores se definen como condiciones de contorno que no intentamos calibrar, pero que aceptamos como una fuente de información externa. Aunque los controladores no están calibrados, estamos interesados ??en los posibles errores que puedan contener y en la incertidumbre que tenemos sobre su magnitud. Los errores del controlador son de tres tipos: brechas (GAP), error de medición y falta de representatividad, y cada uno de ellos debe tratarse de manera diferente.
Las lagunas o brechas GAP en los datos del controlador son comunes. Cuando un modelo requiere datos diarios del controlador y la serie de tiempo meteorológico falla algún día o días, es necesario llenar los vacíos. Los métodos de llenado de huecos van desde la interpolación lineal simple hasta el modelado de procesos estocásticos, similar al kriging. Este último es el único enfoque para el que las incertidumbres se cuantifican fácilmente (como la varianza del proceso kriging o gaussiano).
El error de medición se debe a una precisión y exactitud limitadas del instrumento de medición y, a veces, también a errores en la transferencia de valores medidos a archivos de datos. Este es el tipo de error más simple; la incertidumbre al respecto está generalmente bien representada como ruido gaussiano.
Los errores más complicados surgen cuando los datos del controlador no son representativos del condiciones ambientales para las que planeamos ejecutar nuestro modelo. Los datos meteorológicos pueden provenir de una estación meteorológica externa o los datos pueden tener una escala espacio-temporal diferente a la que requiere el modelo. Un ejemplo muy común es el uso de resultados de modelos climáticos en cuadrícula como entrada para PBM: los datos climáticos serán promedios de celdas de cuadrícula, ignorando así la heterogeneidad espacial. Dichos datos no son representativos de ningún ecosistema específico dentro de la célula. Si el modelo no es lineal, como la mayoría de los modelos, entonces el promedio de entrada conduce a errores en los resultados del modelo, pero existen métodos para estimar ese error, basados ??en la expansión de Taylor de la dependencia del controlador[9]. Otra opción es reducir la escala de los datos, aunque eso conlleva sus propios errores e incertidumbre. No existe una regla general para asignar distribuciones de probabilidad a errores por no representatividad: cada caso debe ser examinado por sí solo.
6.7.3 Errores e incertidumbres en los parámetros del modelo
Los parámetros son constantes que representan propiedades fijas de nuestro sistema de interés. En PBM, cada proceso que se modela requiere un parámetro para definir su tasa básica. Pero las tasas de proceso también dependen de las condiciones internas y externas (por ejemplo, el contenido de nitrógeno de las plantas o la temperatura del aire), y cada mecanismo de control agrega al menos un parámetro de sensibilidad al modelo. El número de parámetros en los PBM para el modelado de la vegetación, por ejemplo, tiende a oscilar entre varias décimas y muchos cientos[10]. Esto planteará problemas para la estimación de parámetros, como veremos más adelante.
Los parámetros se pueden establecer en valores incorrectos, lo que hace que el comportamiento del modelo sea poco realista. Pero es difícil dar una definición precisa de error de parámetro. ¿Cuál es el valor "verdadero" de un parámetro? Debido a que un modelo es una simplificación de la realidad, cada parámetro juega un papel algo diferente en el modelo que su homónimo en el mundo real. Por lo tanto, no podemos simplemente salir y medir exactamente el valor real. Esto es aparte del hecho de que las mediciones también tienen errores y que ninguna propiedad del sistema es realmente constante en la realidad. En la práctica, decimos que el valor correcto de un parámetro es el valor que hace que el modelo se comporte de manera más realista. El error de parámetro es la diferencia con ese valor y la incertidumbre del parámetro es no saber cuál es ese valor. Aunque las mediciones no pueden proporcionar valores de parámetros verdaderos, pueden proporcionar primeras estimaciones aproximadas. Para cada parámetro, se informó una amplia gama de valores que podrían interpretarse como distribuciones de probabilidad que representan la incertidumbre del parámetro. Para muchos parámetros, las distribuciones se sesgan y es mejor representar por distribuciones beta que por distribuciones normales[11].
6.7.4 Errores e incertidumbres en la estructura del modelo
Cada modelo es una simplificación de la realidad y, por lo tanto, hasta cierto punto, es erróneo. Pero el comportamiento de los modelos (su repertorio de resultados para diferentes condiciones) se puede comparar, lo que demuestra que algunos modelos son más realistas que otros. Las comparaciones de modelos de ecosistemas abundan en la literatura y tienden a mostrar grandes diferencias entre sus predicciones[12]. Se pueden sacar algunas conclusiones generales provisionales: la estructura de retroalimentación de los modelos es más importante que la forma matemática de las ecuaciones individuales[13] y es deseable un nivel consistente de detalle del proceso en diferentes partes del modelo[14].
Cada vez más, las comparaciones de todos los modelos, incluidos los PBM complejos, implican la evaluación de simulaciones frente a observaciones, no solo de variables de salida como la productividad, sino también de los procesos y mecanismos subyacentes representados en los modelos[15] se refieren a esto como un “enfoque de intercomparación de modelos centrados en supuestos”. Sin embargo, estas comparaciones de modelos no emplean la teoría de la probabilidad y, por lo tanto, no pueden cuantificar el grado de incertidumbre sobre el error estructural del modelo. Además, cualquier consejo sobre la estructura del modelo basado en observaciones depende del rango de condiciones ambientales para las que se probaron los modelos y sigue siendo heurístico: no existe una forma única de derivar un modelo a partir de los primeros principios, por lo que los errores siguen siendo inevitables.
