Campos vectoriales
Y teoría electrostática

Unidad 6.
Ecuaciones de Maxwell

La mecánica newtoniana es adecuada para la mayoría de los propósitos de la “vida cotidiana”; sin embargo, para objetos que se mueven a altas velocidades (cercanas a la velocidad de la luz) resulta incorrecta y debe ser reemplazada por la relatividad especial (introducida por Albert Einstein en 1905). Para objetos extremadamente pequeños (cerca de las escalas atómicas) también falla, por razones distintas, y es sustituida por la mecánica cuántica (desarrollada por Niels Bohr, Werner Heisenberg, Erwin Schrödinger y muchos otros). Para fenómenos que involucran objetos que son, a la vez, muy rápidos y muy pequeños —como ocurre con frecuencia en la física de partículas moderna— se requiere una formulación matemática que combine la relatividad con los principios cuánticos. Esta estructura teórica se conoce como teoría cuántica de campos. Fue desarrollada principalmente entre las décadas de 1930 y 1940; sin embargo, incluso hoy no puede afirmarse que su cultivo pedagógico esté plenamente consolidado en el ámbito de la educación. A pesar de ello, este campo teórico constituye una de las construcciones más coherentes entre teoría y experimento en la física contemporánea, pues describe con notable precisión los fenómenos observados en los laboratorios. El presente contenido es una invitación a aprender a leer esta teoría, de modo que puedan abordarse preguntas fundamentales sobre la realidad de los campos eléctricos. El siguiente desarrollo narrativo representa un esfuerzo por aprender a leer la belleza de las ecuaciones de James Clerk Maxwell. Para ello, se asume que el lector conoce ciertos objetos matemáticos necesarios para comprender los modelos aquí descritos.
6.0 El observador
Nosotros y otros animales nos damos cuenta de lo que sucede a nuestro alrededor. Esto nos ayuda, sugiriéndonos lo que podríamos esperar e incluso cómo prevenirlo, y así fomentar la supervivencia. Sin embargo, la experiencia sensorial solo funciona de manera imperfecta. Hay sorpresas, y son inquietantes. ¿Cómo podemos saber cuándo tenemos razón? Nos enfrentamos al problema del sesgo, el error y la mala interpretación semántica. Estas son preocupaciones sobre nuestro conocimiento del mundo externo. Para lidiar con ellas, hemos tenido que volvernos hacia dentro, cultivando el carácter, el coraje y la humildad intelectual para investigar el sustento de la disertación y la medición empírica del conocimiento con que nos hacemos de nuestro saber. “Conócete a ti mismo”: el mandato se atribuye a Sócrates e incluso a Tales, supuestamente el padre de la filosofía.
Tales y sus sucesores se preocupaban por el hombre y sus errores; especulaban sobre el cosmos. Pero la ansiedad por el problema del error continuó a lo largo de la antigüedad griega. Las paradojas de Zenón fueron calculadas para mostrar las limitaciones de nuestro juicio, al igual que los sofismas de los sofistas. Los escépticos se tomaron muy en serio las melancólicas conclusiones. ¿Cómo sabemos las cosas? Platón sostenía que lo hacemos aprendiendo las ideas, que son las esencias de las cosas. Pensaba que nacíamos conociendo estas formas axiomáticas (verdades evidentes) y sus interrelaciones de una manera difusa, y que podían ser puestas en foco por el diálogo socrático. Parece que en uno de los diálogos, Menón, Platón llegó a esta teoría pensando en la argumentación matemática a partir de verdades evidentes por sí mismas. De alguna manera, sin embargo, también se acomodó a la observación. “Salva las apariencias”, escribió. Aristóteles trató de apuntalar las formas de conocimiento. Formalizó el silogismo (argumento). El conocimiento mismo, sin embargo, superó al conocimiento sobre el conocimiento. La historia natural latía en las manos de Aristóteles, y las matemáticas en las de Eudoxo y Euclides. Eratóstenes incluso calculó el tamaño de la Tierra, casi con suficiente precisión.
Pero la oscuridad descendió, y las tinieblas del mito y el misticismo se asentaron durante mil años. Las formas de conocimiento se redujeron a una: la autoridad superior de una jerarquía política o religiosa. Los restos de Aristóteles se consideraban de autoridad, pero ¿cómo lo había sabido? Se avecinaba una regresión infinita. El problema fue archivado al postular la revelación sobrenatural, sin plantear la pregunta. Roger Bacon lo suplicó alrededor de 1290, adoptando la observación y la experimentación. Dos siglos y medio después, Copérnico hizo el gran avance que puso a la ciencia inequívocamente en el camino ascendente. Durante catorce siglos, los astrónomos rezagados habían luchado con los epiciclos ptolemaicos para sistematizar una astronomía centrada en la Tierra; pero al final, Copérnico puso a nuestro planeta en su lugar y lo puso en movimiento.
Así inspirado, Francis Bacon retornó a la vieja cuestión de los modos de conocimiento. El espíritu de Roger Bacon se despertó, pero ahora con más sustancia y sofisticación: la sabiduría de la retrospectiva. La ciencia se abría abierto paso, aunque los tradicionalistas intentaron contenerla. Un siglo después de Copérnico, el clero enjuició a Galileo por abrazar la herejía copernicana. Uno piensa en los creacionistas de hoy, ciento treinta años después de El origen de las especies de Darwin. A pesar de los obstáculos, la ciencia alcanzó su pleno florecimiento cincuenta años después de la obra de Galileo. Floreció en la obra de Newton, Principia Mathematica (1687).
Mientras tanto, en el ámbito filosófico más amplio, estaba Thomas Hobbes. Era veinticuatro años más joven que Galileo y se inspiró en los avances de este. Hobbes profesaba el materialismo absoluto, de hecho el mecanicismo, como Demócrito dos mil años antes: no hay nada más que materia en movimiento. El pensamiento es movimiento en el cerebro.
La visión de Hobbes del conocimiento era sorprendentemente moderna. Nuestras sensaciones son los efectos sobre nosotros del mundo material, que de otro modo sería incognoscible. Es en ellas en las que basamos nuestras ideas sobre el mundo, y no tenemos nada más que el entramado de las ideas. Hobbes usaba la palabra “idea” en su sentido moderno de argumento, para significar algo así como un pensamiento justificado. Era una extraña inversión del uso de Platón. Para Platón, las ideas o formas habían sido la realidad por excelencia; las cosas del mundo material eran sus falsificaciones imperfectas. Para Hobbes, y para nosotros, las ideas son más bien el vacilante intento del hombre de abarcar la realidad material.
René Descartes era ocho años menor que Hobbes. Era un dualista: reconocía tanto la mente como la materia. Descartes se aferró más vigorosamente a la cuestión de cómo sabemos. En su famoso experimento mental, partió de cero. Trató de dudar de todo, pero descubrió que no podía dudar de que estaba dudando. Llegó a la conclusión de que existía, como una acción de la mente. Luego procedió a demostrar la existencia de Dios. Sintiendo que allí había un terreno más traicionero, ofreció cuatro pruebas. La existencia de la materia se produjo entonces fácilmente a partir de la existencia de Dios y, puesto que Dios es bueno por definición, no nos daría una idea clara y distinta que fuera falsa.
Tal era, a grandes rasgos, la teoría de Descartes sobre cómo conocemos. Las ideas claras y distintas son conocimiento y dadas por Dios; las ideas confusas no lo son. Hay aquí ecos de la doctrina de Platón sobre el conocimiento innato y la reminiscencia, así como de la doctrina hebrea y cristiana de la revelación divina. Pero la parte platónica puede haber sido un caso de inspiración paralela más que de herencia. El punto de vista de Platón estaba evidentemente inspirado en las matemáticas, y Descartes era un matemático.
En el quinquenio 1646-1650 vivieron cinco pensadores neoclásicos: Hobbes, Descartes, Spinoza, Leibniz y Locke. En la historia de la epistemología, la siguiente figura importante después de Descartes es John Locke. Locke rechazó la epistemología teológica de Descartes. Al igual que Hobbes, veía el conocimiento en la coherencia de las ideas. Aceptaba el mundo material como real, pero solo lo conocíamos tentativamente, a partir de conjeturas basadas en ideas. Las impresiones sensoriales, causadas por el mundo material, implantan nuestras ideas simples; construimos o abstraemos todas las demás ideas a partir de ellas. A diferencia de Descartes, Locke repudiaba las ideas relacionadas solo con otras ideas. Suscribió el manifiesto empirista: nihil in mente quod non prius in sensu (no hay nada en la mente que no haya estado primero en los sentidos).
Locke no explicó cómo formar ideas complejas de objetos materiales o ficticios sobre la base de impresiones sensoriales simples. Escribió sobre la asociación de ideas por contigüidad, sucesión y semejanza, pero este es solo el comienzo más escueto de lo que se incluye en el informe más primitivo sobre el mundo material que nos rodea. ¿Qué hay de nuestra identificación de un cuerpo observado intermitentemente como el mismo cuerpo? Un cuerpo idéntico puede tener un aspecto diferente con el tiempo, y diferentes cuerpos pueden parecerse. Quedaba mucho por explicar.
El obispo George Berkeley, cincuenta años más joven que Locke, no veía nada convincente en la conjetura de Hobbes o Locke sobre un mundo material. Nada existe, sostenía Berkeley, sino lo que se percibe directamente. ¿Nada, por lo tanto, sino patrones sensoriales o ocurrencias de patrones sensoriales? No, era más generoso que eso. Admitió almas; nosotros percibimos las nuestras. Y, de alguna manera, admitió a Dios. Hecho esto, Berkeley provee la persistencia de las cosas independientemente de si son percibidas por el hombre o la bestia, o cuándo; porque permanecen fielmente percibidas por Dios. La negación de la materia por parte de Berkeley, entonces, parecería ser una cuestión de palabras.
David Hume, veintiséis años menor que Berkeley, aceptó más bien la conclusión de que simplemente no hay evidencia de la existencia continuada de un objeto entre una ocasión y otra en la que lo percibimos. La identificación misma de él como el mismo objeto, en una ocasión y en la otra, es, en su opinión, una confusión de identidad con semejanza. Locke, Berkeley y Hume fueron los empiristas británicos clásicos, y sus escritos pertinentes aparecieron entre los años 1690 y 1757. Todos coincidieron en que nuestra tradición sobre el mundo es un tejido de ideas basadas en impresiones sensoriales. En cuanto a los detalles estructurales de la tela y su fabricación, los tres carecían de los rudimentos de un relato. La idea es una caña frágil.
Como observó Wittgenstein, incluso una simple cualidad sensorial es difícil de alcanzar a menos que esté respaldada por el lenguaje público. Un individuo podría considerar muchos eventos sensoriales como recurrencias de una cualidad por la semejanza de cada uno con el siguiente, a pesar de una acumulación sustancial de ligeras diferencias. La nomenclatura y el monitoreo público son los que detienen esa deriva. Las desviaciones aleatorias de los hablantes individuales se mantienen dentro de los límites de la comunicación entre ellos. Las palabras públicas en forma de literatura anclan las ideas.
La apelación a la idea sigue siendo un uso popular neutral. Se dice que el propósito del lenguaje es la comunicación de ideas. Aprendemos una palabra de nuestros mayores asociándola con la misma idea y la usamos en la comunicación de ideas, pero no recibimos ni damos un proceso de justificación de ellas. ¿Cómo sabemos que las palabras que usamos para expresar nuestras ideas están evocando las mismas ideas en la mente de nuestros oyentes? Las palabras y el comportamiento observable son todo lo que tenemos para continuar, y la idea de la idea proporciona solo la ilusión de una explicación. John Horne Tooke insistió en este punto en 1786, diez años después de la muerte de Hume: “Solo deseo que lea de nuevo el ensayo de Locke con atención para ver si todo lo que su inmortal tauro ha concluido justamente nos será igualmente verdadero y claro, si sustituyo la composición de términos donde él ha supuesto una composición de ideas. La mayor parte del ensayo de Locke, es decir, todo lo que se relaciona con lo que él llama la abstracción, la complejidad y la generalización de las ideas, en realidad concierne meramente al lenguaje”.
Tooke era un alma gemela de su lejano predecesor Guillermo de Ockham y de otros nominalistas medievales, que habían descartado los objetos abstractos como flatus vocis (brisa vocal). Lo de Tooke fue un paso importante hacia lo que Richard Rorty ha llamado el giro lingüístico. Si se puede dar sentido a la composición de ideas, se puede dar un sentido más claro a la composición del lenguaje. Las palabras, a diferencia de las ideas, están afuera, donde podemos ver lo que estamos haciendo, así se abre un paso decisivo a la escritura de disertación de hoy.
Mucha más libertad en la construcción de las ideas fue lograda por Jeremy Bentham unos años más tarde en su teoría de las ficciones. Observó que, para explicar un término, no necesitamos componer una frase sinónima. Solo tenemos que explicar todas las frases en las que nos proponemos utilizar el término. Es lo que ahora se llama definición contextual. El motivo de Bentham era ontológico: quería ser capaz de introducir uno u otro término útil sin que se le acusara de suponer algún objeto controvertido para que lo designara, u objetos para que los denotara. De esta manera, el objeto u objetos aparentes podrían ser descartados como ficciones inocentes. El objetivo de toda la empresa científica es inculcar la facilidad para comprender y producir oraciones correctas y útiles.
Al aprender nuestra lengua materna zigzagueamos de manera similar. Aprendemos una sentencia simple como un todo, y luego proyectos una palabra componente de ella por analogía en la construcción de otra oración. Hoy en día, una apreciación de la definición contextual, ha prestado apoyo a la visión de las oraciones como los vehículos primarios del significado. Es un. Punto de vista Gottlob Frege defendió vigorosamente un siglo después de Bentham.
La definición contextual se repitió en las matemáticas unas décadas más tarde de la contribución de Bentham, de la mano de George Boole. Boole es más conocido como filósofo e ingeniero informático pionero de la lógica moderna, pero sus definiciones contextuales fueron más bien una contribución al cálculo diferencial. Son conocidos como el método de los operadores. Los adeptos al cálculo reconocerán  11.56.58.png) como una cantidad por derecho propio, y
como una cantidad por derecho propio, y  11.57.42.png) como un prefijo u operador que no representa nada por derecho propio. Pero la innovación de Boole consistió en abreviar una suma como:
como un prefijo u operador que no representa nada por derecho propio. Pero la innovación de Boole consistió en abreviar una suma como:
 12.04.34.png)
Así manipuló como si representara una suma de tres cantidades genuinas multiplicadas por f(xy,z). Los tres operadores y sus sumas ostensibles representan cantidades ficticias, para decirlo desde el punto de vista de Bentham. El concepto agiliza el cómputo, y es ampliamente utilizado en el cálculo diferencial variacional.
Fue este mismo ejemplo el que inspiró la conocida definición contextual de Bertrand Russell de la descripción singular: Para una descripción definida "el x tal que φ(x)", la expresión se traduce en la siguiente fórmula lógica:
∃x(φ(x)∧∀y(φ(y)→y=x))
∃x: Existe al menos un elemento x.
φ(x): x cumple con la propiedad φ.
∀y(φ(y)→y=x): Para cualquier elemento y, si y cumple con la propiedad φ, entonces y es igual x.
En conjunto, la fórmula afirma que existe un único elemento x que satisface la propiedad φ. Es decir, hay exactamente un x tal que φ(x) es verdadero.
Esto se interpreta como: "Existe un x tal que φ(x) es verdadero, y para todo y, si φ(y) es verdadero, entonces y es igual a x". En otras palabras, existe un único x que cumple con la propiedad φ. Este análisis permite descomponer descripciones definidas en componentes lógicos que pueden ser evaluados sin asumir la existencia de la entidad descrita. De esta manera, se puede determinar la verdad o falsedad de una oración sin que la descripción definida tenga una referencia real en el mundo. Es decir, las descripciones definidas deben analizarse en términos de cuantificadores lógicos y variables, lo que permite reformular oraciones que contienen tales descripciones sin asumir la existencia de la entidad descrita. Una descripción singular puede ser útil en una oración incluso cuando aún no estamos seguros de la existencia de uno y solo un objeto como el que la descripción pretende designar.
El heroico proyecto de Russell de 1910 consistía en clarificar toda la intrincada estructura de la matemática clásica, derivando sus conceptos principales paso a paso, y definición tras definición, a partir de una delgada base de términos primitivos claros y sencillos, y derivando sus leyes principales a partir de axiomas y unos cuantos postulados.
Axiomas: proposiciones consideradas universalmente verdaderas y evidentes por sí mismas, sin necesidad de demostración. Se aplican de manera general en múltiples campos de la ciencia y las matemáticas. Por ejemplo, en aritmética, el axioma que establece que "si a es igual a b, entonces b es igual a a" es una verdad aceptada sin necesidad de prueba.
Postulados: Son proposiciones que, aunque no necesariamente evidentes, se aceptan como verdaderas dentro de un contexto o sistema específico para construir teorías o resolver problemas. Por ejemplo, en geometría euclidiana, el postulado que afirma que "por dos puntos cualesquiera pasa una única línea recta" es una suposición aceptada para desarrollar la teoría geométrica.
Tal proyecto había parecido factible debido a los avances revolucionarios en la lógica en la segunda mitad del siglo XIX, de la mano principalmente de Frege, Charles Sanders Peirce y Peano. Los avances en la clarificación de las matemáticas básicas, Russell los había correspondido organizando, refinando y extendiendo estos comienzos; integrándolos en un todo orgánico e imponente. Todo el esquema conceptual matemático clásico se reduce a comprender funciones de verdad, cuantificadores lógicos y el predicado. Lo que motivó a Russell fue la naturaleza del conocimiento matemático y la base de la verdad matemática. La conclusión a la que llegaron fue que las matemáticas son traducibles a lógica pura. De modo que la verdad matemática es una verdad lógica, razonaron, y por lo tanto, toda ella debe ser lógicamente deducible de las lógicas evidentes por sí mismas. Esto es erróneo, como se desprende en parte del artículo de Kurt Gödel de 1931 y en parte de los hallazgos del propio Russell en 1902.
Esta empresa perdida no era el único punto de la gran empresa de Russell. Su otro objetivo, y su valor perdurable, era simplemente una comprensión más profunda de los conceptos centrales de las matemáticas y sus leyes e interrelaciones básicas. Su total traducibilidad a una lógica elemental, y a un solo predicado familiar de dos lugares, la pertenencia, es en sí misma una sensación filosófica. La lógica moderna fue indispensable para este logro. Un factor esencial, de una pieza con la lógica moderna, era la definición contextual. Animado por su logro, Russell reflexionó en 1914 sobre realizar el sueño de los epistemólogos empiristas: la construcción explícita del mundo externo, o un facsímil razonable, a partir de impresiones sensoriales, por lo tanto, a partir de ideas simples.
Realizar el sueño de los epistemólogos empiristas: la construcción explícita del mundo externo, o un facsímil razonable, a partir de impresiones sensoriales, por lo tanto, a partir de ideas simples. Lo esbozó en nuestro conocimiento del mundo exterior, y una docena de años más tarde, Rudolf Carnap se comprometía a llevarlo a cabo. El esfuerzo de Carnap encontró en 1928 que los bloques de construcción debían ser elementos sensoriales, como las construcciones soñadas por los antiguos empiristas británicos. Es decir, los axiomas clásicos son de origen biológico. Unidades elementales de experiencia de lo real. La relación básica de Carnap entre las experiencias elementales era recordar como algo similar, lo llamó R. Una experiencia elemental X lleva R a otra, y si X incluye un recuerdo de Y que se parece parcialmente a X. Las experiencias elementales son: reconocer la unidad y cantidad; organizar en categorías el todo; reconocer el concepto de causa y efecto como correlación; reconocer la probabilidad; y finalmente, responder con operadores lógicos a la necesidad de distinguir verdad y falsedad. Al final, la claridad lógica, aunque poderosa, no puede encapsular por completo la riqueza de la realidad que nos rodea.
La experiencia elemental: es cualquier cosa que lleva R a algo. Esto se puede expresar en términos de R y lógica. Es un círculo de semejanza, donde se puede mover de lo elemental a lo más grande en el sentido de una creciente creación de objetos matemáticos más complejos. Esto lleva al punto en el que se define la noción de una cualidad sensorial. Esta definición también muestra el ingenio de Carnap. Pone su mirada en las clases de cualidad, siendo una clase de cualidad la clase de todas las experiencias elementales que representan una cualidad dada. Si la experiencia es razonablemente variada y aleatoria, se limita a identificar las cualidades con la clase de cualidad. Este movimiento Carnap lo llamó análisis.
Carnap define la semejanza de las cualidades, explorando la semejanza parcial de las experiencias elementales. A partir de esta base, logra definir los cinco sentidos: vista, olfato, gusto, oído y tacto. Cada sentido es una clase más amplia de cualidades que están conectadas entre sí por cadenas de similitudes. Los cinco sentidos se distinguen entre sí, rompiendo estas cadenas; ninguna calidad visual es similar a la auditiva. Finalmente, cada uno de los cinco sentidos puede ser identificado por su dimensionalidad. Como señala Carnap, cada uno tiene un número diferente de dimensiones. Por ejemplo, la vista tiene dimensiones espaciales, simetría y traslación. La dimensión en sí misma es definible matemáticamente y, en última instancia, por la lógica.
¿Por qué todas estas ingeniosas y laboriosas construcciones mentales? Carnap quería identificar los determinantes mínimos esenciales de la experiencia sensorial. Estaba haciendo plausible que uno pudiera continuar de esta manera y distinguir, por definición, cada cualidad sensorial y cada posición visual. Dada esta base sensorial completa, entonces emprendería el gran proyecto de construir, de alguna manera, sobre ella nuestro sistema completo de realidad física.
La idea de un lenguaje sensorial autosuficiente como base de la ciencia pierde su brillo cuando reflexionamos sobre el hecho de que la sistematización de nuestra ingesta sensorial es el mismo asunto al que se dedica la ciencia misma. Los recuerdos que vinculan nuestras experiencias pasadas con las presentes e inducen nuestras expectativas son, en su mayoría, recuerdos que no son de ingesta sensorial, sino de postulados esencialmente científicos, es decir, cosas y eventos en el mundo físico, químico y biológico. Tal vez fue la apreciación de este punto lo que llevó a Otto Neurath, colega de Carnap en Viena, a persuadir a Carnap de que abandonara su fenomenalismo metodológico en favor del fisicalismo.
Aunque Carnap había presentado la orientación fenomenal de su proyecto de “reconstrucción racional” como una elección esencialmente pragmática, carente de implicaciones metafísicas, es probable que Neurath la interpretara de manera distinta: como una aceptación implícita de un dualismo cartesiano entre mente y cuerpo o, en el mejor de los casos, como una forma atenuada de monismo mentalista. Frente a ello, el fisicalismo se define explícitamente como una postura materialista, monista y directa, con la única salvedad de los objetos abstractos propios de las matemáticas. Sin embargo, Carnap no transitó hacia esta supuesta alternativa pragmática consistente en un sistema constitucional fundado en una ciencia basada en la física. Por el contrario, orientó su trabajo hacia líneas sustancialmente distintas dentro de la filosofía y la lógica de la ciencia.
Si se hubiera desarrollado de manera sistemática esta alternativa fisicalista, pueden distinguirse, al menos, dos direcciones posibles. La primera, centrada exclusivamente en la economía conceptual y en la búsqueda de claridad formal en el espíritu del Principia Mathematica, es en gran medida la vía que los físicos del polo teórico han seguido desde hace tiempo, aunque en ella la intervención del lógico podría constituir una contribución bienvenida, proporcionando una articulación más rigurosa y explícita de los fundamentos formales.
La segunda dirección, más cercana en su ambición estructural al Aufbau de Carnap, es aquella que aquí identificamos como naturalismo. Se trata de una reconstrucción racional del proceso real mediante el cual el individuo —y, por extensión, la especie— adquiere una teoría responsable del mundo externo. Este enfoque aborda directamente la cuestión de cómo nosotros, en tanto habitantes físicos de un mundo físico, hemos podido proyectar una teoría científica comprensiva de ese mundo a partir de contactos extremadamente limitados con él: contactos reducidos, en última instancia, a impactos elementales de rayos y partículas sobre nuestras superficies sensoriales, junto con experiencias corporales mínimas, como el esfuerzo físico implicado en ascender una pendiente.
Desde nuestra perspectiva, esta empresa forma parte inseparable de la propia ciencia empírica. La reconstrucción racional solo se interrumpe allí donde aparecen intersticios conjeturales o donde la complejidad del accidente histórico desborda la comprensión esquemática que se persigue. La motivación sigue siendo, en un sentido profundo, filosófica, como lo ha sido tradicionalmente la motivación de las ciencias naturales; sin embargo, la investigación progresa sin respetar fronteras disciplinares rígidas, aunque sí con un reconocimiento explícito del valor propio de cada disciplina y con una disposición abierta a integrar sus aportaciones.
A diferencia de los pensadores clásicos, no buscamos hoy un fundamento más firme para la ciencia que la propia ciencia. Esta renuncia a un punto de apoyo externo nos libera para emplear los resultados y métodos de la ciencia en la investigación de sus propios orígenes, supuestos y condiciones de posibilidad. Como ocurre siempre en la práctica científica, se trata de abordar un problema valiéndose de las respuestas provisionales obtenidas en otros ámbitos, en un proceso continuo de ajuste, corrección y esclarecimiento mutuo.
Este es el escenario para replantear el estatuto mismo de la reconstrucción racional. La oposición entre fenomenalismo, fisicalismo y naturalismo no aparece aquí como una taxonomía doctrinal, sino como una interrogación sobre los límites legítimos del conocimiento científico y filosófico. Especialmente valiosa es la reivindicación del naturalismo como una forma de continuidad entre ciencia y filosofía, no como su reducción. El gesto de abandonar la búsqueda de fundamentos extrínsecos y aceptar que la ciencia se interroga a sí misma con sus propias herramientas marca una ruptura decisiva con la tradición fundacionalista y sitúa este manuscrito en una línea claramente contemporánea, afín a Quine, pero elaborada con un cuidado conceptual que evita el simplismo.