Esto nos deja con solo dos formas de explicar, probabilísticamente, el error estructural en un estudio de modelado: extender el PBM con un término de error estocástico[16], o usar un gran conjunto de modelos diferentes y proceder como si fuera uno el modelo en el conjunto debe ser el correcto[17]. En el primer enfoque, la incertidumbre se cuantifica asignando una distribución de probabilidad al término de error estructural. En el segundo enfoque, la incertidumbre está representada por una distribución de probabilidad sobre el conjunto de modelos, con las probabilidades más altas asignadas a los modelos que se consideran más plausibles. Ambos requieren tener en cuenta que el rendimiento del modelo depende no solo de su estructura, sino también de la configuración de los parámetros con sus propias incertidumbres.
6.7.5 Propagación directa de la incertidumbre a los resultados del modelo
Debido a que las mediciones y los modelos tienen errores desconocidos, todo lo que podemos cuantificar son incertidumbres. Por lo tanto, el término común de "propagación de errores" que denota cuánto el error en las entradas contribuye al error en las salidas es un nombre inapropiado. Lo que se propaga es la incertidumbre, no el error. Las salidas pueden tener un error mínimo a pesar de los grandes errores en las entradas, si los errores tienen efectos compensadores. Esta es una ocurrencia común cuando los modelos se ajustan para producir un resultado deseado. Las técnicas, más que el nombre, asociadas con la "propagación de errores" pueden usarse para cuantificar la incertidumbre de la producción, siempre que el modelo sea lo suficientemente simple como para que las derivadas parciales de la producción con respecto a las entradas puedan calcularse analíticamente. Sin embargo, los PBM tienden a ser demasiado complejos para tales enfoques, por lo que la incertidumbre se cuantifica principalmente mediante métodos de Monte Carlo: muestreo de las distribuciones de probabilidad de las entradas del modelo (y estructuras si tenemos un conjunto de modelos) para generar un conjunto representativo de posibles salidas del modelo. En el estudio de Levy, mencionado anteriormente, se utilizó el muestreo de Monte Carlo para cuantificar la contribución de la incertidumbre estructural de los parámetros y modelos a la incertidumbre sobre el sumidero de carbono de un bosque de coníferas en el sur de Suecia[18]. Concluyeron que la incertidumbre del sumidero de carbono era del 92% debido a la incertidumbre de los parámetros, mientras que la incertidumbre estructural del modelo representaba solo el 8%. Las incertidumbres de los parámetros clave fueron la asignación de carbono a hojas, tallos y raíces. Por supuesto, estos resultados dependían de los tres modelos forestales elegidos y del sitio de aplicación único. Reyer y colegas también demostraron la importancia de la incertidumbre de los parámetros, en su caso para la predicción de la productividad forestal futura, pero en una comparación con la incertidumbre sobre los factores climáticos en lugar de la estructura del modelo[19]. Sutton y colegas mostraron la importancia de las incertidumbres sobre los impulsores del modelo (en particular, la deposición de nitrógeno atmosférico) y la estructura del modelo para las predicciones de la productividad forestal en Europa[20]. Minunno y col. encontraron que la incertidumbre sobre las condiciones del suelo (disponibilidad de agua y fertilidad) determinaba principalmente la incertidumbre predictiva de un modelo de crecimiento para Eucalyptus globulus en Portugal[21].
6.8 Bayes y la ciencia
En todas las ciencias, nuestros objetivos son explicar las observaciones y predecir el futuro. Por ejemplo, en ciencias ambientales y ecología, se utilizan predicciones para evaluar el impacto probable del cambio ambiental en los ecosistemas y optimizar la gestión. Los problemas son muy amplios en cuanto a disponibilidad de datos y elección de modelo. Bayes puede ayudarnos en todos los casos a procesar la información de manera óptima. Independientemente de la estructura del modelo, desde la regresión lineal más simple hasta el modelo informático más complejo, los métodos bayesianos se pueden utilizar para cuantificar y reducir las incertidumbres del modelado. Los dos usos más básicos de los métodos bayesianos son para decirnos qué valores de parámetros y qué modelos son plausibles:
1. Estimación de parámetros p [θ | y], donde θ es un escalar o un vector en el espacio de parámetros.
2. Evaluación del modelo p [fi | y], donde fi ∈ {f j} j = 1..n. Cada pregunta científica puede formularse de la siguiente manera: "¿Qué es p [modelo | datos]?".
Esa es solo la forma científica de hacer la pregunta: '¿Qué nos pueden enseñar las observaciones sobre el mundo?' Entonces, todo se trata de distribuciones de probabilidad condicionales, y es por eso que la teoría de la probabilidad, en palabras de Jaynes, en 'la lógica de la ciencia[22]'. De hecho, R.T. Cox ya demostró en 1946 que las leyes de la teoría de la probabilidad pueden derivarse de ideas de sentido común sobre el razonamiento consistente (Jaynes). El mundo de Sherlock Holmes, con pruebas en lugar de probabilidades y deducción en lugar de inducción, no es ciencia. Nada se puede probar incondicionalmente en ciencia, siempre hay supuestos sobre la calidad de nuestros datos y la calidad de nuestros modelos que nos obligan a utilizar un lenguaje probabilístico.
6.8.1 Estimación de parámetros bayesianos
Siempre tenemos cierta incertidumbre acerca de los valores adecuados de los parámetros de un modelo, y expresamos esta incertidumbre como la distribución de probabilidad p[θ]. Cuando llegan nuevos datos y, queremos usar esos datos para reducir nuestra incertidumbre acerca de θ. Como vimos, el teorema de Bayes nos dice cómo cambiar una distribución de parámetro anterior, p[θ], en una distribución posterior para "θ dado y" denotado como p [θ | y]:
Función de posibilidad
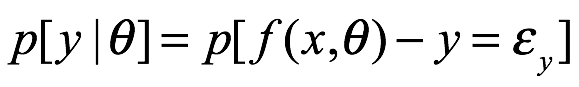
Si asumiéramos además que 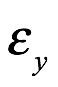 tiene una distribución normal de media cero y un coeficiente de variación del 50%, entonces la función de verosimilitud se simplificaría a
tiene una distribución normal de media cero y un coeficiente de variación del 50%, entonces la función de verosimilitud se simplificaría a 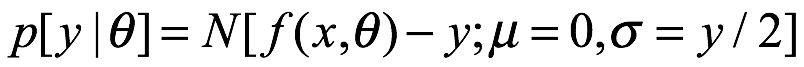 . Digamos que también hemos definido la distribución previa para los parámetros, p[θ], con base en la revisión de la literatura y la opinión de expertos. Luego, el paso final, según lo prescrito por el teorema de Bayes, es encontrar el producto anterior y la probabilidad. En principio, una muestra representativa de la distribución posterior puede generarse fácilmente mediante el muestreo de Monte Carlo: tome una muestra grande de la anterior y use las probabilidades como ponderaciones para decidir qué valores de parámetros conservar. Este sencillo ejemplo captura todos los pasos esenciales en la calibración bayesiana: (1) especifique un previo, (2) especifique
. Digamos que también hemos definido la distribución previa para los parámetros, p[θ], con base en la revisión de la literatura y la opinión de expertos. Luego, el paso final, según lo prescrito por el teorema de Bayes, es encontrar el producto anterior y la probabilidad. En principio, una muestra representativa de la distribución posterior puede generarse fácilmente mediante el muestreo de Monte Carlo: tome una muestra grande de la anterior y use las probabilidades como ponderaciones para decidir qué valores de parámetros conservar. Este sencillo ejemplo captura todos los pasos esenciales en la calibración bayesiana: (1) especifique un previo, (2) especifique  y, a partir de él, la función de verosimilitud, (3) aplique el teorema de Bayes.
y, a partir de él, la función de verosimilitud, (3) aplique el teorema de Bayes.
Después de un análisis bayesiano, habremos reducido nuestra incertidumbre sobre modelos y parámetros. Pero, por supuesto, nos interesará principalmente lo que hemos aprendido sobre el mundo real en sí. Estos problemas aplicados incluyen la previsión, el análisis de riesgos y la toma de decisiones. En cada uno de esos casos, estamos interesados ??en p[z], que estimamos como  . El principal cambio de paradigma que aporta el pensamiento bayesiano a la ciencia es que ya no pretendemos encontrar el mejor valor de parámetro único o el mejor modelo único, sino que pensamos en términos de distribuciones de probabilidad. Nuestro enfoque en los próximos capítulos estará en la estimación de parámetros (p [θ | y]). En capítulos posteriores, consideraremos la comparación o selección de modelos (p [f | y]).
. El principal cambio de paradigma que aporta el pensamiento bayesiano a la ciencia es que ya no pretendemos encontrar el mejor valor de parámetro único o el mejor modelo único, sino que pensamos en términos de distribuciones de probabilidad. Nuestro enfoque en los próximos capítulos estará en la estimación de parámetros (p [θ | y]). En capítulos posteriores, consideraremos la comparación o selección de modelos (p [f | y]).
Defina la distribución previa que incorpora sus creencias subjetivas sobre un parámetro. La distribución posterior es una distribución de probabilidad que representa sus creencias actualizadas sobre el parámetro después de haber visto los datos.
6.8.2 Asignar una distribución previa
No existe la distribución de probabilidad previa de un parámetro o un conjunto de modelos. Una a priori expresa la incertidumbre que surge de un conocimiento incompleto, y cualquiera que sea el tema, las personas tienen conocimientos y experiencia diferentes. Entonces, en lugar de hablar de "la probabilidad previa de x", cada uno de nosotros debería decir "mi probabilidad previa de x". Asignamos una distribución de probabilidad previa, no la identificamos. Este es incluso el caso cuando pedimos la opinión de expertos sobre los valores probables de los parámetros de nuestro modelo. Hay un arte y una ciencia para obtener la opinión de expertos con el fin de formular un prior bayesiano, y se han escrito libros sobre el tema[23], pero en última instancia, la responsabilidad del prior recae en el modelador, no en el panel de expertos. No tenemos total libertad para asignar cualquier distribución. En primer lugar, estamos trabajando dentro de la teoría de la probabilidad, por lo que debemos realizar asignaciones de probabilidad coherentes[24]. Si decimos que p [A] = 0.5, entonces no podemos decir que p [A o B] = 0.4. En general, si tenemos múltiples parámetros en nuestro modelo, entonces nuestra tarea a priori es asignar una distribución de probabilidad conjunta válida a todos los parámetros. Además, cuando tú y yo tenemos exactamente la misma información sobre, digamos, un parámetro θ, entonces deberíamos asignar la misma distribución de probabilidad p[θ]. Cuando el parámetro es por definición no negativo, como lo son la mayoría de las propiedades físicas, entonces una distribución de probabilidad como la gaussiana, que va de menos a más infinito, es inapropiada. Sin embargo, aquí no necesitamos tener demasiados principios. Una distribución gaussiana N[μ, σ2] con media positiva μ y un coeficiente de variación típico σ / μ del 20%, tendrá menos de una millonésima parte de su masa de probabilidad por debajo de cero. Además, cuando se espera que aparezcan muchos datos, entonces el papel del prior se vuelve pequeño: la distribución posterior estará determinada principalmente por la función de verosimilitud. Sin embargo, existe una tendencia entre los investigadores a seleccionar distribuciones previas demasiado amplias y poco informativas. Un ejemplo extremo de esto es la estimación de máxima verosimilitud (MLE), que no requiere que especifiques ninguna distribución previa, y detrás de escena se asume que cualquier valor de parámetro es a priori igualmente plausible. Este es un mal uso de la información y, en general, debe evitarse. Si tiene suficiente información sobre un sistema para construir un modelo para él, con los parámetros que ha proporcionado significado implícito por el papel que desempeñan en su modelo, entonces no es plausible no tener ninguna idea acerca de los valores de los parámetros. Como ejemplo simple, si cree que f (x, θ) = xθ es un modelo adecuado para su sistema, entonces está diciendo que la salida f() responde linealmente a x. ¿Cuándo podría hacer tal afirmación sin tener idea de si la proporcionalidad es negativa, cero o positiva?