Evaluación 1__________
6.1 Gravedad
Un concepto tan familiar, presente en todos los lenguajes y culturas, pero que los científicos han luchado por comprender durante milenios. Es el milagro general que conecta todo, en todas partes, para siempre en el Universo. Universal en todos los sentidos. Como humanos, podemos pensar en ella como la fuerza oculta que nos mantiene firmemente plantados en la Tierra, la razón por la que la Tierra órbita alrededor del sol o la interacción que permitió la formación de la Vía Láctea y sus cientos de miles de millones de estrellas. Pero eso apenas insinúa su verdadero significado. La gravedad es la razón por la que el propio Universo puede incluso existir y evolucionar. Eleva el espacio y el tiempo de meros pedazos de escenografía a actores centrales en el drama que se desarrolla de la realidad. A medida que abrazamos la gravedad, no podemos evitar enfrentarnos a ella: saltando, flotando o volando mientras perseguimos breves momentos de libertad de su mando.
Al darse cuenta de que la gravedad debe ser una fuerza universal, que actúa sobre todo y acelera a todos de la misma manera, independientemente de su masa, Galileo, Kepler y Newton proporcionaron la primera pieza crucial del rompecabezas. Esta visión fue posible gracias a una nueva perspectiva sobre lo que significa ser libre, una perspectiva que descartó el dogma aristotélico y transformó radicalmente el concepto de inercia.
Esta nueva perspectiva salió a la luz en 1632, con la publicación del "Diálogo". Galileo abogó por una nueva revolución copernicana, que iba más allá de la mera negación de que la Tierra ocupara un lugar especial en el sistema solar, descartando aún más la idea de que cualquier persona y objeto pudiera tener una posición privilegiada con respecto a las leyes de la naturaleza.
Para hacer este argumento, Galileo consideró el mundo a través de los ojos de un marinero confinado en la cabina principal debajo de las cubiertas de un barco en movimiento. Incapaz de ver el mundo exterior, un marinero se entretenía observando el movimiento de "algunas moscas y mariposas" que compartían en su camarote. Galileo se dio cuenta de que el marinero no sería capaz de decir si la nave estaba en reposo o en movimiento a velocidad constante, al menos no observando a estos pequeños animales voladores. ¿Por qué? Porque si el barco se mueve a velocidad constante, también lo hace todo a bordo, incluido el aire en el que revolotean las moscas y las mariposas. El marinero, atrapado debajo de la cubierta, solo puede observar el movimiento de las criaturas voladoras en relación con el interior de la cabina del barco. Galileo utilizó este experimento mental, que destacaba la importancia del movimiento relativo, para explicar cómo la Tierra podía girar sin que pudiéramos sentirlo. Además, una vez que reconocemos que no podemos diferenciar entre la cierta inferior de un barco en reposo y la de uno en movimiento uniforme, podemos inferir que las leyes de la física deberían ser las mismas independientemente de la velocidad.
Es precisamente esta noción de "relatividad galileana", la comprensión de que las leyes de la naturaleza son las mismas independientemente de quién las describa, la que está consagrada en la primera ley del movimiento de Newton, que sostiene que todo objeto permanecerá en reposo o en movimiento uniforme en línea recta a menos que se le aplique una fuerza externa. Newton se dio cuenta de que ser libre es el privilegio de seguir adelante sin ser molestado, continuando el viaje a la misma velocidad, uniformemente. Basándose en el trabajo de Kepler, quien desarrolló las leyes del movimiento planetario, esta idea conduciría más tarde a la ley de la gravitación universal de Newton en 1687, también conocida como la ley del cuadrado inverso de Newton. De acuerdo con esta ley, la fuerza de gravedad ejercida entre dos partículas masivas cualesquiera (es decir, partículas que tienen masa) es una fuerza universal e instantánea, cuya intensidad decae como el cuadrado de la distancia entre las dos partículas.
La ley de Newton, como muchos de nosotros hemos aprendido, describe cómo un objeto, cuando se deja caer, es inexorablemente atraído por la masa de la Tierra. Pero la naturaleza universal de la gravedad se extiende mucho más allá de este fenómeno. Se aplica a todo y a todos, sin importar el objeto, sin importar la separación. En 1798, Henry Cavendish fue uno de los primeros en probarlo formalmente en un laboratorio, y más de dos siglos después de su descubrimiento, la ley del cuadrado inverso de Newton ha sido examinada con una precisión impecable, desde distancias menores a una milésima parte del ancho de un cabello humano hasta separaciones que se extienden a lo largo de miles de millones de kilómetros. De hecho, la ley de la gravitación universal de Newton es tan fundamental que todavía se puede utilizar para predecir cómo la gravedad ha gobernado la mayor parte de la evolución de nuestro Universo, desde el colapso gravitacional de la materia oscura hasta la formación de cúmulos de galaxias y la creación del sistema solar.
Pasaron siglos antes de que la evidencia observacional comenzara a arrojar una pizca de duda sobre la ley de gravedad de Newton. Sin embargo, en retrospectiva, la idea de que la atracción gravitacional entre dos objetos cualesquiera ocurre instantáneamente debería haber levantado una bandeara roja. De acuerdo con la ley de Newton, si aparecieran dos partículas, serían inmediatamente atraídas entre sí sin demora. No importa cuáles sean sus puntos de vista sobre la atracción, todos sabemos que este fenómeno no puede ser inmediato. Incluso cuando se trata de amor a primera vista, primero necesitas “ver” a la otra persona (es decir, comunicarte, aunque no sea verbalmente) para que se produzca la atracción. El propio Newton, en una carta a Richard Bentley, expresó su incomodidad con el concepto de una ley instantánea: “es inconcebible que la materia bruta inanimada opere (sin la mediación de otra cosa que no sea material) y afecte a otra materia sin contacto mutuo; como debe ser, si la gravitación en el sentido de epicúreo es esencial e inherente a ella. Y esta es la razón por la que deseaba que no me atribuyeras gravedad innata[1]”.
Nuestro propio viaje comienza dos siglos después, cuando los científicos estadounidenses Albert Michelson y Edward Morley revelaron los resultados de su "experimento fallido", marcando el comienzo de una nueva revolución científica. Poco después, Einstein introdujo nuevas ideas de la relatividad en nuestra comprensión de la gravedad: primero puso la noción en la relatividad especial, que suplantó la cinemática de Galileo, y luego reveló la gravedad tal como la entendemos hoy a través de la teoría de la relatividad general. Guiados por estas teorías, descubriremos una estructura completamente nueva de la física y la comprensión de nuestro Universo en la que la gravedad se identifica fundamentalmente con el tejido mismo del espacio y el tiempo, entrelazado y unificado.
Hoy en día, ha pasado más de un siglo desde los avances de Einstein, y la relatividad general se mantiene más fuerte que nunca. La gravedad ha sido probada exhaustivamente, incluso en algunos de los entornos más extremos, y la evidencia concuerda indefectiblemente con las predicciones de Einstein. La fuerza misma dentro de la gravedad ha sido detectada gracias a las ondas gravitatorias. Al mismo tiempo, también hemos aprendido mucho más sobre la naturaleza cuántica de nuestro mundo a través de la física atómica, nuclear y de partículas, la química cuántica y los numerosos avances tecnológicos de la era electrónica y de la informática. Con estos avances, surgen constantemente nuevas ideas y teorías en nuestro esfuerzo por dar sentido al mundo en el que vivimos. Y, sin embargo, hasta la fecha, ninguna ha superado la teoría de la relatividad general de Einstein, a pesar de la obvia necesidad de una nueva física. Porque hay una cosa que, desde el principio, la propia relatividad general ha sido franca; hay un punto en el que la teoría debe fallar, en el que una nueva capa de física espera ser desvelada. De este fracaso surge la oportunidad de sondear y apreciar la naturaleza a un nivel más profundo.
A media que retomamos nuestro viaje, vemos cómo la gravedad, vista desde una perspectiva más moderna, también puede ser pensada como la manifestación de una partícula fundamental, el gravitón, al igual que el electromagnetismo es la manifestación del fotón, la partícula fundamental de la luz. De la misma manera que podemos “ver” la luz a medida que las ondas electromagnéticas se propagan a través del espacio y el tiempo, ahora podemos “escuchar” las ondas de gravedad a medida que perturban el tejido mismo del espacio tiempo.
Ahora hemos observado las ondas de gravedad a través de LIGO, y la realidad de la gravedad se ha vuelto incuestionable. Su detección ofrece una oportunidad sin precedentes para descifrar muchos de los misterios que aún esconde nuestro universo. ¿Cuál es el origen del Universo? ¿Cuáles son los componentes oscuros del universo que explican su estructura y evolución pero que no pueden ser detectados directamente con nuestros instrumentos? ¿Cuál es el destino del universo?
Eventualmente, nuestro viaje nos llevará al borde del mapa. Si bien la teoría de la relatividad general de Einstein ha proporcionado respuestas naturales y elegantes a algunas de las preguntas más desconcertantes sobre la naturaleza de la gravedad, también ha planteado varios enigmas con los que seguimos lidiando. ¿Cómo es que las contribuciones de partículas conocidas que entendemos tan bien en nuestros aceleradores de partículas subterráneos afectan al Universo de maneras que ni siquiera podemos comenzar a comprender?
A medida que intentamos reconciliar la evolución de nuestro universo con la naturaleza cuántica fundamental del mundo, nos veremos obligados a reconsiderar la gravedad a un nivel más profundo. ¿Qué pasará si, a grandes escalas cosmológicas, la gravedad se comportara de manera diferente a la predicha por la relatividad general? ¿Y si la gravedad, que durante mucho tiempo se asumió que no tiene masa, de hecho tiene masa? Esta idea es casi tan antigua como la propia relatividad general y ha sido explorada por algunos de los más grandes científicos de los últimos siglos. Hasta hace poco, todos los intentos de dar sentido a esta idea habían fracasado estrepitosamente. Sin embargo, lejos de ser el final, aquí es donde comenzará la parte más emocionante de nuestro viaje. Hoy, sin embargo, parece que pueden llevarnos a una forma completamente nueva de pensar sobre la gravedad. Y si bien es posible que estas nuevas teorías no proporcionen respuestas definitivas a todas nuestras preguntas, al explorar la gravedad tal como podría ser, incluso si no está en nuestra propia realidad, podemos llegar a apreciar la naturaleza por todo lo que tiene para ofrecer.
La gravedad es uno de los primeros fenómenos físicos de los que tenemos conocimiento, y poseemos un deseo casi universal de sondear sus límites. Cuando somos bebés, empujamos reiteradamente los juguetes, viéndolos caer. Cuando somos niños, saltamos incansablemente, viendo qué tan alto podemos elevarnos antes de ser arrastrados de regreso al piso. De adultos, lanzamos piedras a estanques y observamos las bellas ondas en la superficie. Su atracción constante es la fuente de inquietante curiosidad en nuestras vidas, pero en lugar de escondernos de ella, todos aprendemos a aceptarla.
A medida que caemos a través de la curvatura del espacio-tiempo tan libremente como caemos a través de nuestras vidas, pronto nos damos cuenta de que, aunque somos libres y rectos, nuestro viaje a través del espacio-tiempo está lejos de ser sencillo. Ciertamente, nuestro viaje no estaría completo sin una cuota de obstáculos y caídas. Abrazarlos y apreciar la belleza de la caída es esencial si queremos progresar en nuestra búsqueda interminable.
Todas las teorías de la gravedad desarrolladas hasta ahora han experimentado la virtud del fracaso. Atreverse a fracasar significa ser científico, apreciar cada caída no como un epílogo vergonzoso, sino más bien como una oportunidad para una comprensión más fundamental de la naturaleza. Piense en este viaje, entonces, como una celebración de los misterios de la gravedad y la racionalidad científica misma, con sus dudas y fracasos, sí, pero también con la increíble emoción del descubrimiento.
Esta no es solo nuestra búsqueda, ni la de nuestros académicos. No es un descubrimiento solo de Newton o Einstein. Es nuestra aventura compartida, tanto suya como la de los grandes científicos que allanaron el camino. Es un viaje que comenzó hace miles de años y que puede nunca terminar. En el camino, sin embargo, esperamos obtener conocimientos que enriquezcan la vida de las nuevas generaciones y civilizaciones futuras, permitiéndoles perseguir su propio destino, navegar entre nuevas capas de la realidad e interactuar con el tejido que abarca todo el universo.
6.2 Expresar el pensamiento
La verdad es que siempre me ha costado encontrar las palabras adecuadas para expresarme hacia los demás. Siempre he estado ansioso de poder comunicarme con un lenguaje más confiable y universal, para dar sentido al mundo de una manera que trascienda las palabras y los malentendidos. Sean cuales sean las circunstancias en las que nos encontremos, todos tenemos un instinto innato para dar sentido al mundo que nos rodea, para derivar leyes que expliquen nuestras observaciones y nos permitan hacer predicciones. Hacerlo nos permite comprender lo antes incomprensible, lo que explica, en parte, el éxito de nuestra especie. Reconocer estos patrones y la forma en que estructuran nuestro mundo ha pasado lentamente a modelar lo inexplicable y despertar el asombro por lo desconocido, introduciendo en la emoción del descubrimiento y en algunas de las relaciones más felices a medida que nos guían hacia el deseo de descubrir los misterios de nuestro universo.
Este momento desencadena lo que se convertirá en una fascinación de por vida con el tema. El autodidacta científico trabaja por una comprensión más profunda y universal de la naturaleza, investigando los principios fundamentales que gobiernan el cosmos. Aunque tales investigaciones científicas pueden parecer estar gobernadas únicamente por teoremas matemáticos y leyes físicas, es la pasión y la curiosidad que cada uno de nosotros posee lo que da lugar a nuestros descubrimientos más profundos.
Todos somos científicos, reconocemos patrones, desciframos sus significados y predecimos resultados de maneras que trascienden cualquier forma de comunicación. Tal vez por esto hemos tenido la suerte de reconocer la elegante universalidad de la gravedad y de la naturaleza en su conjunto. O tal vez sea la universalidad de la naturaleza la que nos ha dotado de la capacidad de ver el mundo de una manera tan simétrica y elegante. En cualquier caso, fue nuestro intento de dar sentido a los patrones de la naturaleza lo que reveló uno de los avances más significativos en nuestra comprensión de la realidad.
Desde la antigua astronomía maya nacida hace más de tres mil años hasta los descubrimientos más recientes del telescopio James Webb, casi todas las observaciones que hemos hecho, cada indicio que hemos recogido sobre la forma en que funciona la naturaleza, se han visto finamente a través de la luz. La luz ha servido como un mensajero valioso e infalible, compartiendo con nosotros los secretos de nuestro universo, develándonos nuevos paradigmas a través de nuestros propios ojos o a través de telescopios, observatorios u otros experimentos. Sin embargo, solo en los últimos siglos hemos comenzado a comprender mejor lo que realmente es la luz.
Después de una serie de avances, en 1861 el físico matemático escocés Clerk Maxwell resumió miles de años de sabiduría en un conjunto de ecuaciones notablemente simples. Las ecuaciones de Maxwell, como se les conoce, describen todo lo que sabíamos en ese momento sobre las fuerzas eléctricas y magnéticas, unificándolas en un campo electromagnético. Cuatro años más tarde, Maxwell dedujo de estas mismas ecuaciones que las perturbaciones en el campo electromagnético se comportan y viajan a la velocidad de la luz, llegando a la inevitable conclusión de que la luz que vemos no es otra cosa que ondas electromagnéticas, una conjetura hecha en 1846 por Michael Faraday. En muchos sentidos, la luz actúa como las olas del océano que se mueven a través de la superficie de nuestros mares o las ondas sonoras que se mueven en el aire. De hecho, la luz visible, las ondas de radio, las microondas, los rayos X, gamma y la radiación UV e IR son lo mismo: luz.
La única diferencia es la longitud de onda en la onda, la distancia entre los picos de oscilación. Al igual que la música se hace tocando notas de diferentes tonos (longitudes de onda), la luz produce diferentes colores con longitudes de onda más largas y más cortas. Por ejemplo, la luz roja tiene una longitud de onda más larga que la luz azul.
En términos de luz, se usa a veces para referirse exclusivamente a la parte visible del espectro: entre 400 y 700 nm aproximadamente (que están sintonizadas para nuestros ojos). Pero todos los tipos de ondas electromagnéticas, independientemente de su longitud de onda, son fundamentalmente iguales. Las ondas electromagnéticas podrían, en principio, tener longitudes de onda tan cortas como la longitud de Planck, 10^-35 m, es decir, diez mil millones de billones de billones de veces más cortas que la luz visible, mucho más allá del rango ultravioleta. En el otro extremo del espectro, muy lejos en el rango infrarrojo, se pueden detectar ondas de radio con longitudes de onda de hasta unos pocos cientos de miles de kilómetros. Si usáramos todo el Universo como nuestro detector, podríamos, en principio, detectar ondas electromagnéticas con longitudes de onda tan grandes como el universo observable, o aproximadamente un millón de billones de billones de kilómetros de largo. Para nuestros propósitos, no haremos distinción entre ondas en frecuencias visibles, solo nos referiremos al espectro luz independientemente de su frecuencia.
La luz, al igual que el sonido, toma algo de tiempo en desplazarse. En la teoría de Maxwell, las ondas de luz se mueven a una velocidad fija a través del espacio vacío. En el momento del trabajo de Maxwell, todas las ondas conocidas viajaban a través de un medio. El medio propuesto para la luz se llamó "éter luminífero", una sustancia que impregna todo el universo. Sin embargo, la búsqueda del éter requirió un alto grado de precisión experimental, y estos esfuerzos culminaron con el experimento de Michelson-Morley que negó la existencia del éter. La velocidad de la luz se estableció en 299,792,458 m/s. El hecho de que la luz siempre viaje a la misma velocidad a través del espacio vacío es una pieza bien publicitada de trivialidad científica, el tipo de cosas que la mayoría ha escuchado y dado por sentado. Pero, ¿qué significa exactamente? A primera vista, parece que la naturaleza ha sido amable con nosotros por una vez, porque esta constancia indica una cierta simplicidad. Sin embargo, para comprender completamente el significado y la peculiaridad de esta ley, imaginemos un escenario análogo pero más mundano en el que un automóvil viaja a una velocidad de 30 km/h. A priori, no parece que le costará demasiado esfuerzo a un motociclista ocasional acelerar hasta 30 km/h, permitiendo que el coche y la moto viajen uno al lado del otro. Desde el punto de vista del peatón, el coche y el motociclista parecerían entonces viajar a la misma velocidad. Desde el punto de vista del motociclista, el coche no se moverá ni más rápido ni más lento que él: la velocidad relativa del coche con respecto a la moto desaparecería. Al menos eso es lo que inferiríamos basándonos en nuestra comprensión instintiva de cómo deberían sumarse las velocidades, una idea que debería ser familiar de nuestro encuentro con la relatividad galileana. De hecho, precisamente esta intuición sobre la adición de velocidades estaba implícita en la discusión de Galileo sobre un observador encerrado en la cabina de un barco en movimiento junto con mariposas.
Siguiendo esta lógica, el consenso científico en la segunda mitad del siglo XIX sostenía que la velocidad de la luz a través del éter luminífero solo sería la misma para observadores específicos en reposo en relación con el éter. Cualquiera que se moviera a través del éter mediría una velocidad diferente. Por supuesto, la diferencia entre lo que vería un motociclista y su colega sentada es ridículamente pequeña en comparación con la velocidad real de la luz, unos ocho órdenes de magnitud más pequeña, y no es una diferencia que podría haberse medido utilizando la tecnología del siglo XIX. Por otro lado, si tenemos en cuenta el efecto de velocidades más rápidas, como el movimiento de la Tierra mientras órbita alrededor del Sol, deberíamos ser capaces de detectar efectos interesantes.
Mientras estás aquí, en estas letras, bajo tus pies está todo el planeta, girando alrededor del Sol a una velocidad respetable de 30 km/s en una dirección. Ya no hay mucha certeza en nuestras vidas ni sobre el destino de la Tierra, pero aún espero que, en medio año, el planeta esté al otro lado del Sol, en dirección opuesta. Esto significa que Galileo tenía razón: medir la velocidad de la luz en este momento debería arrojar un resultado ligeramente diferente al que observaríamos dentro de seis meses, o al que habríamos medido hace seis meses.
Dado que la Tierra gira continuamente sobre su eje mientras orbita alrededor del Sol, y que el propio Sol se desplaza por el espacio a 230 km/s en su órbita entorno al centro de nuestra galaxia, cabría esperar que nuestras mediciones de la velocidad de la luz variaran continuamente según la dirección en la que miremos. Esa sería la conclusión lógica si siguiéramos nuestros instintos galileanos sobre cómo se combinan las velocidades, con la suposición natural de que la luz se propaga a una velocidad fija dentro de un éter luminífero, como las olas del océano se mueven a través del agua.
A finales del siglo XIX, Albert A. Michelson, físico, y Edward W. Morley, químico, emprendieron un experimento para detectar el efecto del "viento luminífero". Este experimento requirió la construcción de uno de los primeros interferómetros, un ingenioso dispositivo con múltiples aplicaciones en el campo científico.
Para comprender cómo funciona esta configuración, imagina un avión volando de un lado a otro entre dos aeropuertos. En condiciones tranquilas, sin viento (y dejando de lado factores como el tráfico aéreo y la rotación de la Tierra), cada tramo tomaría el mismo tiempo. Ahora bien, ¿qué sucede cuando hay viento? Si el viento sopla perpendicular a la trayectoria del avión, este deberá ajustar su dirección para compensarlo, y el tiempo de vuelo será un poco mayor en ambos tramos. Sí, en cambio, el viento sopla en la misma dirección de ida y vuelta, el avión ganará tiempo con el viento de cola y perderá algo con el viento en contra.
Podríamos pensar que el tiempo ganado con el viento de cola compensaría exactamente el tiempo perdido con el viento en contra, pero no es así. Los vientos en contra, en realidad, agregan más tiempo del que los vientos de cola ahorran. Viajar de ida y vuelta en la misma dirección del viento causa retrasos mayores que hacerlo en una dirección ortogonal al viento.
El interferómetro de luz de Michelson y Morley utiliza esta información para detectar la presencia de “viento ligero” o éter luminífero. Imagina que en un aeropuerto hay una fuente de luz y, en otro, un espejo que refleja la luz. Si la luz se propagará a una velocidad fija dentro del éter luminífero, pero el éter estuviera en movimiento en relación con los aeropuertos, el éter actuaría sobre la luz exactamente de la misma manera que lo hace el viento sobre un avión. Sí la luz está alineada con el viento del éter, el tiempo de viaje de ida y vuelta será más largo que si el viento del éter es perpendicular a la trayectoria de la luz.
Para ser un poco más precisos, el interferómetro divide un haz de luz en dos. Cada haz se envía luego por dos brazos que están dispuestos en direcciones ortogonales. Al final de cada brazo hay un espejo que refleja el haz, devolviéndolo por el mismo camino, donde los dos haces se recombinan finalmente. Si ambos haces regresan a su punto de partida original al mismo tiempo, están en fase: los picos y los valles de su perfil de onda coincidirán con precisión y ambos haces se sumarán constructivamente. Pero si un rayo va a la zaga del otro, por ejemplo, porque el movimiento del éter ralentiza uno más que el otro, ya no se unirán perfectamente cuando se combinen. Estarán desincronizados o desfasados, y la amplitud de la señal resultante será más débil debido a la interferencia destructiva. Cualquier modulación en la señal es, por lo tanto, una indicación de que la velocidad de la luz está cambiando a lo largo de la dirección del viento del éter (o, equivalente, del movimiento de la Tierra a través del éter).
Los resultados del experimento de Michelson y Morley, publicados en noviembre de 1887, revelaron lo que ahora damos por sentado pero parecía imposible en ese momento: la velocidad de la luz en el vacío siempre se mide exactamente igual, independientemente de la velocidad a la que se mueva el observador. Michelson y Morley no encontraron absolutamente ninguna evidencia de cambio en la velocidad de la luz, a pesar del hecho innegable de que la Tierra y, por lo tanto, su experimento, se movían a través del espacio a diferentes velocidades y en diferentes direcciones durante todo el proceso.
6.3 Carga eléctrica
Si pudiéramos acercarnos a un átomo desde lejos, primero veríamos un enjambre de diminutas partículas cargadas eléctricamente. Estos son los electrones. El electrón parece ser una de las letras básicas del alfabeto de la naturaleza; si hay constituyentes más fundamentales al acecho dentro de un electrón, todavía no hemos encontrado ningún indicio de ello. Cada electrón es idéntico en forma, tamaño y masa, y lleva la misma pequeña cantidad de carga eléctrica negativa. Si bien las unidades de masa, longitud y tiempo son familiares (gramos, metros y segundos), la medida de carga eléctrica no lo es tanto. La unidad de carga es un “coulomb”, a menudo escrito con la letra mayúscula C.
La cantidad de carga en un solo electrón es insignificante. Se necesita más de seis billones de ellos para hacer un microcoulomb (una millonésima parte de un coulomb), aproximadamente la cantidad de carga que se podría sentir como un ligero choque estático. Sin embargo, incluso en una mota de polvo hay más átomos que estrellas en nuestra galaxia, y cada uno de esos átomos contiene varios electrones. Aunque la carga de un solo electrón es insignificante, el resultado de multiplicar innumerables veces una pequeña cantidad nos resulta sorprendente.
Por ejemplo, con cada respiración, inhalas alrededor de diez mil millones de billones de átomos de oxígeno, cada uno de los cuales contiene varios electrones cargados negativamente. En total, esto equivale a unos 15,000 coulombs de carga eléctrica, comparables a mil rayos de una tormenta eléctrica. Sin embargo, no eres consciente de ello. No se te ponen los pelos de punta; no emites chispas, ni experimentas una recarga eléctrica. Y si estás respirándolos constantemente, la ingesta corresponde a una corriente eléctrica de unos 3000 amperios, suficiente para matarte y ahorrarle a tus albaceas el costo de la cremación. Sin embargo, aquí estamos. Nada revela esta extraordinaria electricidad en lo profundo de nosotros. La razón sigue siendo un misterio mientras no introduzcamos las ideas de Maxwell. Abundan teorías que intentan explicarlo, y se han encontrado respuestas parciales. En el fondo, sin embargo, esta sigue siendo una de las preguntas sin respuesta más básicas de la ciencia fundamental.
Los electrones pueden parecer partículas fantasiosas que acechan dentro de los átomos y que de otro modo son irrelevantes, pero son como una puerta de entrada al mundo moderno. Los electrones son los portadores de carga eléctrica más fundamentales y de fácil acceso. Cuando cargas la batería de tu computadora, móvil o coche, estas baterías almacenan electrones para su uso posterior.