6.8.3 Cuantificación de la incertidumbre y MaxEnt
Para evitar los extremos opuestos de ignorar la incertidumbre de los parámetros y asumir que es infinita, el principio general al asignar a priori debería ser elegir esa distribución que exprese la máxima incertidumbre mientras está restringido por cualquier información que tenga. Pero eso plantea la pregunta: ¿cuál es la medida cuantitativa apropiada de incertidumbre? Podemos descartar inmediatamente nuestra varianza, como lo mostrará un ejemplo simple. Tomemos un dado justo, de modo que nuestra incertidumbre sobre el número de puntos que aparecen después del siguiente lanzamiento se distribuya uniformemente como p [i] = 1/6; i ∈ {1..6}. Esa incertidumbre completa tiene una varianza de 2.92, mientras que una distribución mucho menos incierta con p [1] = p [6] = 0.5 y p [i ∈ {2, 3, 4, 5}] = 0 tiene la varianza máxima posible para un dado de seis lados de 6.25 Una medida mucho mejor de la incertidumbre es la entropía S de la distribución, definida para distribuciones de probabilidad discretas como:
Distribución discreta de entropia:
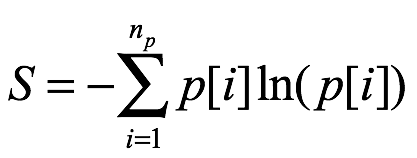 (6.1)
(6.1)
y existe una ecuación similar para distribuciones continuas con una integral que reemplaza la suma. Así como Cox demostró formalmente que el razonamiento racional consistente requiere que sigamos las reglas de la teoría de la probabilidad, Jaynes mostró que para la incertidumbre debemos usar la entropía. Su principio de máxima entropía (MaxEnt) para asignar distribuciones de probabilidad se ha convertido en un enfoque estándar en muchas áreas de la ciencia, e incluso se ha implementado en un R-package llamado FD por Lalibert y Shipley. Probémoslo con el ejemplo del dado justo que acabamos de dar. Solicitamos la distribución de probabilidad discreta sobre {1:6} con máxima entropía bajo la restricción de que la media es igual a 3.5. Eso se puede responder con el siguiente código R muy corto:
> install.packages("FD", repos = c("http://rstudio.org/_packages", "http://cran.rstudio.com"))
library(FD)
Dp <- 1:6 ; meA <- FD::maxent(3.5, Dp)
pA <- meA$prob ; SA <- meA$entropy
SA <- -sum(pA * log(pA)) # = meA$entropy
meB <- maxent(4.5, Dp) ; pB <- meB$prob
meC <- maxent( 13, Dp^2 ) ; pC <- meC$prob
meD <- maxent( c(3.5,16), rbind(Dp,Dp^2) ) ; pD <- meD$prob
meE <- maxent( c(3.5,13), rbind(Dp,Dp^2) ) ; pE <- meE$prob
entropyB <- meB$entropy ; SB <- -sum(pB * log(pB))
entropyC <- meC$entropy ; SC <- -sum(pC * log(pC))
entropyD <- meD$entropy ; SD <- -sum(pD * log(pD))
entropyE <- meE$entropy ; SE <- -sum(pE * log(pE))
# Figura. Distribuciones seleccionadas usando MaxEnt. Entropías entre paréntesis.
# Todas las distribuciones están en el mismo dominio (1, .., 6) pero con diferentes
# restricciones para la media y el cuadrado medio: ver texto.
par(mfrow=c(2,3),mar=c(2,2,3,1))
barplot( pA, main=paste0("A\n(S=",signif(SA,4),")"), names=1:6 )
barplot( pB, main=paste0("B\n(S=",signif(SB,4),")"), names=1:6 )
barplot( pC, main=paste0("C\n(S=",signif(SC,4),")"), names=1:6 )
barplot( pD, main=paste0("D\n(S=",signif(SD,4),")"), names=1:6 )
barplot( pE, main=paste0("E\n(S=",signif(SE,4),")"), names=1:6 )
_________
DpF <- seq(1,6,length.out=51)
meF <- maxent( c(3.5,13), rbind(DpF,DpF^2) ) ; pF <- meF$prob
entropyF <- meF$entropy ; SF <- -sum(pF * log(pF))
DpG <- 1:10
meG <- maxent( c(6,100.5), rbind( DpG, 100+(DpG-5.5)^3 ) ) ; pG <- meG$prob
entropyG <- meG$entropy
SG <- -sum(pG * log(pG))
# Figura. Más distribuciones de MaxEnt. Los dominios cubren 51 y 10 valores posibles.
# Entropías entre paréntesis.
par(mfrow=c(1,2),mar=c(3,2,3,1))
barplot( pF, main=paste0("F\n(S=",signif(SF,4),")"),
names=c( "1", rep("",24), "3.5", rep("",24), "6" ), cex.names=0.3 )
barplot( pG, main=paste0("G\n(S=",signif(SG,4),")"),
names=1:10, cex.names=0.5 )
Este código da pA como la distribución MaxEnt, que graficamos en el panel A de la figura 6.1. Es, como esperábamos, la distribución uniforme que tiene una entropía igual a SA = 1.792. Los otros paneles de la figura 6.1 muestran las distribuciones MaxEnt para cuando tenemos información diferente. El panel B asume una media de 4.5, lo que hace que MaxEnt pendiente de distribución hacia arriba. El panel C asume un valor medio para i2 de 13. El panel D asume una media para i de 3.5 y para i2 de 16. El panel E es como D pero con un cuadrado medio de 13 en lugar de 16.
 19.45.15.png)
Fig. 6.1 Distribuciones seleccionadas usando MaxEnt. Entropías entre paréntesis. Todas las distribuciones están en el mismo dominio (1,…,6) pero con diferentes restricciones para la media y el cuadrado medio: ver texto.
Mostramos dos distribuciones MaxEnt más en la figura 3.2. El panel marcado con F tiene las mismas restricciones que el panel E en la primera figura, pero hemos refinado el dominio de {1,…, 6} a {1.0, 1.1,…, 5.9, 6.0}. Así que hemos pasado de un dado de seis caras a uno de 51 caras. Verá que la distribución se vuelve mucho más acampanada. En el límite de una distribución continua con la media prescrita y la media cuadrática (o varianza), MaxEnt identifica una distribución gaussiana como la más incierta. Entonces, si todo lo que aprende sobre un parámetro son los dos primeros momentos de su distribución, MaxEnt sugiere que asigne una distribución gaussiana. Tenga en cuenta además que las entropías no se pueden comparar para distribuciones sobre diferentes dominios: los valores de entropía S son más altos para la distribución F que para E solo debido a su mayor multiplicidad de dominios. El panel final G muestra un resultado elegante para un dado de 10 caras. La distribución representada fue identificada por MaxEnt dadas las restricciones para la media de i y la media de i 3 (tercer momento), y esto produjo el hermoso patrón de onda como la distribución más incierta. Te dejo para verificar por ti mismo que las distribuciones en las dos figuras tienen la máxima entropía dentro de sus diferentes restricciones, y quizás explorar algunas distribuciones más propias. Existe una rica literatura sobre la máxima entropía y principios relacionados para la asignación de distribuciones de probabilidad previas, y Jaynes es un muy buen lugar para comenzar, al igual que el anterior trabajo de Jeffreys[25]. Una clase especial importante de parámetros identificados por Jeffreys es la de los parámetros de escala, como las desviaciones estándar σ y las varianzas σ2. Estos son parámetros no negativos que indican la escala sobre la que varían otras variables, y Jeffreys y Jaynes demostraron que, sin otro conocimiento, la densidad previa para dichos parámetros debería disminuir inversamente con su magnitud, es decir, p [σ] ∝ 1/σdefinida en el dominio completo desde cero hasta más infinito. Esto se llama Jeffreys Prior. Sin embargo, a menudo tenemos más información sobre la variación que solo la no negatividad, y entonces el Jeffreys Prior no será la opción correcta.
6.8.4 Comentarios finales para Prior
Bayes es omnipresente: la misma metodología bayesiana se utiliza en todas las ciencias. Sin embargo, los problemas prácticos pueden variar entre diferentes tipos de aplicación. En disciplinas donde la información previa es escasa, digamos en el estudio de especies raras, solo podemos asignar distribuciones previas amplias y poco informativas, y debemos ser muy cuidadosos con lo que los datos nos dicen sobre las probabilidades relativas de diferentes valores de parámetros. En otras disciplinas, digamos la agricultura, puede haber mucha información previa pero de fuentes dispares, lo que dificulta la elaboración de una distribución previa adecuada. También puede darse el caso de que esté modelando el comportamiento de una población de organismos o variables que se encuentran dispersas en diferentes ubicaciones. En tales casos, un prior jerárquico puede ser útil.
Cualesquiera que sean las circunstancias, en la mayoría de los casos habrá un grado de subjetividad aparente en la elección previa, porque las personas tienen conocimientos previos diferentes. Por lo tanto, en las publicaciones, es importante indicar claramente qué antecedentes ha elegido y en función de qué información. También será un servicio para el lector si muestra cuánto cambian los resultados de su calibración bayesiana al elegir una anterior diferente.
 12.23.41.png)
Fig. 6.2 Distribuciones MoreMaxEnt. Los dominios cubren 51 y 10 valores posibles. Entropías entre paréntesis.