La corriente eléctrica es el flujo de electrones. Este flujo puede darse a través de chips de computadora, a lo largo del sistema nervioso central que mantiene la homeostasis del cuerpo a través de los cables aéreos o terceros rieles que alimentan trenes eléctricos, o en medio de cualquiera de las innumerables aplicaciones de nuestras industrias eléctricas modernas. Gran parte de la tecnología moderna es impulsada básicamente por electrones en movimiento. Una corriente de un amperio, o amp, se define como el flujo de un coulomb de carga en un segundo. Eso corresponde a 6.24 billones de billones de electrones que pasan por un solo punto en el latido de corazón. Estas enormes cantidades de electrones en movimiento pueden hacer que incluso pequeñas cantidades de corriente sean letales. Es tradicional centrarse en los miliamperios (una milésima parte de un amperio) cuando se evalúa el efecto de la corriente eléctrica en el cuerpo humano. Solo 10 miliamperios pueden ser suficientes para darte una descarga dolorosa, mientras que las corrientes entre 100 y 200 miliamperios son letales. Si tocas un cable que lleva más de 10 miliamperios de corriente, tus músculos se paralizan impidiéndote soltarter el cable que te está dando una descarga: el corazón sufre fibrilación ventricular y puede presentarse paro respiratorio conduciendo a la muerte. Alrededor de los 100 miliamperios, los músculos que controlan el corazón se ven afectados; sus ventrículos adquieren un espasmo incontrolable que conduce a la muerte. Sin embargo, por encima de 200 miliamperios, la descarga es letal sí atraviesa el pecho y se presentan deformaciones en el cuerpo consecuencia de las quemaduras.
La fisiología de la corriente eléctrica es un tema complejo, pero los dramas anteriores son suficientes para poner de relieve nuestra paradoja. Una corriente de 100 miliamperios es suficiente para causar la muerte, mientras que las corrientes más grandes fríen tejidos y órganos; sin embargo, inhalar 15000 coulombs en una sola respiración corresponde a recibir una corriente de 3000 amperios durante varios segundos, y lo hacemos todo el tiempo. Un solo rayo es suficiente para matar, y en efecto acabas de absorber los efectos de mil de ellos. ¿Cómo sobrevives? ¿Por qué no hay chispas volando mientras te conviertes en carbón? La razón es que en cada átomo, en el centro de este enjambre de cargas negativas, hay una masa varias miles de veces mayor, es decir, la de un átomo individual: un denso bulto de carga positiva: el núcleo atómico. La atracción eléctrica de las cargas opuestas atrapa a los electrones cargados negativamente en un enjambre remoto alrededor de este núcleo central compacto cargado positivamente.
A diferencia del electrón, que parece ser fundamental, el núcleo es una bestia compleja, un grupo de dos tipos de partículas que son casi gemelas. Una de ellas, el neutrón, es eléctricamente neutra y unas 2000 veces más masiva que un electrón. La otra, el protón, es casi idéntica al neutrón, excepto por un atributo esencial: el protón está cargado positivamente. El número de protones en un núcleo determina su carga eléctrica total y su posición en la tabla periódica de los elementos: por ejemplo, el helio, elemento número 2, contiene dos protones; el nitrógeno, el séptimo, contiene siete y así sucesivamente.
El núcleo cargado positivamente es la fuente de los campos eléctricos que originan la estructura de la materia. Lo más notable es el hecho de que la cantidad de carga positiva en un protón coincide exactamente con la cantidad de carga negativa en un electrón. Cualquier diferencia en las magnitudes de estas cargas equilibradas es demasiado pequeña para haber sido medida; son iguales en más de una parte en mil millones de billones. Lo más probable es que sean idénticas.
El equilibrio es tan perfecto que los 15000 coulombs de carga negativa en los electrones de esos innumerables átomos en una respiración de nuestros pulmones no nos producen ni un cosquilleo. La atracción de cargas opuestas y la repulsión de cargas semejantes gobiernan la construcción de las moléculas atómicas, de los cristales y de las formas de gran parte de lo que nos rodea, y no menos a nosotros mismos. Estas fuerzas competitivas, enraizadas en las fuentes binarias positivas y negativas de carga eléctrica, se cancelan con tanta precisión que a grandes escalas es la fuerza de la gravedad la que gobierna los movimientos de los planetas y galaxias de las estrellas. Sin embargo, si este equilibrio se estropeara incluso en una parte de billón de billones, las fuerzas eléctricas dominarían la gravedad y nuestro Universo no existiría.
Gracias a esta simetría eléctrica, la naturaleza ha adoptado un disfraz casi perfecto, donde la existencia de las grandes cantidades de carga eléctrica se esconde en lo más profundo de nosotros. Sin embargo, aparte de sus cargas eléctricas, los electrones y los protones son bastante diferentes. El portador del cuanto de carga negativa, el electrón, no tiene una extensión tangible y parece ser una de las letras básicas del alfabeto de la naturaleza. Por otro lado, el portador del cuanto positivo, el protón, tiene un tamaño medible. Descubierto hace poco más de un siglo, pronto quedó claro que se necesitarían diez mil protones colocados uno al lado del otro para igualar el tamaño de un átomo de hidrógeno. Por lo tanto, los protones son muy pequeños, pero sin embargo cada uno es al menos mil veces más grande que un electrón. Es más, se necesitarían casi 2000 electrones para contrarrestar un solo protón voluminoso. ¿No es extraño, entonces, que dos ladrillos tan disímiles sean tan perfectamente simétricos al reflejar la carga eléctrica del otro?
Evaluación 2__________
6.3.1 El enigma de la materia: de los protones y electrones a los quarks
Hasta 1968, el enigma se hizo más profundo. La masa del protón y su extensión espacial en relación con las del electrón fundamental sugirieron que el protón no está en la base de las estructuras de la naturaleza. La creciente sospecha de que el propio protón contiene un laberinto de estructuras internas se confirmó con el descubrimiento de que los protones son objetos complejos construidos a partir de piezas más pequeñas conocidas como quarks. Al igual que el electrón, que parece ser una partícula verdaderamente elemental, la más ligera de todas las partículas cargadas eléctricamente conocidas como leptones, así también los quarks parecen ser partículas fundamentales ligeras que componen el protón, el neutrón y una serie de otras partículas efímeras extrañas, encantadoras y, a veces, hermosas, conocidas colectivamente como hadrones.
Los leptones y los quarks parecen ser bastante similares en muchos aspectos. Por otra parte, los colectivos de quarks, los hadrones, son completamente diferentes a los leptones. Los hadrones sienten la fuerza nuclear fuerte, que es una razón por la que protones y neutrones se encuentran en el núcleo atómico, a pesar de que los protones se repelen entre sí. Los leptones se encuentran en los confines remotos del átomo, ajenos a la fuerza nuclear fuerte. Los ejemplos más comunes y estables de estas dos familias, el electrón y el protón, son, por lo tanto, fundamentalmente diferentes. Entonces, ¿por qué deberían trabajar juntos tan bien para formar el Universo que habitamos? ¿Cómo se relacionan eléctricamente los protones y los electrones tan perfectamente?
Hoy, 2500 años después del descubrimiento del magnetismo y la carga eléctrica, la razón de la neutralidad de la materia sigue siendo un enigma. Sí este equilibrio hubiera permanecido inmaculado dentro de cada átomo, habría sido muy difícil descubrir que el magnetismo y la carga eléctrica acechan dentro de todo, dando a la materia su forma. Sin embargo, la naturaleza ha revelado profundamente sus secretos, pero no los ha develado del todo. Una temperatura de unos pocos miles de grados es suficiente para romper la atracción eléctrica que une a los electrones alrededor del voluminoso núcleo atómico central. Incluso la temperatura ambiente es suficiente para liberar uno o dos electrones. La facilidad con la que los electrones pueden pasar de un átomo a otro es la fuente de la química, la biología y la vida.
Estas percepciones solo maduraron a finales del siglo XIX, pero la conciencia de la carga eléctrica y del magnetismo es tan antigua como la ciencia. Porque aunque las semillas atómicas de la materia a granel están eléctricamente equilibradas, las pistas sobre la arquitectura atómica y su profunda estructura eléctrica están en todas partes. Es cuestión de reconocerlas, y luego de interpretar lo que significan.
La fuerza dentro del magnetismo es una manifestación de la electricidad y viceversa. La electricidad y el magnetismo quedaron impresos en nuestro entorno desde el principio. Hace 5000 millones de años, cuando la Tierra recién nacida era un plasma caliente de corrientes eléctricas arremolinadas, estos flujos crearon campos magnéticos. A medida que el magma se enfrió para formar lo que hoy es la corteza exterior sólida del mundo, el magnetismo quedó atrapado en minerales que contienen hierro, como la magnetita.
Hoy en día, el núcleo líquido de la Tierra sigue siendo un frenesí de corrientes eléctricas, que generan un campo magnético. Este se extiende a la atmósfera y mucho más allá, invisible a nuestros sentidos. Pero al propagarse desde su fuente en el núcleo fundido hasta los cielos, primero penetra en la corteza terrestre. Aquí es donde deja una huella tangible, evidencia de que existe una fuerza más poderosa que la gravedad en acción dentro de la Tierra, cuya influencia se extiende muy lejos. En el Precámbrico más temprano, hace 4000 millones de años, a medida que la superficie se enfriaba, los elementos atómicos se acumulaban en los estratos. El más estable de ellos, el hierro, es hoy en día uno de los elementos más abundantes en la corteza. Las rocas ígneas formadas a partir de lava volcánica tienen la propiedad de que, en presencia de un campo magnético, sus átomos de hierro actúan como soldados en desfile, ya que ellos mismos se vuelven magnéticos. Esto se explota en demostraciones populares en las que el campo magnético de una barra magnética se puede hacer visible. Primero se esparcen pequeñas limaduras de hierro en la superficie de una mesa y luego se coloca cuidadosamente un imán entre ellas. Su campo magnético induce magnetismo en las limaduras de hierro, convirtiéndolas en miles de imanes en miniatura. Cada una de ellas se orienta debidamente en el campo magnético, revelando cómo la dirección de la fuerza magnética varía de un lugar a otro.
La barra magnética es un modelo simple que ilustra lo que sucede con la Tierra magnética misma. Los polos magnéticos norte y sur de la Tierra son análogos a los del imán de barra; el campo magnético de nuestro planeta se extiende muy lejos en el espacio. No hay limaduras de minerales de hierro en las colinas, acantilados o montañas de la Tierra. En algunos lugares, por casualidad, estos cúmulos magnéticos son bastante extensos, como en la isla de Elba y en el monte Ida en Asia Menor, donde grandes afloramientos conservan la huella magnética en rocas conocidas históricamente como piedra de imán, ahora llamada magnetita.
6.3.2 ¿Qué es carga eléctrica?
Hace muchos años, en mis días escolares, compré un libro del siglo XIX titulado La razón del porqué, en la ciencia. Compuesto de 1258 preguntas, todas relacionadas en 274 páginas, comenzaban con “¿Qué es la luz? ¿Qué es el calor?”. Luego vino la pregunta cuatro: ¿Qué es la electricidad? La electricidad es una propiedad de la fuerza que reside en toda la materia y que busca constantemente establecer un equilibrio. Todavía no se ha descubierto qué es realmente la electricidad. Hoy en día, una respuesta podría ser que la electricidad es el flujo de carga eléctrica, lo que a su vez plantea la pregunta: ¿qué es en última instancia la carga eléctrica?
Una respuesta es que realmente no lo sabemos. El adagio de San Mateo: "Por sus frutos los conoceréis", es quizás lo más que podemos decir actualmente. La carga eléctrica es un concepto inventado para racionalizar una amplia gama de lo que llamamos fenómenos eléctricos. Históricamente, el primer estudio sistemático de estos extraños efectos fue el descubrimiento de que una bola de vidrio que había sido frotada primero con seda se alejaba de la varilla con fuerza notablemente fuerte. El fenómeno era claramente real y por eso se inventó la idea de que la bola de vidrio había sido electrificada positivamente. Coloquialmente, se decía simplemente que la pelota había recibido una carga eléctrica positiva. La cantidad de carga podría determinarse midiendo la magnitud de la fuerza repulsiva observada.
Del mismo modo, se descubrió que si una vara de ébano se frota con piel de gato, la bola de vidrio se sentirá atraída por ella. El fenómeno de una bola de vidrio sometida a una nueva fuerza poderosa parecía ser el mismo que antes, excepto que la repulsión se había transformado en atracción. Este cambio en el comportamiento llevó a la idea de que la pelota había recibido una carga eléctrica negativa. El fenómeno inequívoco es que una bola de vidrio se puede poner en cualquiera de estos dos estados. Es entonces una cuestión de definición decir que ha recibido una cantidad de carga eléctrica positiva o negativa.
Todo pensamiento sobre asuntos eléctricos, en particular la carga eléctrica, comienza con estos dos fenómenos simples. La aplicación de carga eléctrica positiva o negativa a dos bolas de vidrio condujo al descubrimiento de que las bolas cargadas con el mismo signo de carga se repelían entre sí, mientras que cuando una estaba cargada positivamente y la otra negativamente, se atraían. Es ese fenómeno el que llevó a la regla de que las cargas iguales se repelen mientras que las cargas diferentes se atraen. ¿Por qué debería ser así? En última instancia, no lo sabemos. Esos son los fenómenos; la regla de atracción y repulsión eléctrica en términos de carga positiva y negativa es una observación empírica.
Cuanto más vigoroso es el roce de las varillas, mayor será la fuerza eléctrica entre las bolas de vidrio. Este descubrimiento encajaba naturalmente con la idea de que el roce producía la carga eléctrica y que un mayor vigor provocaba que se involucraran mayores cantidades de carga eléctrica, lo que conducía a una mayor fuerza eléctrica. Se encontró la regla de que la fuerza entre dos bolas era proporcional al producto de la carga en cada una y que se extinguía como el inverso del cuadrado de la distancia entre ellas. Eso fue establecido por primera vez por el francés Charles-Augustin de Coulomb en 1785. Es en honor a Coulomb que se nombra la unidad de carga eléctrica. Estos fenómenos se conocían mucho antes de que se establecieran las ideas de los átomos y los electrones físicos. Naturalmente, plantearon la cuestión de si había una cantidad mínima de carga eléctrica que se podía adjuntar en principio: conceptualmente, esto es lo que inspiró al físico estadounidense Robert Millikan en 1909.
En lugar de una bola de vidrio, Millikan utilizó el cuerpo esférico más pequeño posible que conservaría su masa para que, cuando se soltara, sintiera una fuerza gravitacional constante. En el célebre experimento de Millikan, el papel de la bola de vidrio fue desempeñado por gotas de aceite de aproximadamente 1 micra de diámetro que fueron expulsadas de un atomizador. Los efectos de fricción del soplado del spray cargaron las gotas. Millikan las mantuvo en una atmósfera estable sin corrientes de convección. En ausencia de un campo eléctrico, las gotas caían debido a la gravedad, pero al ser muy pequeñas y estar sujetas a la resistencia viscosa del aire, la velocidad era relativamente lenta, lo que permitía observarla y medirla.
Dos placas metálicas, una conectada al terminal positivo y la otra al terminal negativo de una batería, proporcionaban un campo eléctrico que podía encenderse o apagarse mediante un interruptor. El campo va directamente de una placa a otra, y la fuerza actúa sobre las partículas cargadas en la dirección del campo. Al cambiar el terminal positivo a negativo y el negativo a positivo, la dirección general del campo, y la dirección de la fuerza sobre una gota, también cambiará. La fuerza eléctrica acelera o ralentiza las gotas dependiendo de la dirección del campo eléctrico y la cantidad de carga en la gota. Al apagar el campo, las gotas caerían hacia la placa inferior y se perderían, pero al encender el campo, algunas gotas que aún no habían llegado al fondo se detendrían en vuelo o incluso comenzarían a derivar hacia arriba, hacia la placa con carga opuesta.
Al repetir esto varias veces, Millikan fue capaz de eliminar casi todas las gotas hasta que pudo concentrarse en una sola, para la cual las fuerzas gravitacionales y eléctricas se equilibraron lo suficiente como para que la gota pudiera mantenerse en suspensión. La ingeniosa idea consistía ahora en alterar la cantidad de carga de la gota iluminada con luz ultravioleta o con la radiactividad del radio. La gota se movería ahora bajo la acción de la fuerza eléctrica con una velocidad proporcional a la cantidad de carga. Descubrió que a medida que cambiaba la cantidad de carga, la velocidad de la caída sería siempre dos, tres o alguna otra cantidad entera multiplicada por un mínimo, pero nunca una fracción. Las velocidades se expresan en cantidades discretas, o cuántos, porque la carga eléctrica está cuantizada y se presenta en cantidades discretas con una magnitud mínima fundamental.
Millikan ganó el Premio Nobel en 1923 por medir la magnitud fundamental de la carga eléctrica, y en su discurso ante la Fundación Nobel en 1924 resumió la profunda importancia del experimento. Dijo que uno ha visto literalmente el “electrón”, refiriéndose al cuanto básico de la carga eléctrica, midiendo en términos de velocidad la más pequeña de las fuerzas eléctricas que un campo eléctrico dado ejerce sobre la bola de vidrio con la que está trabajando y con la ayuda de cuyos movimientos define la carga eléctrica misma. Además, algo que hemos elegido llamar carga eléctrica puede ser colocado o eliminado de nuestra bola de vidrio solo en cantidades que causen que la fuerza que actúa sobre ella suba por múltiplos enteros de la fuerza observada más pequeña[2].
Midiendo miles de gotas, hechas de diferentes sustancias de diversos tamaños, y haciéndolas pasar a través de gases cuya viscosidad y presión eran conocidas, se demostró que era posible medir la carga eléctrica no en términos de la velocidad que tarda en caer una gota de aceite (por su carga eléctrica), sino en unidades electrostáticas absolutas: culombios, en el lenguaje moderno. Millikan respondió a nuestra pregunta ¿qué es la carga eléctrica? De la siguiente manera: los electrones, tanto de la variedad positiva como de la negativa, son simplemente centros observados de fuerza eléctrica.
Aquí, por electrones se refiere a la unidad fundamental de la carga eléctrica. Considera que lo negativo y lo positivo son complementarios y, por lo tanto, iguales en magnitud. Para él, la misteriosa asimetría se produce en la forma en que las dos se manifiestan por las partículas fundamentales (y recordemos que en 1924, cuando dio este discurso, las partículas llamadas “electrón” y “protón” eran las únicas partículas fundamentales cargadas eléctricamente que se conocían). Millikan le dijo a la audiencia en la ceremonia del Nobel: En general, se pueden ignorar las dimensiones de los electrones, es decir, ambos pueden, a efectos prácticos, considerarse como cargas puntuales, aunque, como es bien sabido, el protón tiene una masa 1.845 veces mayor que la del electrón. Nadie sabe por qué es así. Es otro hecho experimental.
La interacción entre “electrón”, que significa unidad de carga eléctrica, y también la partícula que lleva la forma negativa de esa carga, puede ser confusa para los oídos modernos. Sin embargo, es evidente que reconoce el rompecabezas básico al que nos enfrentamos. Millikan estaba alerta a una posible advertencia a su descubrimiento, mientras reflexionaba:
¿Encontraremos alguna vez que las partículas positivas o negativas son divisibles? No está claro si por “divisible” Millikan se refiere a la posibilidad de que el electrón y el protón físicos estén formados por constituyentes más pequeños, o a que los cuantos iguales de carga eléctrica negativa y positiva sean múltiplos de algún cuanto aún más pequeño. En cuanto a la respuesta, concluyó: “si el electrón se subdivide alguna vez, probablemente será porque el hombre, con nuevos agentes tan diferentes de los rayos X y la radiactividad, como estos son diferentes de las fuerzas químicas, abrán campo en el que los electrones pueden dividirse sin perder ninguna de las propiedades unitarias que ahora se ha observado que poseen en las relaciones en las que los hemos estudiado hasta ahora”. En el centenario de la conjetura de Millikan, ¿cuánto ha sido respondida esta cuestión?
La cantidad más pequeña medida por Millikan corresponde a la cantidad de carga eléctrica transportada por un solo electrón. A partir de aquí, “electrón” se refiere a la partícula con ese nombre. Esta carga es de aproximadamente 1.6×10^−19 culombios.
El número de Avogadro representa la cantidad de partículas (átomos, moléculas, iones, etc.) que hay en un mol de una sustancia. Imagina que tienes una caja llena de pelotitas de colores, y quieres saber cuántas hay sin contarlas una por una. Algunas veces, los científicos necesitan saber cuántas partículas (como átomos o moléculas) están en un espacio pequeño. ¡Pero esos son mucho más pequeños que pelotitas y son imposibles de contar a simple vista!
Aquí es donde el número de Avogadro nos ayuda. El número de Avogadro es una cantidad mágica de partículas. Es como una "supercaja" que siempre tiene 6 seguido de 23 ceros (o sea, 600,000,000,000,000,000,000,000) partículas. Esa cantidad es tan grande que no la usamos para contar pelotitas, sino para contar átomos o moléculas. Es una manera de decir: "Si tienes esta cantidad enorme de partículas, tienes 1 mol".
Los científicos ya sabían que la materia estaba hecha de partículas pequeñísimas, como átomos y moléculas. Querían saber cuántas había en una cantidad determinada, pero como son invisibles a simple vista, parecía imposible contarlas. El científico austriaco Johann Josef Loschmidt hizo un experimento con gases. Sabía que si medía el tamaño y la distancia de las moléculas en un gas, podría encontrar una idea de cuántas moléculas había en una cantidad pequeña de gas. Usó algunos cálculos basados en las leyes de los gases (cómo los gases se expanden y contraen con la temperatura y presión) para hacer su primera estimación. Años después, el científico Robert Millikan midió la carga de un solo electrón en un famoso experimento conocido como el experimento de la "gota de aceite". Con esa información y algunos datos adicionales, los científicos pudieron hacer una estimación aún más precisa del número de Avogadro. Finalmente, combinaron estos y otros experimentos y cálculos, hasta llegar al número que conocemos hoy, aproximadamente 6.022×10^23 partículas por mol.
Imagina que tienes una cucharada de azúcar y quieres saber cuántas moléculas de azúcar hay en esa cucharada. El número de Avogadro nos permitirá hacer eso.
- Saber cuánto pesa una molécula de azúcar: primero, necesitamos la "masa molar" del azúcar (C12H22O11). Esto es el peso de un mol de moléculas de azúcar y es aproximadamente 342 gramos. Esto significa que 342 gramos de azúcar contienen el número de Avogadro de moléculas de azúcar (6.022 ×10²³ moléculas).Medir el azúcar en gramos: supongamos que la cucharada de azúcar pesa 10 gramos. Usar una regla de tres: Ahora, sabemos que: 342 gramos de azúcar tienen 6.022 × 10²³ moléculas.
- Entonces, 10 gramos de azúcar tendrán X moléculas
- Para encontrar X, hacemos una regla de tres:
X=10 gramos ×6.022×10^23 moléculas / 342 gramos
X=342gramos10gramos×6.022×10^23mole´culas
- Resolviendo esto, obtendrás el número aproximado de moléculas en esos 10 gramos de azúcar. El número de Avogadro hace posible este cálculo porque convierte la cantidad de materia que vemos y tocamos (gramos) a una cantidad de partículas invisibles (moléculas). En resumen, el número de Avogadro nos permite calcular cuántas partículas hay en cualquier cantidad de sustancia siempre que sepamos su masa molar.
Volúmenes iguales de gases, a la misma temperatura y presión, contienen el mismo número de moléculas. Esto fue enunciado por primera vez por el italiano Amedeo Avogadro a principios del siglo XIX. Calculó lo que hoy conocemos como el número de Avogadro, que es la cantidad de moléculas de un gas necesarias para que su peso sea igual al peso molecular, medido en gramos, de una cantidad conocida como “mol”. Por ejemplo, para un gas con moléculas de hidrógeno, cuya fórmula química es H2, el peso sería de 2 gramos; para el oxígeno, O2, serían 32 gramos, y para el vapor de agua, H2O, serían 18 gramos. El número de Avogadro es enorme: 6×10^23 . A temperatura ambiente y presión atmosférica normal, estos pesos de los distintos gases ocuparían un volumen de 22.4 litros cada uno. Una bocanada de aire tiene un volumen de aproximadamente 0.5 litros, que es alrededor de una quincuagésima parte de los 22.4 litros necesarios para alcanzar el número de Avogadro. Por lo tanto, un aliento de medio litro contiene aproximadamente una quincuagésima parte de 6×10^23, lo que corresponde a 1.2×10^22 átomos.
En 2019, la Conferencia General de Pesas y Medidas redefinió el mol de manera exacta. Desde entonces, el número de Avogadro es exactamente 6.02214076×10^23. Esta decisión se tomó para mejorar la consistencia de las unidades del Sistema Internacional (SI) y hacer que el mol sea una unidad de medida tan exacta y confiable como el metro o el kilogramo.
El aire es predominantemente nitrógeno y oxigeno en una proporción de aproximadamente 4:1. Cada átomo de nitrógeno contiene siete electrones, mientras que el oxígeno tiene ocho. Por lo tanto, una mezcla de medio litro de oxigeno y nitrógeno contiene aproximadamente 9x10^22 electrones. Aunque cada electrón solo lleva una cantidad insignificante de carga, unos 1.6×10^−19 culombios, es el gran número de ellos el que acumula el total de 15000 culombios. Un rayo promedio transfiere alrededor de 15 culombios. Entonces, la cantidad de carga negativa que inhaló hace un momento es suficiente para encender 1000 rayos.
Aunque el equilibrio perfecto de positivo y negativo dentro de los átomos ha permitido a la naturaleza enmascarar la carga eléctrica, incluso la temperatura ambiente es suficiente para revelar la presencia de electrones fugaces en los confines exteriores del átomo. La fuente de los intensos campos eléctricos que llenan el espacio atómico interior es el enorme núcleo atómico en su centro. A temperatura ambiente, el núcleo está profundamente congelado en la arquitectura atómica; solo a temperaturas extremas, como en el corazón del Sol a decenas de millones de grados, el núcleo se convierte en un actor principal.
De haber sido toda la historia, la existencia del núcleo podría haber permanecido desconocida, junto con su papel como motor de las estrellas. Sin embargo, gracias a la incertidumbre cuántica, incluso a temperatura ambiente, la evidencia del núcleo oculto puede filtrarse, literalmente en forma de radiactividad. Al igual que los pequeños avances permiten a los criptógrafos descifrar lo que parecen ser códigos impenetrables de mensajes previamente indescifrables, el descubrimiento de la radiactividad dio tanto la pista de un código atómico como la clave para interpretarlo.