6.8.5 Asignar una función de verosimilitud
Como científicos, queremos saber cómo parametrizar nuestros modelos, hacer comparaciones con otros modelos y cuantificar la incertidumbre predictiva del modelo. Para todos estos propósitos, se necesitan datos de medición, pero ¿cómo exactamente debemos usar los datos? La respuesta es siempre la misma: en la función de verosimilitud. La probabilidad es una función de densidad de probabilidad condicional, denotada como p [y | θ] (o más sucintamente como L [θ]). Es la respuesta a la pregunta: “¿cuál es la probabilidad de medir y si el valor real es f (x, θ) + modelo?”. Esto se puede escribir formalmente de la siguiente manera:
Función de verosimilitud:
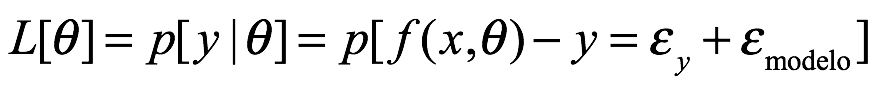 . (6.2)
. (6.2)
Esta definición de la función de verosimilitud se deriva de la ecuación de ciencia. En ese mismo apartado ya proporcionamos una definición simplificada de la función de verosimilitud donde se suponía que el modelo era cero. También ignoraremos en gran medida el error estructural del modelo aquí. Usamos la función de verosimilitud, junto con la distribución previa discutida, en el Teorema de Bayes para derivar la distribución posterior de nuestros parámetros. Pero, al igual que con la distribución previa, no derivamos la función de verosimilitud, tenemos que definirla nosotros mismos. Entonces, aquí hay un elemento de subjetividad: nuestra elección de la función de verosimilitud dependerá de lo que creemos que los datos pueden decirnos. Y eso dependerá de nuestra opinión sobre los posibles errores en los datos. Yo diría que en la práctica, el paso más difícil e importante en la calibración bayesiana es formular una función de verosimilitud apropiada. La verosimilitud es un concepto poderoso y generalmente es multidimensional y puede consistir en mediciones a lo largo del tiempo en varias variables diferentes de suelos y árboles, sin embargo, p [y|θ] siempre se puede definir. Es a través de la función de verosimilitud la calibración bayesiana tiene la capacidad de utilizar conjuntos de datos muy heterogéneos en la estimación de parámetros. Levy y col. utilizaron la calibración bayesiana[26] para conciliar la covarianza de mediciones de emisiones de N2O con mediciones de cámara de los mismos flujos. Patenaude et al. combinaron datos de teledetección de satélites con datos de campo sobre rodales de pino corso en el Reino Unido[27], en calibración bayesiana para los parámetros de PBM 3-PG forestal. Höglind y col. combinaron mediciones en 10 variables diferentes de 5 sitios de pastizales en su función de verosimilitud[28]. Con conjuntos de datos tan ricos, se vuelve importante evaluar si los errores de medición para diferentes variables tienen correlaciones que deberían expresarse en la función de verosimilitud. Formular la función de verosimilitud puede ser difícil, incluso cuando el modelo de error del modelo se puede ignorar y las diferentes variables se miden de forma independiente, porque las mediciones pueden ser incorrectas de tres formas diferentes, como se resume en la siguiente ecuación:
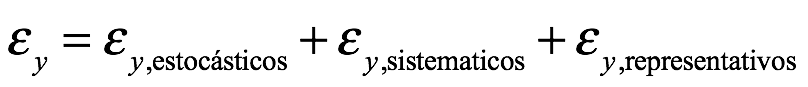 (6.3)
(6.3)
El primero de los tres términos de error de datos, 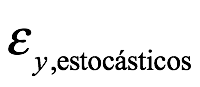 , cuantifica el ruido de medición aleatorio, independiente para cada punto de datos en y, que podríamos representar con una distribución normal con media cero[29]. A menudo, este es el único error de datos reconocido por los modeladores, pero no siempre es el más importante. El segundo término de error,
, cuantifica el ruido de medición aleatorio, independiente para cada punto de datos en y, que podríamos representar con una distribución normal con media cero[29]. A menudo, este es el único error de datos reconocido por los modeladores, pero no siempre es el más importante. El segundo término de error, 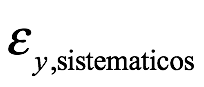 representa un sesgo de medición que podría desplazar colecciones completas de datos hacia arriba o hacia abajo. El término final,
representa un sesgo de medición que podría desplazar colecciones completas de datos hacia arriba o hacia abajo. El término final,  , es generalmente el más difícil de cuantificar. Se refiere a la posibilidad de que nuestros datos se deriven de otras condiciones para las que nuestro modelo está diseñado. Tomemos el ejemplo de un modelo de crecimiento de cultivos. Si el cultivo observado tiene una limitación de crecimiento oculta, digamos deficiencia de fósforo, que no se expresa en el modelo, entonces los datos, desde el punto de vista de la estimación de los parámetros del modelo, subestimarán el crecimiento. A diferencia de los otros dos tipos de errores de medición, el alcance de y, la representatividad no puede reducirse mediante una medición más cuidadosa o una mayor intensidad de muestreo. Para cada conjunto de datos, el modelador y el experto en datos deben distinguir los tres tipos de posibles errores de datos y asignar distribuciones de probabilidad a las respectivas incertidumbres de error. Los parámetros de estas distribuciones de probabilidad, como la desviación estándar del ruido estocástico, pueden especificarse completamente a priori (por ejemplo,
, es generalmente el más difícil de cuantificar. Se refiere a la posibilidad de que nuestros datos se deriven de otras condiciones para las que nuestro modelo está diseñado. Tomemos el ejemplo de un modelo de crecimiento de cultivos. Si el cultivo observado tiene una limitación de crecimiento oculta, digamos deficiencia de fósforo, que no se expresa en el modelo, entonces los datos, desde el punto de vista de la estimación de los parámetros del modelo, subestimarán el crecimiento. A diferencia de los otros dos tipos de errores de medición, el alcance de y, la representatividad no puede reducirse mediante una medición más cuidadosa o una mayor intensidad de muestreo. Para cada conjunto de datos, el modelador y el experto en datos deben distinguir los tres tipos de posibles errores de datos y asignar distribuciones de probabilidad a las respectivas incertidumbres de error. Los parámetros de estas distribuciones de probabilidad, como la desviación estándar del ruido estocástico, pueden especificarse completamente a priori (por ejemplo, 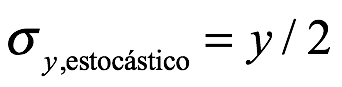 ), o pueden incluirse con los demás parámetros que se estimarán en la calibración. El último método sería preferible en este ejemplo si tenemos poca información sobre la precisión de nuestro instrumento de medición. Van Oijen calibraron el grado de error sistemático en las mediciones de cámara de los flujos de CO2, N2O y NO en el suelo utilizando cuatro PBM forestales diferentes, y las cuatro calibraciones sugirieron que los valores de emisión de CO2 medidos habían sido irrealmente altos[30].