El primer indicio de radiactividad fue tan insignificante que casi se pasó por alto. El descubrimiento fortuito, en 1896, de que los minerales que contienen uranio emiten una misteriosa radiación que puede empañar las placas fotográficas demostró que hay una fuente de energía en las profundidades de los átomos. El descubrimiento posterior del radio, un elemento altamente radiactivo, demostró que los átomos pueden emitir energía aparentemente sin ningún estímulo previo, y durante miles de años. Dos formas de radiactividad identificadas en la primera década del siglo XX se denominaron radiación alfa y beta. Las partículas que componen la radiación beta son electrones. El descubrimiento más significativo, y clave para desentrañar toda la arquitectura atómica, fue que las partículas de radiación alfa están cargadas positivamente y tienen aproximadamente cuatro veces la masa de un átomo de hidrógeno.
Un paso clave fue poder observar directamente la radiación atómica. La radiación alfa consiste en partículas que, al golpear una pantalla recubierta de sulfuro de zinc, emiten un destello de luz. Este fenómeno se denomina “centelleo” y es una forma conveniente de observar la presencia de partículas alfa.
Una fuente de partículas alfa emite partículas alfas en todas las direcciones. Para producir un rayo agudo de partículas, la fuente se alojaba dentro de un absorbente que contenía una abertura estrecha. Cualquier partícula alfa que escapaba a través de esta abertura formaba un haz delgado como un lápiz y, cuando golpeaba la pantalla, se podía ver un punto de luz brillante y nítido. Esto demostró que, en ausencia de fuerzas o materiales intervinientes, las partículas alfa viajan en línea recta de acuerdo con las leyes del movimiento. Sin embargo, cuando se colocó un poderoso imán, el lugar en la pantalla se movió. Esto demostró que un campo magnético afecta su movimiento. Un campo magnético desvía las cargas negativa y positiva en direcciones opuestas; la desviación del punto de luz en este caso mostró que las partículas alfa llevan carga eléctrica positiva. En relación con el electrón, una partícula alfa tiene el doble de carga eléctrica (de signo opuesto) y aproximadamente 7300 veces su masa.
Los campos magnéticos desvían las partículas alfa que se mueven rápidamente; ¿cuál es el efecto de poner láminas delgadas de material en su camino? Donde el haz había dejado previamente un pequeño punto brillante en la pantalla, el punto se volvió borroso cuando se interpuso una delgada capa de mica. El hecho de que hubiera algún centelleo demostraba que las partículas alfa podían penetrar en la mica, pero la borrosidad implicaba que, al pasar a través de la lámina, se desviaban ligeramente en todas las direcciones.
Que esto sucediera no fue inesperado, ya que dentro de la mica, las fuerzas eléctricas mantienen unidos sus átomos y estas mismas fuerzas afectarían el movimiento de las partículas alfa cargadas eléctricamente. La sorpresa, sin embargo, fue que el fenómeno fuera tan apreciable. Las mediciones de las partículas alfa habían demostrado que viajaban a aproximadamente a una vigésima parte de la velocidad de la luz, lo que les daba una enorme energía para su tamaño. Esta velocidad corresponde a unos 15,000 kilómetros por segundo, lo que en medio minuto podría llevarlas a la Luna. La aritmética simple muestra que, moviéndose a esa velocidad, podrían penetrar una delgada lámina de mica en menos de un nanosegundo. El hecho de que un paso tan volátil pudiera verse afectado demostró que los campos eléctricos y magnéticos dentro de la mica deben ser enormes, ciertamente mucho mayores que cualquier cosa conocida por la tecnología en el mundo en general.
En 1911, Ernest Rutherford tuvo la intuición de que estos intensos campos podían ser los que mantenían los electrones en los átomos. Efectivamente, Rutherford había encontrado evidencia directa de los campos que dan origen a las estructuras de los átomos y de los materiales en general. Para investigar esto más a fondo, disparó partículas alfa contra metales pesados, como las delgadas láminas de pan de oro, utilizando el método de centelleo para detectar lo sucedido. Para su gran sorpresa, descubrió que las partículas alfa a veces se desviaban muy violentamente; en ocasiones, cambiaban de dirección de forma abrupta. Interpretó esto como evidencia de que la carga positiva dentro de los átomos, que está desviando las partículas alfa, se concentra en un núcleo central compacto y masivo: el núcleo atómico. Además, postuló que este centro positivo es la fuente de los campos eléctricos que mantienen a los electrones cargados negativamente a distancia, como satélites que rodean un centro de atracción.
La conclusión del experimento, que el núcleo está rodeado de electrones sostenidos por fuerzas eléctricas, ha sobrevivido durante más de un siglo y puede considerarse una verdad profunda de la naturaleza. La imagen del átomo como un análogo eléctrico de un sistema solar en miniatura, con electrones cargados negativamente girando alrededor de un núcleo central compacto, fue muy popular y aún es sostenida por muchos. Es una imagen útil, y haré uso de ella, pero viene acompañada de una importante advertencia: es errónea o, al menos, incompleta. Las leyes de Newton y Einstein, aplicables al movimiento de objetos macroscópicos, no son fundamentales, sino que han surgido de leyes más profundas que las extrañas propiedades de los átomos revelan.
Ondas electrónicas. Es tentador imaginar un átomo como un sistema solar en miniatura, donde el núcleo desempeña el papel del Sol y los electrones remotos son como los planetas. Mientras que la fuerza de gravedad controla el movimiento de los planetas, los átomos se mantienen unidos por la fuerza eléctrica de atracción entre cargas opuestas. Hasta aquí, todo bien; sin embargo, la analogía puede ser engañosa si se lleva demasiado lejos. Los átomos no podrían sobrevivir ni un momento si obedecieran las leyes de la mecánica de Newton. Los átomos son extremadamente pequeños, y la fuerza eléctrica es mucho más poderosa que la gravedad. Si los electrones de los átomos giraran alrededor del núcleo y obedecieran las leyes de Newton, irradiarían energía electromagnética y entrarían en espiral hacia el núcleo en una fracción de segundo. Un átomo, una vez formado, se autodestruiría en un destello de luz casi de inmediato. La materia, incluyéndonos, no existiría. El hecho de que existamos, al igual que los átomos, implica que algo más allá de la mecánica clásica de Newton está en juego. La respuesta es: la mecánica cuántica.
La mecánica cuántica es necesaria para comprender la estabilidad de los átomos y la materia. Entre sus muchas implicaciones, la mecánica cuántica dicta que un electrón no puede ir a donde le plazca en un átomo. Sus opciones están limitadas, como alguien en una escalera que solo puede pisar peldaños individuales. Los electrones en los átomos siguen una regularidad fundamental: cada peldaño de su escalera figurativa corresponde a un estado en el que el electrón tiene una cantidad única de energía. Cuando un electrón cae de un peldaño de nivel alto a uno de nivel inferior, la diferencia de energía se irradia como luz. Son los niveles discretos de los peldaños de energía de los electrones dentro de los átomos los que generan las energías específicas de los fotones de luz emitidos. Cuando estos fotones corresponden a luz en el rango óptico, sus diferentes energías se muestran como colores. El espectro resultante de líneas coloreadas individuales es como un código de barras fundamental que identifica la fuente atómica.
Pero, ¿cómo restringe la mecánica cuántica la libertad de un electrón atómico? En la teoría cuántica, las partículas tienen un carácter ondulatorio. La idea de que una onda electromagnética puede actuar como si estuviera compuesta de partículas, llamadas “fotones”, se había debatido desde que Isaac Newton propuso la idea en el siglo XVII; pero ahora la teoría cuántica le estaba dando una justificación fundamental. Y no solo fotones: la teoría cuántica implica que cualquier partícula —un electrón, por ejemplo— tiene un carácter ondulatorio. El ejemplo más directo es el del electrón dentro de un átomo. La regla de oro de la física cuántica es que, cuanto mayor sea el momento o la energía de una partícula, menor será la longitud de su onda asociada. Imaginemos las ondas de los electrones en los átomos como si fueran las oscilaciones en un trozo de cuerda. Ata un extremo de la cuerda a algún soporte y sacude el extremo opuesto. Cuanto más rápido lo hagas, más energía impartirás y más corta será la longitud de onda. Así, esta es una analogía visual para el comportamiento ondulatorio del electrón en el mundo cuántico.
Ahora imagina ese electrón en un circuito alrededor del núcleo. En nuestro modelo, la cuerda debe completarse en un círculo, como un lazo. Para lograr esto, los dos extremos de la cuerda deben encontrarse en el mismo punto de oscilación; de lo contrario, no coincidirán. Al enrollarse en un círculo, para que una onda encaje perfectamente en la circunferencia, el número de longitudes de onda en el circuito debe ser un número entero. Imagina este círculo como la esfera de un reloj: si la onda alcanza su punto máximo a las 12 en punto y luego desciende a las 6 en punto, el siguiente pico se producirá perfectamente a las 12. La onda encaja en el círculo. Sin embargo, si un pico ocurriera en las 10 en punto, quedaría fuera de sincronía con el ritmo de la onda, es decir, estaría desfasado, en la jerga de la física. La onda no encajará.
El resultado es que las únicas trayectorias posibles para que un electrón sobreviva en un átomo serán aquellas en las que un número entero de longitudes de onda encaje en un solo circuito. Una sola longitud de onda corresponde a que el electrón esté en el peldaño más bajo de la escalera; dos longitudes de onda lo situarán en el segundo peldaño, tres en el tercero, y así sucesivamente. Cuando un electrón cae de un peldaño de alta energía a uno más bajo, la diferencia de energía se irradia como luz, en perfecto acuerdo con el espectro observado en átomos simples.
Este es un hermoso ejemplo de la naturaleza ondulatoria de los electrones, al menos cuando están dentro de los átomos. La naturaleza ondulatoria de los electrones libres se observa cuando pasan a través de rendijas muy estrechas en una pantalla opaca. Los haces de electrones que pasan a través de tales rendijas se difractan de manera muy similar a las ondas de luz. Que los electrones y, de hecho, todas las partículas fundamentales adquieren características ondulatorias está fuera de discusión, pero precisamente a qué se refieren estas ondas ha sido un tema de debate desde el nacimiento de la mecánica cuántica. No tenemos nada que añadir aquí, aparte de decir que el concepto de ondas es fundamental para la teoría cuántica y funciona empíricamente.
Evaluación 3__________
6.3.3 El código nuclear
Cuando un átomo está en un campo eléctrico o magnético, sus constituyentes cargados eléctricamente responderán a la fuerza electromagnética. Las leyes del movimiento de Newton nos dicen que la cantidad de aceleración de un cuerpo, es decir, el cambio en su movimiento, es proporcional a la cantidad de fuerza e inversamente proporcional a la masa del objeto. Estas reglas también son válidas en la mecánica cuántica. El núcleo de un átomo transporta más del 99.5% de su masa. En otras palabras, menos de una parte en dos mil de la masa de un átomo proviene de los electrones que giran alrededor del núcleo central. Como resultado, cuando las fuerzas eléctricas o magnéticas actúan sobre un átomo, sus electrones responden drásticamente, mientras que el núcleo central permanece relativamente inalterado. Mientras un átomo no experimente alguna fuerza extrema que rompa el núcleo, será el núcleo el que defina la ubicación del átomo. A su vez, es este núcleo estático cuyo campo eléctrico atrapa a los electrones, y la mecánica cuántica la que determina sus energías.
Cuando se descubrió el núcleo atómico, todo lo que se sabía era que estaba cargado positivamente y era muy masivo. Poco a poco se hizo evidente que el núcleo tiene una estructura compleja propia. La primera idea fue que la carga positiva es transportada por partículas llamadas protones y que cada protón tiene la misma cantidad de carga eléctrica que un electrón, pero positiva en lugar de negativa. En términos de masa, un protón es unas 1836 veces más masivo que un electrón, y es sorprendente que dos partículas tan diferentes entre sí tengan cantidades de carga eléctrica tan exactamente ajustadas. Uno podría haber esperado que cualquier cantidad arbitraria de carga hubiera podido ser asignada al protón. El hecho de que esta partícula relativamente voluminosa tenga la misma magnitud de carga, aunque de signo opuesto a la del electrón fugaz, sugiere que la carga eléctrica está cuantizada; en otras palabras, que es una propiedad que se adhiere a las partículas en cantidades enteras discretas. Por qué debería ser así y qué determina su cantidad son enigmas de la física moderna.
Cuantos más protones se reúnan en el núcleo, mayor será su carga eléctrica total. Es la cantidad de carga en el núcleo lo que determina el número de electrones que pueden rodearlo para formar un átomo neutro. Estos electrones determinan las propiedades químicas del elemento atómico resultante. Básicamente, es el número de protones en el núcleo lo que determina tanto su carga como el lugar del átomo resultante en la tabla periódica de los elementos. Por ejemplo, el hidrógeno, el elemento atómico más ligero, tiene un electrón alrededor de un núcleo que contiene un solo protón; el siguiente, el helio, tiene dos, y así sucesivamente hasta el elemento natural más pesado, el uranio, cuyos núcleos atómicos contienen cada uno 92 protones rodeados por 92 electrones. En todos los casos, el equilibrio eléctrico entre el núcleo y los electrones es perfecto, lo que permite que los átomos sean eléctricamente neutros en general, al menos con la mejor precisión que podamos medir.
El Sol posee el 99.8% de la masa total del Sistema Solar, por lo que permanece inalterado mientras los planetas orbitan a su alrededor. El caso del átomo es aún más extremo. La masa de un núcleo atómico con respecto a los electrones del átomo es de cinco a diez veces mayor que la del Sol con respecto a los planetas. Por lo tanto, el centro de masa de un átomo se encuentra dentro del núcleo. El núcleo es, en efecto, como un bulto estático de carga positiva que extiende sus tentáculos eléctricos de manera uniforme en el entorno, atrapando a los ligeros electrones mercuriales.
El contrapeso perfecto entre el electrón negativo y el protón positivo significa que los átomos, incluso los de los elementos pesados, pueden existir con sus efectos eléctricos completamente neutralizados. Sin embargo, es relativamente fácil eliminar uno o más electrones de un átomo, lo que crea un ion cargado positivamente. Por el contrario, la unión de electrones a los átomos genera iones negativos. Los efectos de largo alcance, en los que los campos eléctricos se extienden más allá de un solo átomo o en los que los iones adyacentes de carga opuesta pueden atraparse mutuamente, permiten que varios átomos se unan para formar moléculas. Por lo tanto, aunque un átomo individual puede estar completamente descargado eléctricamente, dos o más átomos que se acercan estrechamente entre sí pueden perturbar su actividad eléctrica interna y quedar atrapados en combinaciones complejas.
El lugar de un elemento dado en la tabla periódica se conoce como su número atómico, que, recordemos, es el mismo que el número de protones en su núcleo. Sin embargo, las mediciones de las masas relativas de los elementos atómicos muestran que estas masas no coinciden con el número atómico del elemento respectivo. Por ejemplo, el helio, con número atómico 2 y cuyo núcleo contiene dos protones, tiene aproximadamente cuatro veces la masa de un átomo de hidrógeno con solo un protón. Todos los demás elementos muestran masas atómicas mayores de lo que uno esperaría si los núcleos contuvieran únicamente protones. La razón es que, además de los protones cargados positivamente, los núcleos atómicos pueden contener neutrones, partículas eléctricamente neutras cuya masa es casi igual a la del protón. La adición de neutrones a un núcleo aumenta la masa nuclear, pero deja su carga y, por lo tanto, la química del átomo, sin cambios.
Dos átomos cuyos núcleos contengan el mismo número de protones tendrán las mismas propiedades químicas, pero diferentes propiedades en lo que respecta a la radiactividad. Dos núcleos de un mismo elemento con diferente número de neutrones se conocen como “isótopos”, palabra que proviene del griego y significa “mismo lugar” (en la tabla periódica de los elementos). Los diferentes isótopos de un elemento poseen distintos niveles de estabilidad. Los protones se repelen mutuamente debido a sus cargas eléctricas, lo cual incrementa la energía electrostática general en el núcleo, aumentando la inestabilidad. Los neutrones y los protones, en cambio, se atraen entre sí mediante la “fuerza fuerte” cuando están en estrecho contacto. Dado que los neutrones no tienen carga eléctrica, agregar neutrones a un núcleo contribuye a aumentar la atracción sin introducir repulsión adicional, lo cual tiende a estabilizar el núcleo. Por esta razón, los isótopos estables de los elementos suelen tener más neutrones que protones en el núcleo, y esta tendencia se acentúa conforme se avanza en la tabla periódica. Mientras que los elementos ligeros, como el helio, el oxígeno y el nitrógeno, pueden mantener un número igual de neutrones y protones en sus núcleos, los 26 protones del hierro están estabilizados por 30 neutrones; en el extremo de la tabla periódica, los 92 protones del uranio requieren más de 140 neutrones para alcanzar la estabilidad.
Si esta fuera toda la historia, uno podría esperar que los núcleos prefirieran estar formados únicamente por neutrones, sin protones. Sin embargo, esto no ocurre debido a una sutil pero importante diferencia: el neutrón y el protón, aunque ambos son muy masivos en comparación con el electrón, no son idénticos en masa. Un neutrón aislado es ligeramente más pesado que un protón. Por la equivalencia entre masa y energía descrita por Einstein (E=mc2), esto significa que un neutrón en reposo tiene una mayor energía asociada a su masa que un protón.
Cada neutrón adicional que se incorpora a un sistema nuclear incrementa la energía total del conjunto. Si se añaden demasiados neutrones, el sistema acumulará más energía de la que puede mantenerse en una configuración estable.
La naturaleza busca la estabilidad minimizando la energía en configuraciones inestables. Sin embargo, la energía no se destruye, sino que se redistribuye: la naturaleza transforma una configuración inestable en una más estable, liberando la diferencia de energía en el proceso. Un ejemplo clásico de este fenómeno es la radiactividad beta, que ocurre cuando un neutrón se transforma en un protón. En este caso, la diferencia de energía se emite en forma de un electrón y una partícula casi sin masa, pero igualmente fascinante, llamada neutrino.
Neutrón. Es una partícula subatómica que forma parte del núcleo atómico junto con los protones. Los neutrones son componentes fundamentales de los átomos, excepto en el caso del hidrógeno-1 (que tiene un solo protón en su núcleo). Interactúa fuertemente con otras partículas nucleares (fuerza nuclear fuerte) y también por la fuerza débil (en su desintegración). Es parte del modelo estándar de partículas como un barión, compuesto de tres quarks: (up-up-down). Proporciona estabilidad al núcleo atómico (al contrarrestar la repulsión entre los protones cargados positivamente). Participa en reacciones nucleares, como la fisión y la fusión. Es inestable fuera del núcleo atómico, desintegrándose en un protón, un electrón y un antineutrino en aproximadamente 10 minutos.
Neutrino. Es una partícula elemental, extremadamente ligera, perteneciente al grupo de los leptones. Los neutrinos no forman parte de los átomos y están asociados a procesos como la desintegración radiactiva y las reacciones nucleares. Interactúa únicamente mediante la fuerza nuclear débil y la gravedad, lo que lo hace extremadamente difícil de detectar. Pueden atravesar grandes cantidades de materia sin ser absorbidos o desviados. Es una partícula fundamental en el modelo estándar y pertenece a los leptones, sin subestructura conocida. Es crucial en procesos como la desintegración beta y las reacciones nucleares en las estrellas. Transporta energía y momento sin interactuar fácilmente con la materia, lo que lo hace muy difícil de detectar. Existen tres tipos o "sabores" de neutrinos: electrónico, muónico y taónico.
La desintegración beta es un tipo de desintegración radiactiva en la cual un núcleo atómico inestable transforma uno de sus nucleones (protones o neutrones) en otro tipo de nucleón. Durante este proceso, se emite una partícula beta (un electrón o un positrón) y un neutrino asociado. Este fenómeno está mediado por la fuerza nuclear débil. Existen dos tipos principales de desintegración beta:
Desintegración Beta negativa: un neutrón dentro del núcleo se convierte en un protón. Se emite un electrón (partícula beta negativa) y un antineutrino electrónico. Aumenta el número de protones en el núcleo, lo que cambia el elemento químico a uno con un número atómico mayor.
Desintegración Beta positiva: un protón dentro del núcleo se convierte en un neutrón. Se emite un positrón (partícula beta positiva) y un neutrino electrónico. Disminuye el número de protones en el núcleo, cambiando el elemento químico a uno con un número atómico menor.
Un protón del núcleo captura un electrón orbital y se convierte en un neutrón. Se emite un neutrino electrónico. Los neutrinos electrónicos son producidos en grandes cantidades en estrellas durante el proceso de fusión nuclear. También son fundamentales en eventos como las supernovas, donde transportan la mayor parte de la energía liberada. En resumen, el neutrino electrónico es una partícula clave tanto para entender la física fundamental como para estudiar fenómenos cósmicos y nucleares.
La fuerza nuclear débil es una de las cuatro fuerzas fundamentales de la naturaleza, junto con la fuerza gravitacional, electromagnética y nuclear fuerte. Aunque es la más débil después de la gravedad, juega un papel crucial en varios procesos subatómicos, especialmente aquellos relacionados con la transformación de partículas y la radioactividad. La fuerza nuclear débil tiene un alcance extremadamente corto, del orden de 10-18 metros, mucho menor que el tamaño de un núcleo atómico. La fuerza débil actúa sobre partículas fundamentales como los quarks y leptones, y permite cambios en el tipo de estas partículas, por ejemplo, en la desintegración de neutrones o protones.
Este proceso tiene dos consecuencias. Dentro del propio núcleo, un neutrón se ha transformado en un protón. El núcleo contiene el mismo número de constituyentes que antes, pero ahora tiene un neutrón menos y un protón más. El núcleo tiene ahora una carga positiva más que antes, pero la carga total se conserva con la aparición del electrón cargado negativamente, que, al ser ciego a la fuerza nuclear fuerte, escapa del núcleo. Un cambio en el número de protones equivale a un cambio en la identidad química, lo que significa que, debido a esta radiactividad beta, el elemento se ha movido un lugar más arriba en la tabla periódica; en otras palabras, se ha producido la transmutación nuclear. La segunda consecuencia es que el electrón y el neutrino son irradiados desde el átomo. El neutrino es tan fantasmal que es difícil de detectar, pero el electrón, con carga eléctrica, no puede esconderse. El electrón, o partícula beta en la jerga histórica, es el fenómeno detectable de que algo ha sucedido. Fue la observación de los efectos de la radiación beta, como el empañamiento de las placas fotográficas, lo que dio las primeras pistas sobre la energía encerrada en las profundidades de los átomos y condujo al descubrimiento del núcleo atómico.
6.3.4 Radiación beta
El fenómeno de la desintegración beta, en el que la carga de un núcleo cambia en una unidad, se produce cuando un neutrón en ese núcleo se convierte en un protón o viceversa. Cuando un neutrón, neutro, se convierte en un protón cargado positivamente, la carga eléctrica en general se equilibra con la emisión de un electrón. También es posible que un protón se convierta en un neutrón, acompañado de la emisión de la versión de antimateria cargada positivamente del electrón. Como nuestro entorno está hecho de materia, y como la antimateria se destruye cuando toca su doppelgänger de materia, el positrón pronto golpea un electrón perdido y ambos desaparecen en un estallido de luz, aniquilándose en un estallido de energía pura.
El hecho de que también se produzca un neutrino era menos obvio y tardó años en establecerse, con mediciones meticulosas de las propiedades de la desintegración beta que produce positrones o electrones. Estos experimentos revelaron que el cambio en la energía del núcleo en estas desintegraciones beta no es igual a la energía del electrón o positrón. Se encontró que esta partícula cargada emerge con una cantidad de energía que varía desde casi nada hasta un valor máximo. La interpretación es que el electrón (o positrón) está acompañado por una partícula invisible, el neutrino. El cambio total de energía es compartido entre estas dos partículas, lo que explica por qué la energía del electrón (o positrón) observado puede variar. Ninguno de los electrones, positrones o neutrinos preexiste dentro del núcleo; son creados por una fuerza que ha desencadenado la descomposición. Esta fuerza se conoce como fuerza nuclear débil. "Débil" refleja el hecho de que su intensidad es mucho menor que la de la fuerza nuclear fuerte, que une protones y neutrones en grupos, y también más débil que la fuerza electromagnética.
A mediados del siglo XX, la imagen básica de la materia era que consistía en neutrones y protones dentro del núcleo atómico, con electrones a cierta distancia, formando átomos. Los neutrinos, que son hermanos eléctricamente neutros del electrón, hacen su aparición gracias a la desintegración beta. También había surgido la conciencia de la antimateria, sobre todo con el descubrimiento del positrón. Una propiedad fundamental de la antimateria es que una partícula tiene la misma masa que su partícula análoga y la misma cantidad de carga eléctrica, pero de signo opuesto. Por lo tanto, los positrones tienen carga positiva de la misma magnitud que el electrón. La antimateria se destruye cuando se encuentra con la materia. Por lo tanto, los positrones no desempeñan ningún papel en la construcción de átomos materiales ni tienen ninguna relación con el voluminoso protón. Que la cantidad de carga de un protón sea idéntica a la de un positrón es, a nuestro entender, un fenómeno afortunado que pide explicación.
La clave de la desintegración beta es que la diferencia de la carga del protón y el neutrón es igual a la que existe entre el electrón y el neutrino. Sin embargo, no hay nada que requiera que las cargas de electrones y protones se equilibren, o que tanto el neutrón como el neutrino sean neutros. Esto es clave para nuestra comprensión del comportamiento de las partículas fundamentales y merece una explicación cuidadosa.
Cuando un neutrón se convierte en un protón, por ejemplo, la magnitud de su carga aumenta en una cantidad que podríamos llamar una unidad positiva. Para preservar la carga total, debe aparecer, de alguna manera, una unidad de carga negativa. Aunque la materia se ha transformado —de neutrón a protón en este caso—, no se ha creado ni destruido nada en general. Al principio había una partícula nuclear, un neutrón, y otra al final, un protón.
Esta unidad de carga negativa es transportada por algo que, por lo general, no es materia ni antimateria. Hoy sabemos que este portador es un bosón W cargado negativamente, en efecto, un análogo masivo cargado eléctricamente de un fotón. La carga eléctrica surge en el mundo microscópico transportada por un electrón, que es una partícula material. Como el bosón W no es ni materia ni antimateria, y como la suma total de materia y antimateria se conserva, lo que acabo de llamar el neutrino es, en realidad, un antineutrino.
El contenido material del electrón y el antineutrino se cancela; la carga eléctrica permanece. Ahora se aplica un poco de aritmética. Supongamos que el electrón lleva una carga
Qe y el antineutrino lleva Qa. La conservación de la carga requiere Qe+Qa=−1.
La carga de un antineutrino es opuesta a la de un neutrino: Qa=−Qv. En consecuencia, la ecuación de conservación de la carga se convierte en Qe−Qv=−1, en otras palabras, la diferencia de las cargas eléctricas del electrón y el neutrón debe ser igual a la diferencia entre las cargas eléctricas del neutrón y el protón. No hay nada que requiera que las cargas del electrón y el protón se equilibren, ya que no hay ninguna combinación que imponga
Qe+Qp=0. Por ejemplo, la desintegración beta podría ocurrir si el neutrón y el protón tuvieran cargas eléctricas de, digamos,
−1/3 y +2/3 en relación con la cantidad empírica del protón, designada como +1. La neutralidad de los átomos permite que ocurra la desintegración beta, pero no es requerida por ella. Esa parte del rompecabezas de la carga aún no se ha explicado.
Fuerza electromagnética
El campo gravitatorio del Sol se extiende en todas las direcciones de manera uniforme, y su intensidad disminuye en proporción al cuadrado de la distancia. De manera análoga, la carga eléctrica de un núcleo atómico estático genera un campo eléctrico con propiedades similares. Dentro de los confines de un átomo, donde el núcleo central actúa como una concentración de carga eléctrica en reposo, esta descripción es suficiente para explicar su comportamiento. Sin embargo, si la carga eléctrica está en movimiento, la corriente eléctrica resultante genera tanto campos eléctricos como magnéticos, agregando una complejidad adicional al análisis del sistema.
Una carga eléctrica en movimiento circular, ya sea orbitando o girando, genera un campo magnético. La dirección de esta rotación, ya sea en el sentido de las agujas del reloj o en sentido contrario alrededor de un eje, determina la orientación del campo magnético, que puede ser comparable al comportamiento de un polo magnético norte o sur. Por supuesto, lo que parece ser una rotación en el sentido de las agujas del reloj desde un punto de vista "superior" se convierte en una rotación en sentido contrario desde el punto de vista opuesto. El modelo de una carga en rotación proporciona una representación intuitiva de un imán dipolar, que actúa como un polo norte desde un lado y como un polo sur desde el otro. A una escala más grande, las corrientes eléctricas que fluyen y se arremolinan dentro del núcleo fundido de la Tierra son responsables de la generación del campo magnético planetario. Los polos magnéticos norte y sur de la Tierra son regiones donde las líneas del campo magnético emergen y se hunden, extendiendo sus efectos hacia el espacio circundante, formando una magnetosfera que se proyecta a decenas de miles de kilómetros más allá de la superficie terrestre.
La electricidad y el magnetismo están íntimamente relacionados. Lo que vemos como carga estática, un transeúnte lo describiría como si estuviera en movimiento con respecto a él. Verán esa carga como una corriente eléctrica. Nosotros percibimos esa carga eléctrica estática como la fuente de un campo eléctrico, mientras que ellos verán una corriente eléctrica que genera tanto campos eléctricos como magnéticos. En general, los efectos eléctricos se mezclan con el magnetismo, y su importancia relativa percibida depende de su movimiento. Esta es una razón por la cual la teoría de la relatividad, válida cualquiera que sea su movimiento uniforme, habla solo de su combinación: el campo electromagnético. Los fenómenos físicos, como la repulsión entre dos cargas positivas o entre dos polos magnéticos idénticos, son invariantes, pero la descripción matemática en términos de campos eléctricos o de campos magnéticos depende de su movimiento.
Un dinamo eléctrico es un ejemplo de una profunda mezcla. El dinamo contiene dos imanes, uno estacionario y otro giratorio. El imán estacionario crea un potente campo magnético; el imán giratorio distorsiona y corta ese campo magnético estático. El entrelazamiento de estos efectos magnéticos, combinado con el movimiento, da lugar al flujo de electricidad. En 1865, James Clerk Maxwell codificó todos los fenómenos eléctricos y magnéticos conocidos en una serie de ecuaciones. Estas describen cómo los campos eléctricos y magnéticos son generados por cargas y corrientes eléctricas. A finales del siglo XIX, se había identificado el portador más fundamental de la carga eléctrica: el electrón. Las ecuaciones de Maxwell describen cómo la carga eléctrica de un electrón estático está rodeada por un campo eléctrico e implican que agitar una carga eléctrica interrumpirá su campo eléctrico, lo que provocará una explosión de radiación electromagnética. Algo similar sucede si un imán se agita y su campo magnético se altera. Las mediciones de las intensidades de las fuerzas eléctricas y magnéticas ayudan a determinar dos cantidades que aparecen en las ecuaciones de Maxwell. Conocidas por los trabalenguas “permeabilidad magnética” y “permisividad eléctrica”, son, en efecto, medidas de la facilidad con que el espacio vacío responde a un cambio en los campos magnéticos o eléctricos, respectivamente. Según la teoría de Maxwell, la radiación electromagnética surge cuando un campo eléctrico se transforma en un campo magnético o viceversa. Este balancín es continuo, y el resultado es una onda de radiación electromagnética. La velocidad con la que viajan estas ondas es proporcional a las magnitudes de la permitividad eléctrica y la permeabilidad magnética, y resulta ser la misma que la velocidad medida de la luz.
La implicación de las ecuaciones de Maxwell, de que un campo electromagnético oscila y se propaga como una onda que viaja a la velocidad de la luz, produjo una conclusión adicional obvia: la luz es una onda electromagnética. Las ondas de radio, los rayos X y el arcoíris de la luz visible son ejemplos de ondas electromagnéticas que se distinguen simplemente por la frecuencia con la que oscilan los campos. Lo que el ojo humano percibe como colores es su respuesta a las diferentes frecuencias dentro de un pequeño rango del espectro electromagnético. Este arcoíris cubre una octava, en el sentido de que la frecuencia de la extensión violeta de nuestra visión es el doble que la del rojo. La luz ultravioleta consta de frecuencias inmediatamente más altas que la luz violeta, mientras que las frecuencias más bajas que la luz roja se conocen como infrarrojas. Nuestros ojos no ven los rayos infrarrojos, pero nuestra piel puede sentir su impacto en forma de calor. Al mismo tiempo, las frecuencias más bajas corresponden a las ondas de radio, mientras que en el otro extremo, en las frecuencias ultra altas, están los rayos X y los rayos gamma.
La teoría cuántica implica que hay una dualidad entre ondas y partículas. En la teoría cuántica de campos, el suave aumento y descenso de la intensidad característica de una onda electromagnética parece ser un estallido entrecortado de intensidades individuales que actúan como partículas sin masa: fotones. Los fotones pueden aparecer y desaparecer. Enciende un fósforo o acciona un interruptor de luz, y un gran número de fotones entrarán en existencia. Pero los fotones no son para siempre. Por ejemplo, los que están en la luz solar son absorbidos por las plantas, y su energía se convierte en vida a través del proceso conocido como fotosíntesis. Mientras lees esta página, los fotones de luz entran en tu retina y se desvanecen, y su energía desencadena señales eléctricas en el nervio óptico.
No hay en la teoría clásica de Maxwell un lugar donde los fotones aparezcan de la nada y luego desaparezcan en el olvido. Para comprender los fotones, desde su creación hasta su destrucción, es necesario que la teoría se aplique no solo a las partículas, sino también al campo electromagnético. La combinación de la mecánica cuántica, la relatividad especial y la teoría electromagnética conduce a la electrodinámica cuántica, una creación del físico teórico de Cambridge, Paul Dirac. Tradicionalmente se le conoce por su acrónimo, QED, que es acertado, ya que QED tiene tanto éxito que, durante casi un siglo, ha sido el paradigma de las teorías cuánticas de los campos de fuerza. En este modelo, las partículas elementales son manifestaciones de campos cuánticos, y sus propiedades e interacciones son consecuencia de principios de simetría y de la dinámica de estos campos.
La Electrodinámica Cuántica (QED, por sus siglas en inglés) es una aplicación específica de la Teoría Cuántica de Campos (QFT, por sus siglas en inglés). La QFT es un marco teórico general que combina los principios de la mecánica cuántica y la relatividad especial para describir las interacciones fundamentales entre partículas y campos. Dentro de este marco, la QED se centra en la interacción entre partículas cargadas y el campo electromagnético, describiendo cómo los electrones y los fotones interactúan a nivel cuántico.En el marco de la Teoría Cuántica de Campos (QED, por sus siglas en inglés), un fotón es interpretado como una excitación cuántica del campo electromagnético. A diferencia de la visión clásica, donde el campo electromagnético es una entidad continua que se propaga en el espacio, la QED describe este campo como una colección de cuantos discretos de energía, es decir, fotones. Cada fotón posee características específicas como energía, momento lineal y espín, que corresponden a las propiedades del campo electromagnético en el espacio-tiempo. Esta perspectiva permite una comprensión más profunda de fenómenos como la emisión y absorción de luz, la dispersión de partículas cargadas y las interacciones fundamentales en el ámbito cuántico.
Es importante destacar que, en la QFT, los fotones no son partículas en el sentido clásico, sino manifestaciones cuánticas de fluctuaciones en el campo electromagnético. Esta conceptualización es fundamental para explicar fenómenos como la interferencia y la difracción, que no pueden ser entendidos completamente desde una perspectiva puramente corpuscular. En resumen, dentro de la Teoría Cuántica de Campos, un fotón es la manifestación cuántica del campo electromagnético, representando la unidad básica de interacción de este campo y desempeñando un papel crucial en la descripción de las interacciones electromagnéticas a nivel fundamental.
En el contexto de la Teoría Cuántica de Campos (QFT, por sus siglas en inglés), la manifestación cuántica del campo electromagnético se refiere a la descripción del campo electromagnético en términos de cuantos de energía discretos conocidos como fotones. Esta perspectiva difiere de la visión clásica, donde el campo electromagnético es una entidad continua que se propaga en el espacio.
En la QFT, el campo electromagnético es tratado como un operador cuántico que puede ser excitado para producir partículas discretas, es decir, los fotones. Estas excitaciones cuánticas explican fenómenos que la teoría clásica no puede abordar adecuadamente, como la cuantización de la energía en la radiación electromagnética y las interacciones entre la luz y la materia a nivel microscópico.
Este enfoque permite una comprensión más profunda de las propiedades y comportamientos del campo electromagnético, integrando principios de la mecánica cuántica y la teoría de campos para describir de manera precisa las interacciones electromagnéticas en el ámbito subatómico.
Evaluación 4__________
6.3.5 ¿Cómo es un electrón?
El primer paso es tener una descripción cuántica de un electrón cargado solitario que sea consistente con la teoría de la relatividad. Esta historia comienza en 1928, cuando Paul Dirac combinó las dos grandes teorías del siglo XX, la teoría cuántica y la relatividad especial de Einstein, para construir una descripción matemática del electrón. La teoría cuántica describe cosas muy pequeñas a escala atómica, y la teoría especial de la relatividad de Einstein se ocupa de cosas que se mueven muy rápido. Los electrones son muy ligeros, y en los campos eléctricos se pueden acelerar para que se muevan más rápido, por lo que se necesita la relatividad para describirlos. Sin embargo, Dirac descubrió que no podía lograr una descripción matemática consistente escribiendo una sola ecuación. En cambio, su única ecuación tuvo que interpretarse como el significado físico de cuatro ecuaciones enlazadas.
La primera duplicación implica que el electrón es más que un trozo de carga. Para comportarse consistentemente con las restricciones de la relatividad, el electrón también debe actuar como un imán, como si tuviera un solo polo norte y un polo sur. En otras palabras, para comportarse de acuerdo con la teoría de la relatividad especial de Einstein, un electrón cargado eléctricamente debe actuar como un dipolo magnético. Ya había evidencia de esto antes de que las matemáticas de Dirac tropezaran con ella. Los electrones no pueden moverse al azar dentro de los átomos, sino que deben seguir caminos específicos restringidos por la teoría cuántica. Esto implica que solo pueden existir con ciertos valores discretos de energía. Recordemos nuestra analogía de una escalera, cuyos peldaños representan los niveles de energía del electrón en el átomo. Cuando un electrón cae de un peldaño de alta energía a uno más bajo, la diferencia en su energía se irradia como luz. Es debido a que los valores de estas energías son discretos que el espectro no se extiende continuamente como un arcoíris, sino que consta de una serie de líneas.
Cuando los electrones se colocan dentro de un campo magnético, el carácter de las líneas espectrales puede cambiar de manera notable. En ciertos casos, una sola línea espectral se divide en un par ligeramente separado. Este fenómeno, conocido como el "efecto Zeeman", fue descubierto por el espectroscopista holandés Pieter Zeeman en 1896, mucho antes del desarrollo de la teoría cuántica de los electrones en los átomos. Hoy en día, comprendemos que el efecto Zeeman revela que lo que parecía ser un único nivel de energía para el electrón es, en realidad, dos niveles distintos. La separación entre estos niveles crece en proporción a la intensidad del campo magnético aplicado. Este comportamiento sugiere que el electrón actúa como un imán dipolar. De manera figurada, podemos imaginar que la energía del electrón aumenta o disminuye ligeramente dependiendo de si su "polo norte" o "polo sur" está alineado con la dirección de la fuerza magnética. Este fenómeno es análogo a la repulsión o atracción que ocurre entre dos imanes al ser alineados o enfrentados.
Mientras que la primera bifurcación de la ecuación de Dirac explicó de manera satisfactoria la dualidad magnética del electrón, la segunda bifurcación parecía, a primera vista, completamente absurda. Aunque el primer par de soluciones describía con éxito un electrón magnético con energía positiva, la segunda bifurcación parecía sugerir la existencia de un electrón con energía negativa. Esto no tenía sentido, ya que la ecuación de Dirac había sido concebida para describir un electrón completamente libre de interacciones con su entorno. La idea de que pudiera tener energía negativa resultaba desconcertante. Esta paradoja preocupó a Dirac durante algún tiempo, hasta que logró reinterpretar su significado. Lo que inicialmente parecía una solución de energía negativa para un electrón cargado negativamente, Dirac se dio cuenta de que podía entenderse como la descripción de una nueva partícula: un electrón con energía positiva pero con carga positiva. En aquel entonces, la existencia de tal partícula era completamente desconocida, pero en 1932 se descubrió el positrón en los rayos cósmicos, confirmando la predicción teórica de Dirac. Este hallazgo fue revolucionario, ya que el positrón se convirtió en la primera partícula de antimateria identificada, abriendo nuevas fronteras en la física de partículas.
El hecho de que la ecuación de Dirac haya requerido la existencia de antimateria en forma de positrón antes de que los humanos tuvieran evidencia empírica de su existencia es un ejemplo notable de la sorprendente capacidad de las matemáticas para anticipar la realidad física. Las matemáticas, en su misteriosa profundidad, parecen ser capaces de describir aspectos del Universo antes de que la experiencia empírica humana los descubra. Hoy en día, conocemos múltiples ejemplos de antipartículas, muchas de las cuales tienen propiedades que la ecuación de Dirac describe con precisión. Entre ellas, una de las más relevantes para nuestros propósitos es el antineutrino, la contraparte de antimateria del neutrino. Así como el neutrino es el compañero eléctricamente neutro del electrón, el antineutrino es el par del positrón. Si el neutrino tuviera carga eléctrica, entonces el antineutrino tendría la misma magnitud de carga, pero con signo opuesto. Sin embargo, empíricamente sabemos que el neutrino es eléctricamente neutro, lo que implica que el antineutrino también lo es. Esto lleva a una pregunta natural: ¿qué distingue entonces a un neutrino de un antineutrino? La respuesta radica en cómo interactúan con los núcleos atómicos. Cuando un neutrino interactúa con un núcleo, puede producir un electrón, mientras que, en el núcleo, un neutrón se convierte en un protón para conservar la carga eléctrica total. Por otro lado, en el caso de un antineutrino, este puede producir un positrón, y en el núcleo, un protón se convierte en un neutrón, nuevamente conservando la carga total. En ambos procesos, no solo se conserva la carga eléctrica, sino también las cantidades de materia y antimateria de forma independiente, lo que es esencial para mantener el equilibrio en las interacciones fundamentales.
6.4 Derivada ordinaria
Asumamos una función de una variable f(x). Nos preguntamos: ¿qué hace la derivada dx/df por nosotros? Nos dice qué tan rápido varía la función f(x) cuando cambia el argumento de la variable independiente x en una pequeña cantidad dx. En otras palabras, si incrementamos x en una cantidad infinitesimal dx, entonces f(x) cambia en una cantidad df; la derivada es el factor de proporcionalidad entre ambos cambios.
 10.23.16.png)
La interpretación geométrica de la derivada dx/df es la pendiente de la recta tangente en cada punto de la curva, es decir, el ángulo que generan todas las rectas tangentes a lo largo de la gráfica de la función.
6.4.1 Derivada vectorial
Funciones de varias variables. Supongamos ahora que tenemos una función de tres variables T(x,y,z) en esta habitación. Queremos generalizar la noción de derivada a funciones como T, que dependen no de una, sino de tres variables. Se supone que una derivada nos dice qué tan rápido varía la función si nos movemos una pequeña distancia. Pero esta vez la situación es más complicada, porque depende de la dirección en la que nos movamos: si vamos hacia arriba, entonces la temperatura probablemente aumentará con bastante rapidez; pero si nos desplazamos horizontalmente, puede que no cambie mucho. De hecho, la pregunta “¿qué tan rápido varía T?” tiene un número infinito de respuestas, una para cada dirección que podríamos elegir explorar.
 16.36.24.png)
Esto nos dice cómo cambia T cuando alteramos las tres variables por las cantidades infinitesimales de longitud dl (dx,dy,dz). Tenga en cuenta que no requerimos un número infinito de derivadas: tres serán suficientes: las derivadas parciales a lo largo de cada una de las tres direcciones de coordenadas.
La ecuación anterior recuerda un producto punto:
 16.43.51.png)
Donde:
 16.44.55.png)
Se llama gradiente ∇T es una cantidad vectorial, con tres componentes; es la derivada generalizada que hemos estado buscando, ∇T º dl es una versión tridimensional de df/dx. La interpretación geométrica del gradiente: como cualquier vector, el gradiente tiene magnitud y dirección. Para determinar su significado geométrico, reescribimos el producto punto:
 16.52.19.png)
Donde ? es el ángulo entre ∇T y dl. Ahora, si fijamos la magnitud |dl| y buscamos en varias direcciones (es decir, variar ? ), el cambio máximo en T ocurre evidentemente cuando ? =0 (para entonces cos ? =1). Es decir, para una distancia fija |dl|, dT es mayor cuando nos movemos en la misma dirección que ∇T.
El gradiente ∇T apunta en la dirección del aumento máximo de la función T. Además, la magnitud |∇T| da la pendiente (tasa de aumento) a lo largo de esta dirección máxima.
El gradiente en dos dimensiones. Imagina que estás parado en una ladera. Mira a tu alrededor y encuentra la dirección del gradiente. Ahora mide la pendiente en esa dirección (ascenso sobre la carretera). Esa es la magnitud del gradiente. Aquí la función de la que hablamos es la altura de la colina, y las coordenadas de las que depende son las posiciones: latitud y longitud, por ejemplo. Esta función depende de solo dos variables, no de tres, pero el significado geométrico del gradiente es más fácil de comprender en dos dimensiones. Observa que la dirección del descenso máximo es opuesta a la del ascenso máximo, mientras que en ángulo recto (θ=90º) la pendiente es cero (el gradiente es perpendicular a las curvas de nivel). Existen superficies que no cumplen estas propiedades, pero siempre presentan “torceduras” y corresponden a funciones no diferenciables.
¿Qué significa que el gradiente se desvaneciera? Si ∇T=0 en (x,y,z), entonces dT=0 para pequeños desplazamientos alrededor del punto (x,y,z). ∇T es entonces, un punto estacionario de la función T(x,y,z). Podría ser un máximo (una cumbre), un mínimo (un valle), un punto de silla de montar (un paso) o un hombro. Esto es análogo a la situación de las funciones de una variable, donde una derivada que se desvanece señala un máximo, un mínimo o una inflexión. En particular si se desea ubicar los extremos de una función de tres variables, establezca un gradiente igual a cero.
Decir que el gradiente se desvanece significa que el vector gradiente de la función T(x,y,z), es decir:
∇T(x,y,z)=(∂T/∂x,∂T/∂y,∂T/∂z)
es igual al vector nulo en ese punto.
En términos geométricos:
El gradiente indica la dirección de máximo crecimiento de la función en un punto. Si ∇T=0, no hay ninguna dirección en la que la función aumente o disminuya de manera inmediata. Es un punto donde la superficie es horizontal (sin pendiente local). Ese punto se llama punto estacionario o crítico.
A partir de ahí, para clasificar si es:
Máximo local (cumbre): la función disminuye en todas direcciones.
Mínimo local (valle): la función crece en todas direcciones.
Punto de silla (saddle): la función crece en unas direcciones y decrece en otras.
Punto de inflexión o hombro: la superficie es “plana” localmente, sin ser un extremo claro.
Como ejemplo calcule el gradiente r=(x^2+y^2+z^)^(1/2) (la magnitud r de la posición vector).
 17.25.33.png)
¿Tiene sentido esto? Bueno, dice que la distancia desde el origen aumenta más rápidamente en la dirección radial es 1… justo lo que esperarías.
6.4.2.1 El operador Del
El degradado tiene la apariencia formal de un vector, es decir ∇, “multiplicado” una T escalar:
 10.48.16.png)
Por supuesto, Del no es un vector, en el sentido habitual. De hecho, no significa mucho hasta que le damos una función sobre la que actuar. Además, no multiplica T, más bien, es una instrucción (un operador) para diferenciar lo que sigue. Para ser precisos, entonces, decimos que ∇ es un operador vectorial que actúa sobre T, no un vector que multiplica T.
Sin embargo, con esta calificación, ∇ imita el comportamiento de un vector ordinario en prácticamente todos los sentidos; casi cualquier cosa que se pueda hacer con otros vectores también se puede hacer con ∇, si simplemente traducimos “multiplica” como “actuar sobre”. Así que, por su puesto, tómese en serio la apariencia vectorial de ∇: es una maravillosa pieza de simplificación de la notación, como apreciará si alguna vez consulta el trabajo original de Maxwell sobre electromagnetismo, escrito sin el beneficio de ∇.
Ahora, un vector ordinario A puede multiplicar de tres maneras:
Por un sacar a: aA;
Por un vector B a través del producto punto: A . B;
Por un B a través del producto cruz: A x B;
En consecuencia, hay tres formas en que el operador ∇ puede actuar:
Sobre una función escolar T: ∇T (Gradiente);
Sobre una función vectorial v por el producto punto: ∇.v (el divergente);
Sobre una función vectorial v por el producto punto: ∇ x v (el rotor);
A partir de la definición de ∇ construimos la divergencia:
 11.07.53.png)
Observe que la divergencia de una función vectorial v es en sí misma un escalar,∇.v. Interpretación geométrica: el nombre divergente está bien elegido, por ∇.v es una medida de cuánto se extiende (diverge) el vector v desde el punto en cuestión. Por favor, comprenda que v aquí es una función: hay un vector asociado con cada punto en el espacio. En los diagramas, solo podemos dibujar las flechas en uno pocos lugares representativos.
Imagínese parado al borde de un estanque. Espolvorea un pco de aserrín de pino en la superficie. Si el material se extiende, entonces lo dejaste caer en un punto de divergencia positiva; si se junta, lo dejaste caer en un punto de divergencia negativa. La función vectorial v en este modelo es la velocidad del agua en la superficie; este es un ejemplo bidimensional, nos da una sensación de lo que significa la divergencia. Un punto de divergencia positiva es una fuente, “grifo”; un punto de divergencia negativa es un sumidero o “drenaje”.
6.4.2.2 El rotor
A partir de la definición de ∇ construimos el rotor:
 18.38.42.png)
Observe que el rotor de una función vectorial v es, como cualquier producto cruzado, un vector. La interpretación geométrica: el nombre de rotor también está bien elegido, ya que ∇ x v es una medida de cuánto gira el vector v alrededor del punto en cuestión.
 18.44.32.png)
Relaciones de derivadas vectoriales.
 18.45.33.png)
 18.45.51.png)
 18.46.16.png)
 18.46.24.png)
 18.46.37.png)
 18.47.30.png)
El gradiente, la divergencia y el rotor son las únicas primeras derivadas que podemos hacer con ∇; al aplicar dos veces Del, podemos construir cinco especies de segundas derivadas. El gradiente ∇T es un vector, por lo que podemos tomar la divergencia y el rotor del mismo:
Divergente del gradiente ∇.∇T;
Rotor del gradiente ∇x∇T;
Divergente de un rotor: ∇.(∇x∇T);
Rotor de un rotor: ∇x(∇x∇T).
6.4.2.3 Laplaciano
 19.00.11.png)
El rotor de un gradiente siempre es cero.
 19.03.11.png)
Este es un hecho importante, que usaremos repetidamente, se puede probar fácilmente a partir de la definición ∇. Cuidado: podrías pensar que es obviamente cierto: ¿no es solo (∇x∇)T, y no es el producto cruzado de cualquier vector ( en este caso, ∇) consigo mismo siempre es cero? Este razonamiento es sugerente, pero no del todo concluyente, ya que ∇ es un operador y no se multiplica de la manera habitual. La prueba de hecho, depende de la igualdad de las derivadas cruzadas:
 19.06.52.png)
Evaluación 5__________
6.4.3 Integrales de linea, superficie y volumen
En el electromagnetismo encontramos varios tipos distintos de integrales, entre las cuales las más importantes son las integrales de línea (o de camino), las integrales de superficie (o de flujo) y las integrales de volumen.
Integrales de línea. Una integral de este tipo es una expresión de la forma:
 12.37.07p.m.png)
Donde v es una función vectorial, dl es el desplazamiento infinitesimal vectorial:
 12.39.31p.m.png)
Y la integral debe realizarse a lo largo de un camino prescrito desde el punto a hasta el punto b.