), o pueden incluirse con los demás parámetros que se estimarán en la calibración. El último método sería preferible en este ejemplo si tenemos poca información sobre la precisión de nuestro instrumento de medición. Van Oijen calibraron el grado de error sistemático en las mediciones de cámara de los flujos de CO2, N2O y NO en el suelo utilizando cuatro PBM forestales diferentes, y las cuatro calibraciones sugirieron que los valores de emisión de CO2 medidos habían sido irrealmente altos[30].
Referencias
[1] GOODSTEIN, R.. (2020). ON VON MISES' THEORY OF PROBABILITY. 10.1093/mind/XLIX.194.58.
[2] Van Oijen, Marcel & Rougier, Jonathan & Smith, Ron. (2005). Bayesian calibration of process-based forest models: Bridging the gap between models and data. Tree physiology. 25. 915-27. 10.1093/treephys/25.7.915.
[3] Lindley, D.V. 1991. Making decisions, 2 edition. ed. Wiley, London; New York.
[4] Jaynes, E.T. 2003. Probability theory: The logic of science. Cambridge University Press.
[5] de Wergifosse, Louis & Andre, Frederic & Goosse, Hugues & Caluwaerts, Steven & De Cruz, Lesley & De Troch, Rozemien & Van Schaeybroeck, Bert & Jonard, Mathieu. (2020). CO2 fertilization, transpiration deficit and vegetation period drive the response of mixed broadleaved forests to a changing climate in Wallonia. Annals of Forest Science. 77. 10.1007/s13595-020-00966-w.
[6] Read, Jordan & Jia, Xiaowei & Willard, Jared & Appling, Alison & Zwart, Jacob & Oliver, Samantha & Karpatne, Anuj & Hansen, Gretchen & Hanson, Paul & Watkins, William & Steinbach, Michael & Kumar, Vipin. (2019). Process-Guided Deep Learning Predictions of Lake Water Temperature. Water Resources Research. 55. 10.1029/2019WR024922.
[7] Guceglioglu A.S., Demirors O. (2005) A Process Based Model for Measuring Process Quality Attributes. In: Richardson I., Abrahamsson P., Messnarz R. (eds) Software Process Improvement. EuroSPI 2005. Lecture Notes in Computer Science, vol 3792. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11586012_12
[8] Simidjievski N, Todorovski L, Deroski S (2016) Modeling Dynamic Systems with Efficient Ensembles of Process-Based Models. PLoS ONE 11(4): e0153507. https://doi.org/10.1371/journal.pone.0153507
[9] Wendebourg, Benjamin & Wellmann, Florian & Kukla, Peter. (2020). Quantifying and reducing uncertainty in play mapping by using information entropy and Bayesian inference. First Break. 38. 43-49. 10.3997/1365-2397.fb2020087.
[10] Flechard, Chris & Van Oijen, Marcel & Cameron, David & Vries, Wim & Ibrom, A. & Buchmann, Nina & Dise, Nancy & Janssens, Ivan & Neirynck, Johan & Montagnani, Leonardo & Varlagin, Andrej & Loustau, Denis & Legout, Arnaud & Ziembli?ska, Klaudia & Aubinet, Marc & Aurela, Mika & Chojnicki, Bogdan & Drewer, Julia & Eugster, Werner & Sutton, Mark. (2020). Carbon–nitrogen interactions in European forests and semi-natural vegetation – Part 2: Untangling climatic, edaphic, management and nitrogen deposition effects on carbon sequestration potentials. Biogeosciences. 17. 1621-1654. 10.5194/bg-17-1621-2020.
[11] Mäkelä, Annikki & Rio, Miren & Hynynen, Jari & Hawkins, Michael & Reyer, Christopher & Soares, Paula & Van Oijen, Marcel & Tomé, Margarida. (2012). Using stand-scale forest models for estimating indicators of sustainable forest management. Forest Ecology and Management. 285. 164-178. 10.1016/j.foreco.2012.07.041.
[12] Van Oijen, Marcel. (2017). Bayesian Methods for Quantifying and Reducing Uncertainty and Error in Forest Models. Current Forestry Reports. 3. 10.1007/s40725-017-0069-9.
[13] Jílková, V. & Jandova, Katerina & Cajthaml, Tomas & Devetter, Miloslav & Kukla, Jaroslav & Starý, Josef & Vací?ová, Anna. (2020). Organic matter decomposition and carbon content in soil fractions as affected by a gradient of labile carbon input to a temperate forest soil. Biology and Fertility of Soils. 56. 10.1007/s00374-020-01433-4.
[14] Fer, Istem & Gardella, Anthony & Shiklomanov, Alexey & Serbin, Shawn & De Kauwe, Martin & Raiho, Ann & Johnston, Miriam & Desai, Ankur & Viskari, Toni & Quaife, Tristan & Lebauer, David & Cowdery, Elizabeth & Kooper, Rob & Fisher, Joshua & Poulter, Benjamin & Duveneck, Matthew & Hoffman, Forrest & Parton, William & Mantooth, Joshua & Dietze, Michael. (2020). Beyond Modeling: A Roadmap to Community Cyberinfrastructure for Ecological Data-Model Integration. 10.20944/preprints202001.0176.v1.
[15] Burke, William & Tague, Christina & Kennedy, Maureen & Moritz, Max. (2021). Understanding How Fuel Treatments Interact With Climate and Biophysical Setting to Affect Fire, Water, and Forest Health: A Process-Based Modeling Approach. Frontiers in Forests and Global Change. 3. 10.3389/ffgc.2020.591162.
[16] Hebbal, Ali & Brevault, Loïc & Balesdent, Mathieu & Talbi, El-Ghazali & Melab, Nouredine. (2021). Multi-fidelity modeling with different input domain definitions using deep Gaussian processes. Structural and Multidisciplinary Optimization. 10.1007/s00158-020-02802-1.
[17] Yun, Kyungdahm & Hsiao, Jennifer & Jung, Myung-Pyo & Choi, In-Tae & Glenn, D.M. & Shim, Kyo-Moon & Kim, Soo-Hyung. (2017). Can a multi-model ensemble improve phenology predictions for climate change studies?. Ecological Modelling. 362. 54-64. 10.1016/j.ecolmodel.2017.08.003.
[18] Levy, P.E., R. Wendler, M. Van Oijen, M.G. Cannell, and P. Millard. 2005. The effect of nitrogen
enrichment on the carbon sink in coniferous forests: Uncertainty and sensitivity analyses of three
ecosystem models. Water, air, & soil pollution: Focus 4: 67–74.
[19] Reyer, C.P.O., M. Flechsig, P. Lasch-Born, and M. van Oijen. 2016. Integrating parameter uncertainty
of a process-based model in assessments of climate change effects on forest productivity.
Climatic Change 137: 395–409. https://doi.org/10.1007/s10584-016-1694-1.
[20] Sutton, M.A.,D. Simpson, P.E. Levy,R.I. Smith, S.Reis,M.vanOijen, andW. deVries. 2008. Uncertainties
in the relationship between atmospheric nitrogen deposition and forest carbon sequestration.
Global Change Biology 14: 2057–2063. https://doi.org/10.1111/j.1365-2486.2008.01636.
x.
[21] Minunno, F.,M. van Oijen, D. Cameron, S. Cerasoli, J. Pereira, andM.Tomé. 2013. Using a Bayesian
framework and global sensitivity analysis to identify strengths and weaknesses of two processbased
models differing in representation of autotrophic respiration. Environmental Modelling &
Software 42: 99–115. https://doi.org/10.1016/j.envsoft.2012.12.010.
[22] Jaynes, E.T. 2003. Probability theory: The logic of science. Cambridge University Press.
[23] O’Hagan, A. 2006. Bayesian analysis of computer code outputs: A tutorial. Reliability Engineering
& System Safety 91: 1290–1300. https://doi.org/10.1016/j.ress.2005.11.025.
[24] Lindley, D.V. 1991. Making decisions, 2 edition. ed. Wiley, London; New York.
[25] Robert, C.P., N. Chopin, and J. Rousseau. 2009. Harold Jeffreys’s theory of probability revisited.
Statistical Science 24: 141–172. https://doi.org/10.1214/09-STS284.
[26] Levy, P.E., N. Cowan, M. van Oijen, D. Famulari, J. Drewer, and U. Skiba. 2017. Estimation
of cumulative fluxes of nitrous oxide: Uncertainty in temporal upscaling and emission factors:
Estimation of cumulative fluxes of nitrous oxide. European Journal of Soil Science 68: 400–411.
https://doi.org/10.1111/ejss.12432.
[27] Patenaude, G., R. Milne, M. Van Oijen, C.S. Rowland, and R.A. Hill. 2008. Integrating remote
sensing datasets into ecological modelling:ABayesian approach. International Journal of Remote
Sensing 29: 1295–1315. https://doi.org/10.1080/01431160701736414.
[28] Höglind, M.,M. Van Oijen, D. Cameron, and T. Persson. 2016. Process-based simulation of growth
and overwintering of grassland using the BASGRA model. Ecological Modelling 335: 1–15.
https://doi.org/10.1016/j.ecolmodel.2016.04.024.
[29] Ogle, K., and J.J. Barber. 2008. Bayesian DataModel integration in plant physiological and ecosystem
ecology. In Progress in Botany, Progress in Botany, ed. U. Lüttge, W. Beyschlag, and J.
Murata, 281–311. Berlin Heidelberg: Springer.
[30] Van Oijen, Marcel & Cameron, David & Levy, Peter & Preston, Rory. (2017). Correcting errors from spatial upscaling of nonlinear greenhouse gas flux models. Environmental Modelling & Software. 94. 157-165. 10.1016/j.envsoft.2017.03.023.
Autores:
Eduardo Ochoa Hernández
Nicolás Zamudio Hernández
Berenice Yahuaca Juárez
Erasmo Cadenas Calderón
Abraham Zamudio Durán
Lizbeth Guadalupe Villalon Magallan
Pedro Gallegos Facio
Gerardo Sánchez Fernández
Rogelio Ochoa Barragán
Monica Rico Reyes