 12.42.21p.m.png)
Si el cambio en cuestión forma un lazo cerrado (es decir, si b=a), se pondrá un círculo sobre el singo de la integral:
 12.44.34p.m.png)
En cada punto del camino, tomamos el producto escolar de v (evaluado en ese punto) con el desplazamiento dl al siguiente punto a lo largo del camino. Para un físico, el ejemplo más conocido de una integral de línea es el trabajo realizado por una fuerza F:
 12.47.13p.m.png)
Normalmente el valor de una integral de línea depende críticamente del camino tomado de a a b, pero existe una clase especial importante de funciones vectoriales para las cuales la integral de línea es independiente del camino y está determinado enteramente por los puntos finales. Será nuestro trabajo a su debido tiempo caracterizar esta clase especial de vectores. Se dice que una fuerza que posee esta propiedad es conservadora.
Integral de superficie. Es una expresión de la forma:
 9.58.06a.m.png)
Donde v es de nuevo alguna función vectorial, y la integral está sobre una superficie especificada S. Aquí da es una mancha infinitesimal de área, con dirección perpendicular a la superficie.
 10.00.54a.m.png)
Por supuesto, existen dos direcciones perpendiculares a la superficie, por lo que el signo de una integral de superficie es intrínsecamente ambiguo. Si la superficie está cerrada (formando un lazo) en cuyo caso volveremos poner un círculo sobre el signo integral:
 10.03.39a.m.png)
Entonces la tradición dicta que “hacia afuera” es positivo, pero para superficies abiertas es arbitrario. Si v describe el flujo de un fluido (masa por unidad área por unidad de tiempo) entonces v?da representa la masa total por unidad de tiempo que atraviesa la superficie, de ahí el nombre alternativo de “flujo”. Normalmente, el valor de una integral de superficie depende de la superficie particular elegida, pero existe una clase especial de funciones vectoriales para la línea de frontera. Una tarea de cálculo particular para nosotros será caracterizar esta clase especial de funciones.
Integral de volumen. A un volumen integral es una expresión de la forma:
 10.10.56a.m.png)
Donde T es una función escolar de dτ es un elemento de volumen infinitesimal:
 10.12.38a.m.png)
Por ejemplo, T es la densidad de una sustancia (que puede variar de un punto a otro) entonces la integral volumétrica daría la masa total. Ocasionalmente, nos encontramos con integrales de volumen de funciones vectoriales:
 10.14.31a.m.png)
Como los vectores unitarios de los ejes geométricos son contantes, están fuera de la integral.
6.4.4 El teorema fundamental del cálculo
Supongo que f(x) es una función de una variable. El teorema fundamental del cálculo dice que:
 10.17.29a.m.png)
Por si esto no le resulta familiar, los escribiremos de otra manera:
 10.18.43a.m.png)
Donde df/dx=F(x). El teorema fundamental nos dice cómo integrar F(x): se piensa en una función f(x) cuya derivada es igual a F. Interpretación geométrica df=(df/dx)dx es el cambio infinitesimal en f cuando pasa de x a x+dx. El teorema fundamental dice que si cortas el intervalo de a a b en muchas partes infinitesimales, dx, y sumas incrementos df de cada pequeño fragmento, el resultado es igual al cambio total en f: f(b) - f(a). en otras palabras, hay dos formas de determinar el cambio total en la función: o bien restar los valores en los extremos o ir paso a paso, sumando todos los pequeños incrementos a medida que avanzas. Obtendrás la misma respuesta de todas las formas. Observa la estructura del teorema fundamental: la integral de una derivada sobre alguna región está dada por el valor de la función en los puntos finales (fronteras). En cálculo vectorial existen tres especies de derivadas: gradiente, divergente y rotor. Y cada una de estas derivadas tiene su propio “teorema fundamental”, con esencialmente el mismo formato.
6.4.5 El teorema fundamental del gradiente
Supongamos que tenemos una función escalar de tres variables T(x,y,z). Partiendo del punto a, avanzamos una pequeña distancia dl1.
 11.46.13a.m.png)
 11.45.42a.m.png)
Ahora avanzamos un poco más, con un desplazamiento adicional pequeño dl2: el cambio incremental en T será (∇T)?dl2. De este modo, avanzamos por pasos infinitesimales, realizamos el viaje hasta el punto b. En cada paso calculamos el gradiente de T en ese punto y lo ponemos en el desplazamiento dl… esto nos da el cambio en T. Evidentemente, el cambio total en T al pasar de a a b a lo largo de la trayectoria de camino seleccionada es
 11.58.27a.m.png)
Este es el teorema fundamental para los gradientes; al igual que el teorema fundamental “ordinario”, dice que la integral aquí una integral de línea de una derivada (aquí el gradiente) está dada por el valor de la función en los límites a y b.
Interpretación geométrica: supongamos que quieres determinar la altura de la Torre Eiffel. Podrías subir las escaleras, usando una regla para medir la subida en cada escalón y sumarlas todas o podrías colocar altímetros en la parte superior y la inferior, y restar las dos lecturas; deberías obtener la misma respuesta todas formas (ese es el teorema fundamental).
Por cierto, como encontramos en la ecuación anterior, las integrales de línea normalmente dependen del camino que se toma de a a b. Pero el lado derecho de la ecuación no hace referencia al camino, ¡solo a los puntos finales! Evidentemente, los gradientes tienen la capacidad especial de que sus integrales de línea son independientes de camino de trayectoria.
Corolario 1. La integral
 12.30.50p.m.png)
Es independiente el el camino de trayectoria entre a y b.
Corolario 2: La integral
 12.32.39p.m.png)
Ya que los puntos de principio y final son idénticos, y por tanto T(b) -T(a)=0.
Evaluación 6__________
6.4.6 Teorema fundamental del divergente
La expresión del teorema fundamental del divergente:
 12.53.23p.m.png)
En honor, supongo, por su gran importancia, este teorema tiene al menos tres nombres diferentes: teorema de Gauss, teorema de Green o simplemente teorema del divergente. Como otros “teoremas fundamentales”, dice que la integral de una derivada vectorial (en este caso la del divergente” sobre una región (en este caso un volumen V) es igual al valor de la función en el límite en este caso la superficie S que limita el volumen. Observar que el término frontera es en sí mismo una integral específicamente una integral superficial. Esto es razonable: la “frontera” de una recta son solo dos puntos finales, pero la frontera de un volumen es una superficie cerrada. Interpretación geométrica: Si v representa fluido incompresible, entonces el flujo de v es la cantidad total de materia que pasa por la superficie, por unidad de tiempo. Ahora, la divergencia mide la “dispersión” de los vectores desde un punto: un lugar de alta divergencia es como un “grifo” vierte líquido. Si tenemos un montón de grifos en una región completamente llenos de flujo incompresible, una cantidad igual de líquido será expulsado a través de los límites de la región. De hecho, hay dos formas de determinar cuánto se está produciendo: a) podríamos contar todos los grifos infinitesimales, registrar el flujo en cada uno:
∫ (grifos dentro del volumen) = ? (flujo que atraviesa la superficie).
Esto, es esencial, es lo que dice el teorema de divergencia.
6.4.7 El teorema fundamental del rotor
El teorema fundamental del rotor, recibe el nombre especial de teorema de Stokes, establece que:
 1.10.48p.m.png)
Como siempre, la integral de una derivada (aquí el rotacional) sobre una región (aquí, un parche de superficie S) al igual al valor de la función en el límite (aquí, el perímetro del parche P) Como en el caso del teorema de divergencia, el término frontera es en sí mismo una integral, concretamente una integral de línea cerrada.
Interpretación geométrica: recuerda que el rotacional mide la “torsión” de los vectores v; una región de alta rotación es un remolino: si pones una rueda de paletas diminutas ahí, girará. Ahora, la integral del rotacional sobre alguna superficie (o más precisamente, el flujo del rotacional sobre alguna superficie) representa la “cantidad total de remolino” y podemos determinarlo igual de bien rodeando el borde y cuánto sigue el flujo al límite. De hecho, v?A veces se llama la circulación de v.
 2.37.13p.m.png)
Puede que hayas notado una aparente ambigüedad en el teorema de Stokes: respecto a la integral de línea límite, ¿hacia dónde se supone que debemos rodear (en el sentido horario o antihorario)? Si vamos por el camino “equivocado”, detectamos un error general de señal. La respuesta es que no importa hacia dónde vayas mientras seas consistente, porque hay una ambigüedad de signo compensador en el integral superficial: ¿hacia dónde apunta da? Para una superficie cerrada (como en el teorema de divergencia), da apunta en la dirección de la normal hacia fuera; pero para una superficie abierta, ¿qué dirección es “salir”? La consistencia en el teorema de Stokes (como en todos estos asuntos) se da por la regla de la mano derecha: si tus dedos apuntas en la dirección de la integral de línea, entonces tu pulgar fija la dirección de da.
 5.37.13p.m.png)
Ahora bien, hay muchas superficies (infinitas) que comparten cualquier línea límite dada. Gira un clip en forma de lazo y sumérgelo en agua jabonosa. La película de jabón constituye una superficie, con el lazo de alambre se expandirá, creando una superficie más grande, con el mismo límite. Normalmente, una integral de flujo depende críticamente de la superficie sobre la que se integre, pero evidentemente esto no ocurre con los rotores. Porque el teorema de Stokes dice que ((∇×v)?da) es igual a la integral de línea de v alrededor del borde, y este último no hace referencia a la superficie específica que elijas.
Corolario 1. La integral ∫(∇×v)?da depende únicamente de la línea límite, no de la superficie particular utilizada.
Corolario 2. La integral ?(∇×v)?da=0 para cualquier superficie cerrada, ya que la línea límite, como la boca de un globo, se reduce a un punto, y por tanto el lado derecho de la ecuación desaparece.
Estos corolarios son análogos a los del teorema del gradiente.
6.4.7.1 Integración por partes
La técnica conocida (de forma incómoda) como integración por partes explota la regla del producto para derivadas:
 7.18.06p.m.png)
Integrando ambos lados e invocando el teorema fundamental:
 7.19.04p.m.png)
o
 7.19.31p.m.png)
Eso es integración por partes. Se aplica a la situación en la que se te pide integrar el producto de una función f y la derivada de otra g: dice que puedes transferir la derivada de G a F, a costa de un signo y un término frontera.
Podemos explorar las reglas producto del cálculo vectorial, junto con los teoremas fundamentales apropiados, exactamente de la misma manera. Por ejemplo, integrando:
 7.23.05p.m.png)
Sobre un volumen, e invocando el teorema de divergencia, se obtiene:
 7.24.05p.m.png)
o
 7.24.31p.m.png)
Aquí de nuevo el integrando es el producto de una función f y la derivada en este caso la divergente de otra A, y la integración por partes nos permite transferir la derivada de A a f (donde se convierte en un gradiente), a costa de un signo menos y un término de frontera ( en este vado, una integral de superficie).
Quizá te preguntes con qué frecuencia es probable que uno encuentre una integral que involucre el producto de una función y la derivada de otra. La respuesta es… ¡Sorprendentemente a menudo! Y la integración por partes resulta ser una de las herramientas más potentes en cálculo vectorial.
6.4.8 La función delta de Dirac
La función delta de Dirac unidimensional, δ(x), puede representarse como un “pincho” infinitesimal alto e infinitesimal estrecho, con área.
 12.17.12p.m.png)
Es decir,
 12.18.05p.m.png)
Técnicamente, δ(x) no es una función en absoluto, ya que su valor es finito en x=0; en la literatura matemática se conoce como función generalizada, o distribución. Es, si se quiere, el límite de una secuencia de funciones, como los rectángulos Rn(x), de altura n y anchura 1/n, o triángulos isósceles Tn(x), de altura n y base 2/n.
 12.18.56p.m.png)
y
 12.19.21p.m.png)
Si f(x) es alguna “ordinaria” (es decir, no otra función delta —de hecho, por si acaso, digamos que f(x) es continua), entonces el producto f(x)δ(x) es cero en todas partes excepto en x=0, Se deduce que:
 12.25.36p.m.png)
Este es el hecho más importante sobre la función delta, así que asegúrate de comprender por qué es cierta: dada que el producto es cero de todos modos en x=0, bien podríamos reemplazar f(x) por el valor que asume en el origen. En particular:
 12.28.15p.m.png)
Bajo una integral, entonces, la función delta “seleccionada” el valor de f(x) en x=0. Aquí y abajo, la integral no tiene por qué ir de menos infinito a más infinito; basta con que esté a la altura de la función delta y - y +, basta con que esté a la altura de la función delta y - a + servirá igual. Por supuesto podemos desplazar el pico de x=0 a otro punto, x=a:
 12.31.56p.m.png)
 12.52.24p.m.png)
Se convierte en:
 12.53.00p.m.png)
Generalizada para:
 12.53.33p.m.png)
Aunque δ(x) en sí no es una función legítima, las integrales sobre δ(x) son perfectamente aceptables. De hecho, es mejor pensar en la función delta como algo que siempre está destinado a usarse bajo un signo entero. En particular, dos expresiones delta función (por ejemplo., D1(x) y D2(x) se consideran iguales si:
 12.56.38p.m.png)
Para todas las funciones “ordinarias” f(x).
En síntesis la función delta de Dirac no es, en sentido estricto, una función ordinaria; es una distribución o funcional generalizado introducido por Paul Dirac para modelar fenómenos idealizados en física y matemáticas.
Idea intuitiva. La delta de Dirac, denotada por δ(x), representa un “pico” infinitamente alto y infinitamente estrecho localizado en un punto (normalmente x=0), con la propiedad de que su área total es 1. De manera intuitiva:
Es cero en todas partes, excepto en un punto.
En ese punto, concentra toda su “masa”.
Su integral total vale uno.
La definición rigurosa de la delta no se da por su valor puntual, sino por cómo actúa dentro de una integral:
 1.07.10p.m.png)
para cualquier función continua (o suficientemente regular) f(x).
Esta es la propiedad de selección: la delta “extrae” el valor de la función en el punto donde está concentrada. Más generalmente:
 1.09.12p.m.png)
Por qué no es una función ordinaria
Si δ(x) fuera una función común:
- Tendría que ser infinita en x=0.
- Tendría que valer cero en todos los demás puntos.
- Su integral debería ser finita.
Esto es imposible dentro del análisis clásico. Por ello, la delta se formaliza dentro de la teoría de distribuciones (Schwartz), donde solo tiene sentido bajo el signo integral y actuando sobre funciones de prueba.
La delta de Dirac es indispensable para describir idealizaciones:
- Cargas puntuales:
ρ(r)=q δ(r−r0 ) - Fuerzas impulsivas:
F(t)=I δ(t−t0 ) - Condiciones iniciales localizadas
- Funciones de Green
- Mecánica cuántica (normalización, estados localizados).
Interpretación conceptual. En términos conceptuales, la delta de Dirac es una herramienta para pensar la presencia absoluta de algo en un solo punto, sin extensión espacial ni temporal, pero con efecto físico o matemático medible al integrarla. No describe la realidad “tal cual es”, sino una idealización límite que permite pensar con claridad y calcular con precisión.
Función 3D de Dirac
Es fácil generalizar la función de delta de tres dimensiones:
 1.21.33p.m.png)
 1.21.59p.m.png)
El vector posición, extendiendo desde el origen hasta el punto (x, y, z). Esta función delta tridimensional es cero en todas partes excepto en (0, 0, 0) donde se infla. Su integral de volumen es 1:
 5.05.55p.m.png)
Y generalizando:
 5.13.23p.m.png)
Como en el caso unidimensional, la integración con δ selecciona el valor de la función f en la ubicación del pico. Ahora estamos en posición de resolver la paradoja introducida al principio de este apartado, como recordará, descubrimos que la divergencia:
 1.31.50p.m.png)
Es cero en todas partes excepto en el origen, y sin embargo si integral sobre cualquier volumen que contiene el origen es constante (es decir, 4π). Estas son precisamente las condiciones definitorias para la función delta de Dirac; evidentemente
 1.34.22p.m.png)
Mas general:
 1.35.00p.m.png)
Donde r, como siempre, es el vector de separación: r =r - r’ Nótese que la diferenciación aquí es respecto a r, mientras que r se mantiene constante. Por cierto, ya que:
 1.36.32p.m.png)
De ello se deduce que:
 1.36.46p.m.png)
Evaluación 7__________
6.4.9 La teoría del campo vectorial
Incluimos aquí por completo y para ayudarte a distinguir consideraciones puramente matemáticas del contexto físico en el que ocurren. Léelo ahora para hacerte una idea del “panorama del terreno” y vuelve a consultarlo cuando sea necesario.
Un campo vectorial es una función que asigna un vector a cada punto de una región del espacio:
 1.50.41p.m.png)
Ejemplos intuitivos:
El campo de velocidad de un fluido (cada punto tiene una velocidad distinta).
El campo eléctrico alrededor de una carga.
El campo magnético generado por una corriente.
El campo gravitatorio alrededor de un cuerpo masivo.
En todos los casos, el campo describe cómo actúa una influencia en el espacio sin necesidad de un contacto directo.
La teoría del campo vectorial sustituye la idea de “acción a distancia” por la de campo continuo: no es el objeto el que actúa directamente, sino el campo que existe en el espacio.
Por ejemplo, una carga eléctrica no “empuja” a otra directamente; modifica el espacio a su alrededor creando un campo eléctrico, y otra carga responde a ese campo.
Desde un punto de vista filosófico, la teoría del campo vectorial implica que:
La realidad no está compuesta solo de objetos, sino de estructuras dinámicas.
El espacio no es un vacío pasivo, sino un medio activo de relaciones.
El conocimiento no se centra en cosas aisladas, sino en configuraciones y tensiones.
En este sentido, el campo es una metáfora poderosa de la modernidad científica: lo esencial no es lo visible, sino lo que opera continuamente.
6.4.9.1 El teorema de Helmholtz
Desde Faraday, las leyes de la electricidad y el magnetismo se han expresado en términos de campos eléctricos y magnéticos, E y B. Como ocurre con muchas leyes físicas fundamentales, estas relaciones se formulan de manera más compacta mediante ecuaciones diferenciales. Dado que E y B son campos vectoriales, dichas ecuaciones involucran de forma natural derivadas vectoriales: la divergencia y el rotacional. De hecho, Maxwell logró reducir toda la teoría electromagnética a cuatro ecuaciones, que especifican, respectivamente, la divergencia y el rotacional de E y B. Esta formulación plantea una cuestión matemática profunda y no trivial: ¿hasta qué punto una función vectorial queda determinada por su divergencia y su rotacional? Dicho de otro modo, si se nos proporciona la divergencia de un campo F —que en este contexto puede representar E o B— como una función escalar específica D, ¿qué grado de información poseemos realmente sobre el campo mismo?
 2.07.44p.m.png)
Y el rotacional de F es una función vectorial específica C,
 3.03.30p.m.png)
Para la consistencia, C debe ser sin divergencia,
 3.05.28p.m.png)
Como la divergencia de un rotor es simple cero, ¿puedes entonces determinar la función F? No del todo. En el electromagnetismo normalmente se requiere que los campos vayan a cero “en el infinito” (lejos de todas las cargas). Con esa información adicional, el teorema de Helmholtz garantiza que el campo está determinado de forma única por su divergencia y rotación.
El teorema de Helmholtz —también llamado teorema de descomposición de Helmholtz— es un resultado central del análisis vectorial y de la física matemática, porque establece que un campo vectorial suficientemente regular queda completamente determinado por dos tipos de información locales: su divergencia y su rotacional, junto con condiciones de frontera apropiadas.
6.4.9.2 Potenciales
Si el rotor de un campo vectorial F se anula en todas partes, entonces F puede escribirse como el gradiente de un potencial escalar V:
 3.15.02p.m.png)
El signo menos es meramente convencional. Esa es la carga esencial del siguiente teorema:
Teorema 1: Campos sin curvación (o irrotacionales). Las siguientes condicionales son equivalentes, es decir, F satisface uno sí y solo si satisface todas las demás:
A)  3.18.38p.m.png) por todas partes.
por todas partes.
B)  3.19.29p.m.png) es independiente del camino de trayectoria, para cualquier punto final.
es independiente del camino de trayectoria, para cualquier punto final.
C)  3.20.33p.m.png) para cualquier lazo cerrado.
para cualquier lazo cerrado.
D) F es el gradiente de alguna función escalar:  3.21.51p.m.png)
El potencial no es único — cualquier constante puede añadirse a V impunemente, ya que esto no afectará su gradiente. Si la divergencia de un campo vectorial F se anula en todas partes, entonces F puede expresarse como el rotacional de un potencial vectorial A:
 3.25.26p.m.png)
Esa es la conclusión principal del siguiente teorema:
Teorema 2: Campos sin divergencia (o solenoides). Las siguientes condiciones son equivalentes:
A) ∇?F=0 por todas partes.
B) ∫F?da es independiente de la superficie, para cualquier línea límite dada.
C)?F?da=0 para cualquier superficie cerrada.
D) F es rotor para cualquier superficie cerrada: F=∇⊗A.
El potencial vectorial no es único: el gradiente de cualquier función escalar puede sumarse a A sin afectar el rotacional, ya que el rotor de un gradiente es cero. A estas alturas ya deberías poder demostrar todas las conexiones en estos teoremas, salvo las que dicen que A), B) o C) implican D). Por cierto, en todos los casos (sea cual sea su rotación o divergencia) un campo vectorial F puede escribirse como el gradiente de un escalar más el rotacional de un vector:
F=-∇V+∇⊗A (siempre)
6.5 El campo eléctrico
El problema fundamental que la electrodinámica busca resolver es el siguiente: dadas algunas cargas eléctricas q1, q2, q3…, llamadas cargas fuente, ¿qué fuerza ejercen sobre otra carga Q, llamada carga de prueba? Las posiciones de las cargas fuente se conocen como funciones del tiempo y se debe calcular la trayectoria de la partícula de prueba. En general, tanto las cargas fuente como la carga de prueba se encuentran en movimiento.
La solución a este problema se facilita mediante el principio de superposición, que establece que la interacción entre dos cargas cualesquiera no se ve afectada en absoluto por la presencia de otras. Esto significa que, para determinar la fuerza sobre Q, primero podemos calcular la fuerza F1 debida únicamente a q1 (ignorando todas las demás); luego calculamos la fuerza F2, debida únicamente a q2; y así sucesivamente. Finalmente, tomamos la suma vectorial de todas estas fuerzas individuales:
F=F1 +F2 +F3 +…
Así, si podemos encontrar la fuerza sobre Q debida a una sola carga fuente q, en principio el problema está resuelto: el resto consiste únicamente en repetir el mismo procedimiento y sumar los resultados. Sin embargo, a primera vista esta simplicidad es engañosa. ¿Por qué no escribir simplemente la fórmula de la fuerza sobre debida a q y dar el problema por concluido? La dificultad reside en que la fuerza sobre Q no depende solo de la distancia que separa a las cargas, sino también de sus velocidades y de la aceleración de la carga fuente q. Además, no importan únicamente la posición, la velocidad y la aceleración actuales de q: las “noticias” electromagnéticas se propagan a la velocidad de la luz, de modo que lo que afecta a Q es el estado que tenía q en un instante anterior, cuando el “mensaje” fue emitido.
Por lo tanto, a pesar de que la pregunta básica ¿Cuál es al fuerza sobre Q debida a q? Es fácil de formular, no conviene afrontar directamente; más bien, iremos por etapas. Mientras tanto, la teoría que desarrollamos permitirá la solución de problemas electromagnéticos más sutiles que nos presentan en un formato simple. Para empezar, consideraremos el caso especial de la electrostática en el que todas las cargas fuente están estacionarias (aunque la carga de prueba puede estar en movimiento).
 7.11.44p.m.png)
Evaluación 8__________
6.6 La ley de Coulomb
¿Cuál es al fuerza sobre una carga de prueba Q debido a una carga de punto único q, que está en reposo a cierta distancia r? La repuesta (basada eón experimentos) la da la ley de Coulomb:
 10.34.40a.m.png)
La constante ∈0 se llama (ridículamente) permisibilidad del espacio libre. En unidades SI, donde la fuerza está en newton N, la distancia en metros m y la caga en coulombs C.
 10.46.46a.m.png)
En palabras, la fuerza es proporcional al producto de las cargas e inversamente proporcional al cuadrado de la distancia de separación. Como siempre, es el vector de separación r (la ubicación de q) a r (la ubicación de Q):
 10.53.44a.m.png)
Donde r es la magnitud y r es su dirección vectorial. La fuerza apunta a lo largo de la línea de q a Q; es repulsiva si q y Q tienen mismo signo de carga, y atractivo si sus signos son opuestos.
La ley de Coulomb y el principio de superposición constituyen la entrada física para la electrostática; el resto, salvo algunas propiedades especiales de la materia, es una elaboración matemática de estas reglas fundamentales.
El campo eléctrico
Si tenemos varias cargas puntales q1, q2…, qn a distancias r1,r2,…,rn de Q, la fuerza total sobre Q es evidentemente:
 11.02.37a.m.png)
o
 11.02.58a.m.png)
Entonces
 11.03.25a.m.png)
La cantidad E es denominada campo eléctrico de la cargas fuentes. Obsérvese que es función de la posición r, porque los vectores de separación r i dependen de la ubicación del punto de campo P. Pero no hace referencia a la prueba de carga Q. El campo eléctrico es una magnitud vectorial que varía de un punto a otro y está determinada por la configuración de las cargas fuente; fisicamente, E(r) es la fuerza por unidad de carga que ejercería sobre una carga de prueba si colocamos una en P.
¿Qué es exactamente un campo eléctrico? He comenzado deliberadamente con lo que podrías llamar la interpretación “mínima” de E, como un paso intermedio en el cálculo de las fuerzas eléctricas. Pero te animo a que pienses en el campo como una entidad física “real”, que llena el espacio alrededor de cargas eléctricas. El propio Maxwell llegó a creer que los campos eléctricos y magnéticos son tensiones y tensiones en un inviable “éter”, y con ella la interpretación mecánica de Maxwell de los campos electromagnéticos. Incluso es posible, aunque engorroso, formular la electrodinámica clásica como una teoría de “acción a distancia” y prescindir por completo del concepto de campo. No puedo decirte, entonces, qué es un campo, solo cómo calcularlo y qué puede hacer por ti una vez que lo tienes.
 7.15.45p.m.png)
6.7 Distribución de carga continua
Nuestra definición del campo eléctrico  11.03.25?a.m.png) asume que la fuente del campo es un conjunto de cargas puntuales discretas qi. Si, en cambio, la carga se distribuye de forma continua en alguna región, la suma se convierte en una integral:
asume que la fuente del campo es un conjunto de cargas puntuales discretas qi. Si, en cambio, la carga se distribuye de forma continua en alguna región, la suma se convierte en una integral:
 9.24.58p.m.png)
Si la carga se distribuye a lo largo de una línea, con carga por unidad de longitud λ, entonces dq= λ dl (donde dl es un elemento de longitud a lo largo de la línea) si la carga se extiende sobre una superficie, con carga por unidad de área σ, entonces dq=σ da’ (donde da’ es un elemento de área sobre una superficie); y si la carga llena una volumen, con carga por unidad de volumen ρ, entonces dq=ρ dτ (donde dτ es un elemento de volumen):
 9.54.19p.m.png)
Así, el campo eléctrico de una carga de línea es:
 9.54.42p.m.png)
Para una carga de superficial,
 9.55.34p.m.png)
Y para un volumen de carga:
 9.56.09p.m.png)
 7.21.06p.m.png)
La ecuación última en sí misma suele denominarse “ley de Coulomb”, porque es un peso muy corto respecto a la original:
Y porque una carga volumétrica es, en cierto sentido, el caso más general y realista, por favor, tomen nota con atención el significado de r en estas fórmulas. Originalmente, en la r i representa el vector desde la carga fuente qi hasta el punto de campo r. Correspondientemente en:
Correspondientemente en:
r es el vector para dq (por lo tanto desde dl’, da’ o dτ’) hasta el punto de campo r^.
r es un vector unitario no constante; su dirección depende del punto fuente r, por lo que no puede tomarse fuera de las integrales. En la práctica, debes trabajar con componentes cartesianos (x^,y^, z^ son constantes y sí salen) incluso si usas coordenadas curvilíneas para realizar la integración.
6.8 Líneas de campo, flujo y ley de Gauss
En principio, hemos terminado con el tema de la electrostática. Las ecuaciones anteriores nos indican cómo calcular el campo eléctrico producido por una distribución de carga y cuál será la fuerza que actúa sobre una carga Q colocada en dicho campo. Desafortunadamente, como habrás descubierto al resolver problemas en este tema, el cálculo de E suele implicar integrales que pueden volverse muy complicadas, incluso para distribuciones de carga razonablemente simples.
Gran parte del resto de la electrostática se dedica, precisamente, a construir una caja de herramientas conceptual y matemática para evitar, o al menos simplificar, estas integrales. Todo comienza con el estudio de la divergencia y el rotor del campo eléctrico E. Calcularemos la divergencia de E directamente a partir de la ecuación:
Pero antes quiero mostrar un enfoque más cualitativo y, quizá, más esclarecedor e intuitivo. Comencemos con el caso más sencillo posible: una carga puntual única q, situada en el origen de E:
 8.20.07p.m.png)
Es decir:
 8.22.29p.m.png)
Para hacerme una “idea” de este campo, podría esbozar algunos vectores representativos, como en la figura (a). Dado que el campo disminuye como 1/r^2, los vectores se acortan a medida que uno se aleja del origen; además, siempre apuntan radialmente hacia afuera. Sin embargo, existe una forma más clara de representar este campo: conectar las flechas y formar líneas de campo (figura b). Podrías pensar que con ello se pierde la información sobre la intensidad del campo, que estaba contenida en la longitud de las flechas. Pero en realidad no es así. La magnitud del campo se indica mediante la densidad de las líneas de campo: es mayor cerca del centro, donde las líneas están más juntas, y menor a grandes distancias, donde aparecen más separadas. En rigor, el diagrama de líneas de campo puede resultar engañoso cuando se dibuja sobre una superficie bidimensional, ya que la densidad de líneas que atraviesan un círculo de radio r es el número total dividido entre la circunferencia, n/2πr, lo cual decrece como 1/r, y no como 1/r^2. Pero si se imagina el modelo en tres dimensiones —como un alfiler del que sobresalen agujas en todas direcciones—, entonces la densidad de líneas es el número total dividido entre el área de una esfera, n/4πr^2, que sí decrece como 1/r^2.
Estos diagramas también resultan muy convenientes para representar campos más complejos. Por supuesto, el número de líneas que se dibujen depende de lo perezoso que seas (y de lo afilado que esté tu lápiz), aunque conviene incluir suficientes para obtener una imagen fiel del campo y, sobre todo, ser consistente: si una carga q tiene ocho líneas, entonces una carga 2q debe tener dieciséis. Además, las líneas deben espaciarse de manera uniforme: emanan de las cargas positivas y terminan en las cargas negativas; no pueden finalizar abruptamente en el vacío, aunque sí pueden extenderse hasta el infinito.
Por último, las líneas de campo nunca pueden cruzarse: en un punto de intersección el campo tendría dos direcciones distintas al mismo tiempo, lo cual es imposible. Con todo esto en mente, es sencillo esbozar el campo de cualquier configuración simple de cargas puntuales: basta comenzar dibujando las líneas en la vecindad de cada carga y luego conectarlas entre sí o prolongarlas hacia el infinito.
 7.24.23p.m.png)
 7.25.36p.m.png)
En este modelo, el flujo de E a través de una superficie S,
 9.25.15p.m.png)
Es una medida del “número de líneas de campo” que atraviesan la superficie S. Lo ponemos entre comillas porque, por supuesto, solo podemos dibujar una muestra representativa de las líneas de campo: el número total sería infinito. Sin embargo, para una muestra dada, el flujo es proporcional al número de líneas trazadas, ya que la intensidad del campo —recordemos— es proporcional a la densidad de líneas de campo (el número por unidad de área). Por tanto, E⋅da es proporcional al número de líneas que atraviesan el área infinitesimal da. El producto escalar identifica el componente de da en la dirección de E, como se indica:
 9.36.25p.m.png)
Es el área en el plano perpendicular a E la que tenemos en mente cuando decimos que la densidad de las líneas de campo es el número por unidad de área. Esto sugiere que el flujo a través de cualquier superficie cerrada es una medida de la carga total contenida en su interior, ya que las líneas de campo que se originan en una carga positiva deben atravesar la superficie o bien terminar en una carga negativa situada dentro de ella (figura a). Por el contrario, una carga situada fuera de la superficie no contribuye al flujo total, puesto que sus líneas de campo entran por un lado y salen por otro, anulándose su efecto neto (figura b). Esta es la esencia de la ley de Gauss. Ahora procedamos a formularla de manera cuantitativa.
 9.45.17p.m.png)
Al ciencia y su capacidad para convertir abstracciones matemáticas en Imag6 pensables. Las líneas de campo no existen en sentido ontológico —no son “cosas” en el espacio—, pero existen plenamente como instrumentos de comprensión. Son una gramática visual que traduce leyes invisibles en formas intuitivas. Hay aquí una lección pedagógica y filosófica a la vez: toda representación implica una renuncia parcial, pero una buena representación sabe qué sacrificar y qué preservar. El paso de flechas a líneas no empobrece el contenido físico; lo redistribuye, desplazando la información desde la longitud hacia la densidad, desde el objeto aislado hacia la estructura global. La advertencia sobre el engaño de la bidimensionalidad es especialmente valiosa: recuerda que nuestras intuiciones gráficas siempre operan bajo supuestos tácitos. Aprender física es también aprender a desconfiar con elegancia de los dibujos, a ver en ellos no la realidad misma, sino una puerta de entrada cuidadosamente construida hacia ella.
Este pasaje muestra con particular claridad cómo la física media entre la imagen y el símbolo. Las “líneas de campo” son una ficción útil; el flujo, en cambio, es una magnitud precisa. El texto logra tender un puente elegante entre ambas, justificando por qué una construcción visual puede sostener una definición matemática rigurosa sin caer en el engaño. La insistencia en las comillas no es trivial: recuerda al lector que comprender no siempre significa literalizar. Aquí, el producto escalar actúa como traductor silencioso entre geometría y magnitud física, seleccionando exactamente aquello que contribuye al flujo y descartando lo irrelevante. Es un gesto de economía conceptual que refleja una verdad más amplia: la naturaleza no suma todo, solo lo que cuenta. En ese sentido, esta narrativa enseña algo más que electromagnetismo: enseña una forma de pensar. Ver el mundo como un conjunto de interacciones proyectadas, medidas y orientadas es, al mismo tiempo, un acto matemático y una disciplina intelectual.
En el caso de una carga puntual q en el origen, el flujo de E a través de una superficie esférica de radio r es:
 9.52.37p.m.png)
Observa que el radio de la esfera se cancela, porque mientras la superficie sube como r^2, el campo baja como 1/r^2, por lo que el producto es constante. En términos de la imagen de la líneas de campo pasan por cualquier esfera centrada en el origen, independientemente de su tamaño. De hecho, no tenía por qué ser una esfera: cualquier superficie cerrada, sea cual sea su forma, estaría atravesada por el mismo número de líneas de campo. Evidentemente, el flujo a través de cualquier superficie que encierra la carga es q/∈0 . Ahora supongamos que en lugar de una sola carga en el origen, tenemos un montón de cargas dispersas. Según el principio de superposición, el campo total es la suma vectorial de todos los campos individuales:
 12.19.33p.m.png)
El flujo a través de una superficie que los encierra a todos es:
 12.22.45p.m.png)
Para cualquier superficie cerrada, entonces:
 12.23.39p.m.png)
Donde Qenc es la carga total encerrada dentro de la superficie. Esta es la afirmación constitutiva de la Ley de Gauss. Aunque no contiene información que no estuviera ya presente en la Ley de Coulomb más el principio de superposición, es de un poder casi mágico. Observa que todo depende del carácter 1/r^2 de la ley de Coulomb; sin eso, la cancelación crucial de la rs en la ecuación
No ocurriría y el flujo total de E dependería de la superficie elegida, no solo de la carga total contenida. Otras fuerzas 1/r^2 (pienso especialmente en la ley de la gravitación universal de Newton) obedecería las “leyes de Gauss” propias, y las aplicaciones que desarrollamos aquí se trasladan directamente. Tal y como está la ley de Gauss es una ecuación integral, pero podemos convertirla fácilmente en una diferencial aplicando el teorema de divergencia:
 5.10.20p.m.png)
Reescribiendo Qenc en términos de al densidad de carga ρ, tenemos:
 5.11.37p.m.png)
Así, la ley de Gauss se convierte en:
 5.12.32p.m.png)
Y dado que esto se cumple para cualquier volumen, los integrantes deben ser iguales:
 5.13.38p.m.png)
Esta ecuación transmite la ley de Gauss en forma diferencial. La versión diferencial vectorial es más ordenada, pero la forma integral tiene la ventaja de que acomoda cargas puntuales, lineales y superficiales de forma más natural.
6.9 El divergente de E
Volvamos atrás y calculemos la divergencia de E directamente desde:
 5.17.46p.m.png)
Originalmente la integral era sobre el volumen ocupado por la carga, pero bien podría extenderla a todo el espacio, ya que ρ=0 en la región exterior de todos modos. Observando que la dependencia de r está contenida en r= r- r, tenemos:
 5.22.43p.m.png)
Esta es precisamente la divergencia que calculamos en:
 5.23.39p.m.png)
Así que:
 5.24.29p.m.png)
Que es la Ley de Gauss en forma diferencial. Para recuperar la forma integral, ejecutamos el argumento anterior en sentido inverso: integramos sobre un volumen el teorema de divergencia:
 5.26.10p.m.png)
6.10 El rotor de E
Calcularemos el rotacional de E, como hice con la divergencia, estudiando primero la configuración más simple posible: una carga puntual en origen, en este caso:
 5.30.35p.m.png)
 5.30.52p.m.png)
Ahora, una mirada a la figura siguiente, debería convencerte de que el rotacional de este campo debe ser cero, pero supongo que deberíamos idear algo un poco más riguroso que eso. ¿Y si calculamos la integral de línea de este campo desde algún punto a hasta otro punto b como la figura de arriba?
 3.11.50p.m.png)
 3.18.19p.m.png)
En coordenadas esféricas:  3.19.00p.m.png) esto es:
esto es:
 3.19.41p.m.png)
Por lo tanto:
 3.20.58p.m.png)
Donde ra es la distancia desde el origen hasta el punto a y rb es la distancia a b. La integral alrededor de un camino cerrado es evidentemente cero (para ra=rb ).
 3.24.39p.m.png)
Y por tanto, aplicando el teorema de Stokes y señalando que la ecuación anterior se aplica a cualquier camino cerrado,
 3.26.29p.m.png)
Ahora, he demostrado las ecuaciones dos anteriores, solo para el campo de una carga puntual en el origen, pero estos resultados no hacen referencia a lo que, al fin y al cabo, es una elección perfectamente arbitraria de coordenadas; se mantienen sin importar dónde esté la carga. Además, si tenemos muchas cargas, el principio de superposición dice que el campo total es al suma vectorial de sis campos individuales:
 3.29.57p.m.png)
Así que
 3.31.00p.m.png)
Por eso, las ecuaciones anteriores se cumplen para cualquier distribución de carga (estética) que sea.
Evaluación 9__________
6.11 Potencial eléctrico
El potencial eléctrico E no es una función vectorial cualquiera. Es un tipo muy especial de función vectorial: cuyo rotacional es cero. El vector  5.22.10p.m.png) , por ejemplo, no podría ser un campo electrostático; ningún conjunto de cargas, independiente de su tamaño y posición, podría producir jamás un campo así. Vamos a explotar esta propiedad especial de los campos eléctricos para reducir un problema vectorial (encontrar E) a un problema escolar mucho más sencillo. El teorema de Helmholtz afirma que cualquier vector cuyo rotacional se acero es igual al gradiente de algún escalar. Lo que vamos hacer ahora equivale a una prueba de esa afirmación, en el contexto de la electrostática.
, por ejemplo, no podría ser un campo electrostático; ningún conjunto de cargas, independiente de su tamaño y posición, podría producir jamás un campo así. Vamos a explotar esta propiedad especial de los campos eléctricos para reducir un problema vectorial (encontrar E) a un problema escolar mucho más sencillo. El teorema de Helmholtz afirma que cualquier vector cuyo rotacional se acero es igual al gradiente de algún escalar. Lo que vamos hacer ahora equivale a una prueba de esa afirmación, en el contexto de la electrostática.
Como ∇⊗E=0, la integral de línea de E al rededor de cualquier lazo cerrado es cero (lo que se deduce del teorema de Stokes). Porque ?E?dl=0, la integral de línea de E desde el punto a hasta el punto b es la misma para todos los caminos (de lo contrario, podrías salir por el camino (i) y volver por el camino (ii) de al siguiente figura, y obtener ?E?dl=0). Como las integral de línea es independiente del camino de trayectoria, podemos definir una función:
 5.36.46p.m.png)
Aquí O es un punto de referencia estándar sobre el que hemos acortado de antemano; V entonces depende únicamente del punto r. Se llama potencial eléctrico. La diferencia de potencial entre dos puntos a y b es:
 5.39.39p.m.png) Ec. A
Ec. A
Ahora, el teorema fundamental para gradientes establece que:
 5.40.18p.m.png)
Así que:
 5.40.43p.m.png)
Dado que, finalmente, esto es cierto para cualquier punto a y b, las integrales deben ser iguales:
 5.42.07p.m.png) Ec. B
Ec. B
La ecuación A es la versión diferencial de la ecuación B; dice que el campo eléctrico es el gradiente de un potencial escalar, que es lo que pretendíamos demostrar.
Observa el papel sutil pero crucial que juega la independencia de caminos (o, equivalentemente, el hecho de que ∇⊗E=0) en este argumento. Si la integral de línea de E dependiera del camino tomado, entonces la “definición” de V,
 5.46.45p.m.png) sería un disparate. No definiría una función, ya que cambiar el camino alteraría el valor de V(r). Por cierto, no dejes que el signo menos en la ecuación B te distraiga, se mantiene desde la ecuación A y es en gran medida una cuestión de convención.
sería un disparate. No definiría una función, ya que cambiar el camino alteraría el valor de V(r). Por cierto, no dejes que el signo menos en la ecuación B te distraiga, se mantiene desde la ecuación A y es en gran medida una cuestión de convención.
Comentario sobre potencial
El término “potencial” es un nombre sesgado, pues inevitablemente evoca la noción de energía potencial. Esta asociación resulta especialmente insidiosa, ya que, aunque existe una conexión formal entre “potencial” y “energía potencial”, no se trata de conceptos equivalentes. Siento que sea imposible escapar por completo de esta palabra; lo mejor que podemos hacer es insistir, de una vez por todas, en que “potencial” y “energía potencial” son términos conceptualmente distintos y que, con toda justicia, deberían llevar nombres diferentes. Por cierto, una región —típicamente una superficie— sobre la cual el potencial es constante se denomina superficie equipotencial.
Una de las principales ventajas de esta formulación reside en su economía conceptual. Si se conoce el potencial V, puede obtenerse de manera inmediata el campo eléctrico mediante la relación E=−∇V. Este hecho resulta verdaderamente notable si se reflexiona con detenimiento, pues E es una magnitud vectorial, con tres componentes independientes a primera vista, mientras que V es una magnitud escalar, definida por una sola función. ¿Cómo es posible que una única función contenga toda la información que, en apariencia, requieren tres funciones independientes?
La respuesta es que los tres componentes del campo eléctrico no son tan independientes como parecen. En realidad, se encuentran explícitamente relacionados por la misma condición fundamental de la que partimos: ∇×E=0. Esta restricción impone una estructura interna al campo, de modo que su comportamiento completo puede derivarse de un potencial escalar único. En cuanto a los componentes individuales, su interdependencia emerge directamente de esta condición.
 12.59.40p.m.png)
Estos nos lleva de nuevo a nuestra observación al principio: E es un tipo muy especial de vector. Lo que hace la formulación potencial es explorar esta característica al máximo provecho, reduciendo un problema vectorial a uno escalar, en el que no hay necesidad de complicarse con los componentes.
El punto O de referencia. Existe una ambigüedad esencial en la definición de potencial, ya que la elección del punto de referencia O es arbitraria. Cambiar los puntos de referencia equivale a añadir una constante k al potencial:
 1.24.14p.m.png)
Donde K es la integral de línea de E desde el antiguo punto de referencia O hasta el nuevo O. Por supuesto, añadir una constante a V no afectará la diferencia de potencial entre dos puntos:
 3.30.36p.m.png)
Ya que las K se cancelan. En realidad, ya estaba claro desde la ecuación:
 3.31.45p.m.png)
Que la diferencia de potencial es independiente de O; porque puede escribirse como la integral de línea de E de a a b, sin mención de O. Tampoco la ambigüedad afecta al gradiente de V:
 3.33.51p.m.png)
Dado que la derivada de una constante es nula, todos aquellos potenciales V que difieren únicamente en la elección del punto de referencia corresponden al mismo campo eléctrico E. En consecuencia, el potencial eléctrico, considerado de manera absoluta, carece de significado físico intrínseco: en cualquier punto del espacio su valor puede ajustarse arbitrariamente mediante una redefinición adecuada del origen del potencial.
En este sentido, el potencial eléctrico es análogo al concepto de altitud en geografía física. Si se pregunta por la altura de una ciudad como Morelia, lo habitual es responder en términos de su altitud sobre el nivel medio del mar, no porque dicho nivel posea un privilegio ontológico, sino porque constituye una referencia convencional, históricamente establecida y operativamente conveniente. Sin embargo, podríamos acordar medir la altitud respecto al nivel del lago de Pátzcuaro o cualquier otro plano de referencia arbitrario. Esta elección introduciría un desplazamiento constante en todas las mediciones, sin alterar en absoluto ningún fenómeno físico observable.
La única magnitud dotada de significado físico objetivo es, por tanto, la diferencia de potencial entre dos puntos, del mismo modo que lo es la diferencia de altitud entre dos ubicaciones. Dicha diferencia es independiente de la elección del nivel de referencia y es la que determina efectos físicos medibles, como el trabajo realizado por el campo eléctrico sobre una carga de prueba.
Dicho esto, existe un punto de referencia “natural” en electrostática —análogo al nivel del mar en el caso de la altitud— que suele adoptarse por conveniencia teórica: un punto situado a una distancia infinita de las fuentes de carga. En la práctica, se establece el potencial nulo en el infinito, lo que se interpreta operacionalmente como la tierra física. Elegir este punto de referencia equivale a imponer la condición de frontera V(∞)=0.
No obstante, debe advertirse que esta convención deja de ser válida en una circunstancia particular: cuando la distribución de carga se extiende hasta el infinito. En tales casos, el potencial deja de estar bien definido, manifestándose matemáticamente en una divergencia. Un ejemplo paradigmático es el campo eléctrico generado por un plano infinito con densidad de carga uniforme es  4.32.23p.m.png) , para el cual el campo es constante. Al intentar definir el potencial integrando el campo, se obtiene una expresión que crece linealmente con la distancia al plano, lo que conduce a una divergencia del potencial absoluto y hace imposible fijar z un cero en el infinito.
, para el cual el campo es constante. Al intentar definir el potencial integrando el campo, se obtiene una expresión que crece linealmente con la distancia al plano, lo que conduce a una divergencia del potencial absoluto y hace imposible fijar z un cero en el infinito.
 4.36.17p.m.png)
El remedio consiste simplemente en elegir otro punto de referencia. Esta dificultad aparece únicamente en construcciones idealizadas propias de los libros de texto; en la experiencia física real no existe una distribución de carga que se extienda literalmente hasta el infinito. En consecuencia, siempre es posible, en sistemas físicamente realizables, utilizar el infinito como punto de referencia para fijar el cero del potencial sin incurrir en inconsistencias matemáticas o conceptuales. El potencial eléctrico obedece al principio de superposición. En su formulación original, dicho principio se refiere a la fuerza ejercida sobre una carga de prueba Q. Establece que la fuerza total que actúa sobre Q es la suma vectorial de las fuerzas debidas individualmente a cada una de las cargas fuente. Es decir, si un conjunto de cargas {qi} produce fuerzas Fi sobre la carga de prueba, entonces la fuerza total es:
 4.47.36p.m.png)
Dado que la fuerza eléctrica es lineal en el campo eléctrico, este principio se traduce directamente al campo:
 4.48.19p.m.png)
donde Ei es el campo producido por la carga qi considerada aisladamente.
Integrando desde el punto de vista de referencia común a r, deduce que el potencial también satisface tal principio:
 4.50.39p.m.png)
Puesto que el campo eléctrico está relacionado con el potencial mediante E=−∇V, la linealidad del operador gradiente implica que el potencial eléctrico también satisface el principio de superposición. En consecuencia, el potencial total generado por una distribución de cargas es simplemente la suma escalar de los potenciales producidos por cada carga individual:
 4.51.51p.m.png)
Este resultado es particularmente significativo, ya que, a diferencia del campo eléctrico —una magnitud vectorial definida por tres componentes independientes—, el potencial eléctrico es una cantidad escalar. Esta diferencia no es meramente formal: reduce de manera sustantiva la complejidad analítica de problemas con múltiples fuentes, en especial cuando el sistema exhibe simetrías geométricas (esférica, cilíndrica o planar). En tales casos, el potencial puede determinarse mediante argumentos de simetría y superposición, evitando el tratamiento directo de campos vectoriales cuya estructura espacial suele ser más intrincada.
Desde un punto de vista pedagógico y teórico, el potencial actúa como una función generatriz del campo: toda la información física relevante del campo electrostático está codificada en una sola función escalar, siempre que se satisfaga la condición de irrotacionalidad
 4.58.28p.m.png)
Esta observación refuerza la idea de que el potencial no es un artificio matemático secundario, sino una representación profundamente ligada a la estructura interna de la teoría.
Unidades del potencial eléctrica. En el Sistema Internacional de Unidades, la fuerza se mide en newtons (N) y la carga eléctrica en coulombs (C). En consecuencia, el campo eléctrico, definido como fuerza por unidad de carga,
 4.59.30p.m.png)
tiene unidades de newtons por coulomb (N/C). El potencial eléctrico se define, de manera operacional, como el trabajo realizado por el campo eléctrico por unidad de carga al desplazar una carga de prueba entre dos puntos. Dado que el trabajo se mide en joules (J), el potencial tiene unidades de:
 5.00.26p.m.png)
unidad que recibe el nombre de voltio V en honor a Alessandro Volta. Así que:
 5.01.09p.m.png)
Esta definición hace explícita la interpretación energética del potencial: un voltio representa la cantidad de energía transferida por el campo eléctrico a una carga de un coulomb al desplazarse entre dos puntos con una diferencia de potencial de un voltio.
6.12 Ecuación Poisson y de Laplace
La ecuación de Poisson y la ecuación de Laplace en el campo eléctrico puede escribirse como el gradiente eléctrico de un potencial escalar,
 3.57.55p.m.png)
Surge la siguiente pregunta: ¿qué son las divergencias y el rotacional de E y V?
 4.01.32p.m.png)
y
 4.01.59p.m.png)
Bueno  4.03.54p.m.png) así que, aparte de ese signo menos persistente, la divergencia de E es el laplaceano de V. La Ley de Gauss, entonces, dice:
así que, aparte de ese signo menos persistente, la divergencia de E es el laplaceano de V. La Ley de Gauss, entonces, dice:
 4.06.12p.m.png)
Esto se conoce como la ecuación de Poisson. En regiones donde no hay carga, por lo que p=0, la ecuación de Poisson se reduce a la ecuación de Laplace:
 4.16.05p.m.png)
Para el rotacional:
 4.17.24p.m.png)
Pero eso no es condición en V; el rotacional del gradiente es siempre cero. Por supuesto, usamos la ley de rotación para mostrar que E podía expresarse como el gradiente de un escalar, así que no es de extrañar que esto funcione:
permite que
a cambio garantiza:
solo se necesita una ecuación diferencial (la de Poisson) para determinar V, porque V es un escalar, para E necesitábamos dos pasos, la divergencia y el rotor.
Definir V en términos de E.
6.13 Potencial de una distribución de carga
Definimos V en términos
 12.40.33p.m.png)
Normalmente, sin embargo, lo que buscamos es el campo eléctrico E (si ya conociéramos E, tendría poco sentido calcular el potencial V). La idea central es que, en muchos casos, resulta más sencillo determinar primero V y posteriormente obtener E tomando su gradiente. En consecuencia, el problema típico consiste en conocer la distribución de carga —es decir, la densidad de carga ρ— y a partir de ella encontrar el potencial V. La ecuación de Poisson establece una relación directa entre V y ρ, pero presenta una dificultad práctica: no está formulada para determinar V conociendo ρ, sino que, en cierto sentido, opera en la dirección inversa. Por ello, el objetivo consiste en invertir la ecuación de Poisson. Este será el programa a seguir, aunque lo abordaremos de manera indirecta, comenzando —como es habitual— con el caso elemental de una carga puntual situada en el origen.
 3.43.53p.m.png)
Estableciendo el punto de referencia en el infinito, el potencial de una carga:
 3.45.58p.m.png)
Aquí se aprecia la ventaja de utilizar el infinito como punto de referencia: eliminar el límite inferior de la integral. Obsérvese el signo de V; presumiblemente, se eligió el signo negativo convencional en su definición para que el potencial asociado a una carga positiva resultara positivo. Conviene recordar que las regiones de carga positiva constituyen simas de potencial, mientras que las regiones de carga negativa forman valles potenciales, y que el campo eléctrico siempre apunta cuesta abajo, es decir, desde valores mayores de potencial hacia valores menores.
En general, el potencial eléctrico producido por una carga puntual q es:
 1.23.13p.m.png)
Donde, como siempre, es la distancia de q a r. Invocando el principio de superposición, entonces, el potencial de una colección de cargas es:
 1.27.37p.m.png)
 1.27.50p.m.png)
O, para una distribución continua:
 1.28.43p.m.png)
En particular para una carga volumétrica, es:
 1.29.40p.m.png)
Esta es la ecuación que buscamos, que nos indica cómo calcular V cuando sabemos p; es, si se quiere, la solución de al ecuación de Poisson, para una distribución de carga localizada.
 1.31.18p.m.png)
El punto principal a notar es que el molesto vector unitario r^ha desaparecido, así que no debemos preocuparnos por los componentes. Los potenciales de las cargas lineales y superficiales son:
 1.33.54p.m.png)
 1.34.08p.m.png)
Evaluación 10__________
6.13 Condiciones de contorno
En un problema típico de electrostática se proporciona una distribución de carga fuente ρ, y el objetivo es determinar el campo eléctrico E que dicha distribución produce. Salvo en aquellos casos en que la simetría del problema permite una solución directa mediante la ley de Gauss, suele ser más conveniente calcular primero el potencial eléctrico V como paso intermedio. Estas son las tres magnitudes fundamentales de la electrostática: la densidad de carga ρ, el campo eléctrico E y el potencial eléctrico V. A lo largo de la discusión hemos derivado las seis ecuaciones que las relacionan entre sí. Dichas relaciones pueden resumirse de manera compacta y sistemática como sigue.
 2.44.31p.m.png)
Comenzamos con solo dos observaciones experimentales fundamentales:
- El principio de superposición, una regla que se aplica a todas las fuerzas electromagnéticas, y
- La ley de Coulomb, la ley básica de la electrostática.
A partir de estos dos hechos, todo el edificio de la electrostática se despliega de manera sistemática. Quizá hayas notado que el campo eléctrico presenta una discontinuidad cuando se cruza una superficie que porta una densidad de carga superficial σ. De hecho, es sencillo determinar la magnitud exacta de ese salto en el campo. Para ello, consideremos una “pastilla” gaussiana extremadamente delgada, cuya superficie plana atraviesa la capa cargada y sobresale apenas por ambos lados de la frontera.
 7.29.06p.m.png)
La ley de Gauss dice que:
 2.53.41p.m.png)
Donde A es el área de la tapa del búnker. Si σ varía de un punto a otro o la superficie es curva, debemos elegir que A sea extremadamente pequeña. Ahora, los laterales del búnker no aportan nada al flujo, en el límite cuando el grosor llega a cero, así que nos quedamos con:
 2.56.13p.m.png)
Donde E⊥ arriba derrota el componente de E que es perpendicular a la superficie inmeditamente encima, y E⊥ abajo es la misma, solo que justo por debajo de la superficie. Para mantener consistencia, dejamos que “hacia arriba” sea la dirección positiva para ambos. Conclusión, el componente normal de E es discontinuo por una unidad de cantidad σ /0 en cualquier frontera.
En particular, donde no hay carga superficial. E⊥ es continua, como por ejemplo en al superficie de una esfera sólida de carga uniforme:
El componente tangencial de E, en cambio, es sempre continuo. Porque si aplicamos la ecuación:
 3.03.47p.m.png)
Al lazo rectangular fino de la figura, los extremos no dan nada (?→0) los dos lados dan, por lo que
 3.15.16p.m.png)
Donde E representa las componentes de E paralelas a las superficie. Las condiciones de contorno sobre E pueden combinarse en una sola fórmula:
 3.17.05p.m.png)
 3.04.46p.m.png)
El vector n^ es un vector unitario perpendicular a la superficie, apuntando de “abajo” a “arriba”. El potencial por su parte, es continuo a través de cualquier frontera, ya que:
 3.19.11p.m.png)
A medida que la longitud del camino se reduce a cero, también lo hace la integral:
 3.20.06p.m.png)
Sin embargo, el gradiente de V hereda la discontinuidad de E; dado que E=-∇V, la ecuación implica que:
 3.22.22p.m.png)
O más convenientemente:
 3.23.10p.m.png)
Por tanto
 3.23.35p.m.png)
Denota la derivada parcial de V (es decir, la tasa de cambio en la dirección perpendicular a la superficie). Tenga en cuenta que estas condiciones de frontera relacionan los campos y potenciales justo por encima y por debajo de la superficie. Por ejemplo, las derivadas en:
 3.26.22p.m.png)
Son valores límite a medida que nos acercamos a la superficie desde ambos lados.
6.14 Trabajo y energía en electrostática
Supongamos que tienes una configuración estacionaria de cargas fuente y quieres mover una carga de prueba Q del punto a al punto b.
 1.53.43p.m.png)
Pregunta: ¿cuánto trabajo tendrá que hacer? En cualquier punto del camino, la fuerza eléctrica sobre Q es F=QE; la fuerza que debes ejercer, en posición a esta fuerza, es -QE. Si el signo molesta, piense en levantar un ladrillo: la gravedad ejerce una fuerza mg hacia abajo, pero usted ejerce una fuerza mg hacia arriba. Por su puesto, podrías aplicar una fuerza aún mayor: entonces el ladrillo aceleraría y parte de tu esfuerzo se “desperdiciaría” generando energía cinética. Lo que nos interesa aquí es la fuerza mínima que debes ejercer para hacer el trabajo. El trabajo que haces es por tanto:
 2.54.56p.m.png)
Observar que la respuesta es independiente del camino que tomes de a a b; en mecánica, entonces, llamaríamos a la fuerza electrostática “conservativa”. Dividiendo por Q, tenemos:
 2.57.15p.m.png)
En palabras, la diferencia ese potencial entre los puntos a y b es igual al trabajo que requiere, por unidad de carga, para transportar una partícula de a a b. En particular, si quieres traer Q desde lejos y ponerla en el punto r, el trabajo que debes hacer es:
 2.59.33p.m.png)
Así que, si has puesto el punto de referencia en el infinito:
 3.00.11p.m.png)
En este sentido, el potencial es la energía potencial (el trabajo necesario para crear el sistema) por unidad de carga (así como el campo es la fuerza por unidad de carga).
6.15 La energía de una distribución de carga
¿Cuánto trabajo haría falta para montar toda una colección de cargas puntuales? Imagine traer las cargas, una a una, desde muy lejos.
 3.51.06p.m.png)
La primera carga, q1, no refiere trabajo, ya que aún no hay campo contra el que luchar. Ahora traer la q2. Según esto nos costará q2V1(r2), donde V1 es el potencial debido a q1, y r2 es donde ponemos q2:
 3.53.27p.m.png)
r12 es la distancia entre q1 y q2 una vez que están en posición. A medida que muevas cada carga, aclárala su posición final para que no se mueva cuando entre la siguiente carga. Ahora traigamos la carga q3, esto requiere trabajo q3V1,2(r3), donde V1,2 es el potencial por las dos cargas q1, y q2, es decir:
 7.17.57p.m.png) Así:
Así:
 7.18.28p.m.png)
De manera similar, el trabajo extra para introducir en cuarta carga q4 será:
 7.19.51p.m.png)
El trabajo total necesario para ensamblar las primeras cuatro cargas, entonces:
 7.20.57p.m.png)
Observar una generalización: tomar el producto de cada par de cargas, dividido por su distancia de separación y sumar todo:
 7.22.23p.m.png)
La condición j > i es recordarnos no contar dos veces los mismos par de cargas. Una forma más sencilla de lograrlo es contar intencionalmente cada par dos veces y luego dividir entre 2:
 7.26.01p.m.png)
Aún así, debemos excluir i=j, por supuesto. Observa que en esta forma la repuesta claramente no depende del orden en que se ensamblan las cargas, ya que cada par aparece en la suma. Por último, saquemos el factor qi:
 7.29.01p.m.png)
El término entre paréntesis es el potencial en la posición del qi, debido a todas las demás cargas — todas ellas, ahora, no solo las que estuvieron presentes en algún momentos durante en algún momento durante la asamblea. Así:
 7.32.12p.m.png)
Ese es el trabajo que se necesita para ensamblar una configuración de cargas puntuales; también es la cantidad de trabajo que recuperarías si desmantelaras el sistema. Mientras tanto, representa la energía almacenada en la configuración (energía “potencial”, si insistes, aunque por razones obvias preferimos evitar esa palabra en este contexto).
6.16 La energía de una distribución continua de carga
Para una densidad de carga volumétrica ρ, se convierte en la ecuación:
 10.17.14p.m.png)
Las integrales correspondientes para cargas de línea y superficie serían:
 10.18.17p.m.png)
 10.18.32p.m.png)
Hay una forma encantadora de reescribir este resultado, en la que ρ y V se eliminan en favor de E. Primero, utiliza la ley de Gauss para expresar ρ en términos de E:
 10.21.01p.m.png)
Ahora utiliza la integración por partes para transferir la derivada de E a V:
 10.22.03p.m.png)
Pero;
 10.22.42p.m.png)
 10.23.08p.m.png)
Pero, ¿sobre qué volumen V estamos integrando? Volvamos a la fórmula con la que empezamos:
Por su derivación, está claro que debemos integrar sobre la región donde se encuentra la carga. Pero en realidad, cualquier volumen mayor servirá igual de bien: el territorio “extra” que añadamos no aportará nada a la integral, ya que ρ = 0 ahí fuera. Con esto en mente, volvamos a la ecuación:
¿Qué ocurre aquí, al aumentar el volumen más allá del mínimo necesario para atrapar toda la carga? Bueno, la integral de E2 solo puede aumentar (el integrando es positivo); evidentemente la integral de superficie debe disminuir correspondientes, para mantener la suma intacta. De hecho, a grandes distancias de la carga, E va como 1/r2 y V como 1/r, mientras que el área superficial crece r2; hablando a grandes rasgos, entonces, la integral superficial baja como 1/r. Por favor, comprenda: la ecuación:
Le da la energía W correcta, sea cual el volumen que uses (siempre que encierra toda la carga) pero la contribución de al integral de volumen aumenta, y la de la integral de superficie disminuye, a medida que tomamos volúmenes cada vez mayores. En particular, ¿por qué no integrar en el espacio total? Entonces la integral superficial se vuelve cero, y nos quedamos con:
 10.38.00p.m.png) Para todo el espacio.
Para todo el espacio.
Evaluación 11__________
6.17 Energía electrostática
i) Una desconcertante “inconsistencia “. La ecuación:
 10.42.12p.m.png) implica claramente que la energía de una distribución de carga estacionaria es siempre positiva. Por otro lado, la ecuación:
implica claramente que la energía de una distribución de carga estacionaria es siempre positiva. Por otro lado, la ecuación:
 10.43.36p.m.png) puede ser positiva o negativa. Por ejemplo, la energía de dos cargas iguales pero opuestas a una distancia r es:
puede ser positiva o negativa. Por ejemplo, la energía de dos cargas iguales pero opuestas a una distancia r es:
 10.45.13p.m.png)
¿Qué ha salido mal? ¿Qué ecuación es correcta? La respuesta es que son correctas, pero abordan el trabajo necesario para realizar lascarías puntuales en primer lugar; empezamos con cargas puntuales y simplemente encontramos el trabajo necesario para unirlas. Esta es una estrategia sensata, ya que la ecuación:
Implica que la energía de una carga puntual es en realidad infinita.
 10.48.31p.m.png)
La ecuación:
es más completa, en el sentido de que te indica la energía total almacenada en una configuración de carga, pero la ecuación:
Es más adecuada cuando se trata de cargas puntuales, porque preferimos, con razón, omitir las cargas puntuales. En la práctica, al fin y al cabo, las cargas puntuales —los electrones, por ejemplo— no nos son dadas como ya hechas; todo lo que hacemos es moverlas. Como no las ensamblamos ni podemos desmontarlas, no importa cuánto trabajo implique el proceso. Aun así, la energía infinita asociada a una carga puntual es una fuente recurrente de incomodidad para la teoría electromagnética, que afecta tanto a su formulación clásica como a la cuántica.
Ahora, puede que te preguntes dónde se coló esa inconsistencia en una derivación aparentemente irrefutable. El “fallo” está en la ecuación:
 11.15.28p.m.png)
 11.15.42p.m.png)
En la primera, V(ri) representa el potencial debido a todas las demás cargas pero no a qi, mientras que en este último, V(r) es el potencial completo. Para una distribución continua, no hay distinción, ya que la cantidad de carga justo en el punto r es nula y su contribución al potencial es cero. Pero en presencia de cargas puntuales, será mejor que nos quedemos con la ecuación:
 11.19.32p.m.png)
ii) ¿Dónde se almacena la energía? Las ecuaciones:
 11.20.49p.m.png)
 11.20.59p.m.png)
Ofrecen dos formas diferentes de calcular lo mismo. La primera es una integral sobre la distribución de cargas; la segunda, una integral sobre el campo. Ambas pueden involucrar regiones completamente diferentes. Por ejemplo, en el caso de una capa esférica, la carga está confinada a la superficie, mientras que el campo eléctrico se extiende por todo el espacio exterior a dicha superficie. ¿Dónde está la energía, entonces? ¿Se almacena en el campo, como sugiere la ecuación:
 11.25.24p.m.png) o se almacena en la carga, como implica la ecuación:
o se almacena en la carga, como implica la ecuación:
 11.26.09p.m.png) ? En esta etapa esta es simplemente una pregunta sin respuesta: podemos decir cuál es la energía total y puedo proporcionarte varias formas diferentes de calcularla, pero no tiene sentido preocuparse por dónde está ubicada la energía. En el contexto de la teoría de radiación es útil y en relatividad general es esencial considerar la energía almacenada en el campo, con una densidad:
? En esta etapa esta es simplemente una pregunta sin respuesta: podemos decir cuál es la energía total y puedo proporcionarte varias formas diferentes de calcularla, pero no tiene sentido preocuparse por dónde está ubicada la energía. En el contexto de la teoría de radiación es útil y en relatividad general es esencial considerar la energía almacenada en el campo, con una densidad:
 11.29.50p.m.png) energía por unidad de volumen.
energía por unidad de volumen.
Pero en electrostática se podría decir perfectamente que se almacena enmascaramiento al carga, con una densidad de 1/2( ρV). La diferencia es puramente una cuestión de contabilidad.
iii) El principio de superposición. Dado que la energía electrostática es cuadrática en los campos, no satisface un principio de superposición. La energía de un sistema compuesto no es simplemente la suma de las energías de sus partes consideradas por separado; aparecen, además, términos cruzados. Aunque los campos eléctricos sí obedecen el principio de superposición, la energía asociada a ellos no lo hace. Esta asimetría conceptual revela que la linealidad de las ecuaciones de campo no se traslada automáticamente a las magnitudes derivadas. Los “términos cruzados” no son una complicación matemática accidental, sino la huella de una realidad física relacional: la energía depende de la coexistencia de configuraciones, no de entidades aisladas. En ese sentido, la energía electrostática no pertenece a los campos individuales, sino a su interacción.
 6.36.15p.m.png)
Por ejemplo, si duplicas la carga en todas partes, cuadruplicas la energía total.
6.18 Conductores
En un aislante, como el vidrio o el caucho, cada electrón está atado por una correa corta, unido a un átomo concreto. En un conductor metálico, en cambio, uno o más electrones por átomo pueden moverse libremente. En conductores líquidos, como el agua salada, son los iones quienes se desplazan.
Un conductor perfecto tendría un suministro ilimitado de cargas disponibles sin costo energético. En la realidad no existen conductores perfectos, pero los metales se aproximan bastante a ese ideal para la mayoría de los propósitos. De esta definición se deducen inmediatamente las propiedades electrostáticas básicas de los conductores ideales:
i) E=0 dentro de un conductor. ¿Por qué? Porque si hubiera algún campo, esas cargas se moverían, y no sería electrostática. Esto no es una explicación satisfactoria; quizás solo demuestra que no puedes tener electrostática cuando hay conductores presentes. Será mejor que examinemos qué ocurre cuando se introduce un conductos en un campo eléctrico externo E0:
 6.47.26p.m.png)
Inicialmente, el campo empujará cualquier carga positiva libre hacia la derecha y las negativas hacia la izquierda. En la práctica, son las cargas negativas —los electrones— las que se mueven; pero, cuando se desplazan, el lado derecho queda con una carga neta positiva —los núcleos estacionarios—, de modo que, en realidad, no importa qué tipo de carga se acumule: habrá exceso en el lado derecho y déficit en el izquierdo.
Estas cargas inducidas producen su propio campo, E1, que, como puede verse en la figura anterior, apunta en la dirección opuesta a E0. Este es el punto crucial, porque significa que el campo de las cargas inducidas tiende a cancelar el campo original. La carga continuará fluyendo hasta que esta cancelación sea completa: el campo resultante dentro del conductor es entonces exactamente cero. Todo el proceso es prácticamente instantáneo. No se trata de una imposición externa, sino de un equilibrio dinámico que emerge de la propia movilidad de los electrones. El conductor no “bloquea” el campo por resistencia, sino que responde activamente a él. El campo interno desaparece no porque deje de existir el campo externo, sino porque el sistema genera uno propio que lo neutraliza con precisión matemática. Esta cancelación no es aproximada ni gradual en el límite ideal: es exacta.
ii) ρ=0 dentro de un conductor. Esto se deduce de la ley de Gauss:
 9.38.03a.m.png)
Si E es cero, también lo es ρ. Todavía hay carga alrededor, pero exactamente tanto más como menos, así que la densidad neta de carga en el interior es cero.
iii) Cualqueir carga neta reside en la superficie. Es el único sitio que queda.
iv) Un conductor es un equipotencial. Porque si a y b son dos puntos cualesquiera dentro o en la la superficie de un conductor dado;
 9.44.13a.m.png) V(a) =V(b).
V(a) =V(b).
v) E es perpendicular a la superficie, justo fuera de un conductor. De lo contrario, como en i), la carga fluirá inmediatamente alrededor de la superficie hasta que elimine el componente tangencial. Perpendicular a la superficie la carga no puede fluir, por supuesto, ya que está confinada al objeto conductor.
 9.45.24a.m.png)
Nos parece asombroso que la carga de un conductor fluya hacia la superficie debido a su repulsión mutua. Las cargas se dispersan de forma natural tanto como pueden, pero que todas migren a la superficie parece, a primera vista, un desperdicio del espacio interior. Seguramente podríamos hacerlo mejor, desde el punto de vista de alejar cada carga lo máximo posible de sus vecinas, distribuyendo algunas de ellas a lo largo del volumen. Sin embargo, simplemente no es así. Lo óptimo es situar toda la carga en la superficie, y esto es cierto independientemente del tamaño o de la forma del conductor.
El problema también puede expresarse en términos de energía. Como en cualquier sistema dinámico libre, la carga de un conductor busca la configuración que minimiza su energía potencial. La propiedad (iii) afirma que la energía electrostática de un objeto sólido es mínima cuando la carga se distribuye sobre su superficie.
6.19 Cargas inducidas
 7.32.28p.m.png)
Si mantienes una carga +q cerca de un conductor esférico sin carga, ambos se atraerán mutuamente. La razón de esto es que q atraerá carga más hacia el lado lejano. Otra forma de pensarlo es que la carga se mueve de tal manera que elimina el campo q para los puntos dentro del conductor, donde el campo total debe ser cero. Dado que la carga inducida negativa está más cerca de q, existe una fuerza neta de atracción.
Cuando hablamos de campo, carga potencial “dentro” de un conductor, nos referimos al “núcleo” del conductor; si hay alguna manera hueca en el conductor, y dentro de esta cavidad se pone algo de carga entonces el campo en la cavidad no será cero. Pero, de forma notable, la cavidad y su contenido están eléctricamente asilados del mundo exterior por el conductor circundante. No penetra campos eternos en el conductor; se cancelan en la superficie exterior por la carga inducida allí. De manera similar, el campo debido a las cargas dentro de la cavidad se cancela, para todos los puntos exteriores, por la carga inducida en la superficie interna. Sin embargo, la carga compensadora que queda en la superficie exterior del conductor “comunica” efectivamente la presencia de q al mundo exterior. La carga total inducida en la pared de la cavidad es igual y opuesta a la carga interior, porque si rodeamos la cavidad es igual y opuesta a la carga interior, porque en el conductor:
 10.05.09a.m.png) y
y
por lo tanto según la ley de Gauss la carga neta encerrada debe ser cero. Pero Qenc=q + qinducida, así que qinducida =-q. Y si el conductor en su conjunto es electrizante neutro, debe haber una cara +q en su superficie exterior.
Si una cavidad rodeada de material conductor está vacía de carga, entonces el campo dentro de la cavidad es cero. Para cualquier línea de campo tendría que comenzar y terminar en la pared de la cavidad, pasando de una carga positiva a una negativa.
 10.11.14a.m.png)
Dejando que esa línea de campo forme parte de un lazo cerrado, cuyo resto está completamente dentro del conductor (donde E=0), la integral:
 12.11.52p.m.png) es claramente positiva, en violación en:
es claramente positiva, en violación en:
 12.14.42p.m.png)
De ello se deduce que E=0 dentro de una cavidad vacía, y de hecho no hay carga en la superficie de la cavidad. Por eso estás relativamente seguro dentro de un coche metálico durante una tormenta eléctrica, puedes caer un rayo en el auto pero no te electrocutara. El mismo principio se aplica a la colocación de aparatos sensibles dentro dentro de una jaula de Faraday conectada a tierra, para bloquear campos eléctricos dispersos. En la práctica, el la jaula ni siquiera tiene que ser un conductor sólido: el alambre de gallinero suele ser suficiente.
6.20 Carga superficial y la fuerza sobre un conductor
Como el campo dentro de un conductor es cero, la ecuación:
 12.26.31p.m.png) requiere que el campo inmediatamente exterior sea:
requiere que el campo inmediatamente exterior sea:
 12.27.22p.m.png)
Consistente con nuestra conclusión anterior de que el campo es normal a la superficie. En términos de potencial, la ecuación:
 12.28.57p.m.png) se tranforma en:
se tranforma en:
 12.29.33p.m.png)
Estas ecuaciones permiten calcular la carga superficial de aun conductor, si puedes determinar E o V; los usaremos con frecuencia. En presencia de un campo eléctrico, cualquier carga superficial experimentará una fuerza; la fuerza por unidad de área, f, es de σE. Pero hay un problema aquí, porque el campo eléctrico es discontinuo a una carga superficial, así que ¿qué se supone que debemos usar? La respuesta es que deberíamos usar la media de los dos:
 5.29.50p.m.png)
 5.30.59p.m.png)
¿Por qué la media? La razón es muy sencilla, aunque la explicación la hace parecer complicada: Centraremos nuestra atención en un pequeño parche de superficie que rodea en cuestión. Hazlo lo suficientemente pequeño para que sea esencialmente plano y la carga superficial sobre él sea prácticamente constante. El campo total consta de dos partes: la atribuible al propio parche y la que se debe a todo lo demás (otras regiones de la superficie, así como cualquier fuente externa que pueda estar presente):
 6.13.33p.m.png)
Ahora bien, el parche no puede ejercer fuerza sobre sí mismo, igual que no puedes levantarte de pie en una cesta y tirar de las asas. La fuerza sobre el parche, entonces, se debe exclusivamente Eother, y esto no sufre discontinuidad (si quitáramos el parche, el campo en el “agujero” quedaría perfectamente liso). La discontinuidad se debe enteramente a la carga en el parche, que genera un campo 6.17.20p.m.png) a cada lado, apuntando lejos de la superficie. Así:
a cada lado, apuntando lejos de la superficie. Así:
 6.18.00p.m.png)
Y por tanto:
 6.18.17p.m.png)
El promedio es realmente solo un recurso para eliminar la contribución del propio parche. Ese agumento se aplica a cualquier carga superficial; en el caso particular de un conductor, el campo es cero dentro  6.18.58p.m.png) fuera:
fuera:
 6.22.11p.m.png)
Por lo que la media es , y la fuerza por unidad de aérea es:
 6.21.49p.m.png)
Esto equivale a una presión electrostática hacia afuera en la superficie, que tiende a atraer el conductor hacia el campo, independientemente del signo de σ. Expresando la presión en términos del campo justo de la superficie:
 6.25.14p.m.png)
Evaluación 12__________
6.21 Capacitores
Supongamos que tenemos dos conductores y ponemos carga +Q en una y -Q en otro.
 10.33.18a.m.png)
Dado que V es constante sobre un conductor, podemos hablar sin ambigüedad de la diferencia de potencial entre ambos:
 10.34.16a.m.png)
No sabemos cómo se distribuye la carga entre los dos conductores, y calcañar el campo sería una pesadilla si sus formas son complicadas, pero esto sí lo sabemos: E es proporcional a Q, porque E está dada por la Ley de Coulomb:
 10.36.02a.m.png)
Así que si duplicas p, duplicas E. Espera un momento, ¿cómo sabemos que duplicar Q (y también -Q) simplemente duplica p? Quizás la carga se mueve a una configuración completamente diferente, cuadruplicando p en algunos puntos y reduciéndola a la mitad en otros, solo para que la carga total de cada conductor se duplique. La realidad es que esta preocupación no está justificada: duplicar Q duplica p en todas partes; no desplaza la carga. Como E es proporcional a Q, también lo es V. La constante de proporcional se llama capacitancia de la disposición:
 11.20.15a.m.png)
La capacitancia es una magnitud puramente geométrica, determinada por los tamaños, formas y separaciones de los dos conductores. En unidades SI, C se mide en farads (F), un farad es un coulomb por voltio. En realidad, resulta ser incómodamente grande; las unidades más prácticas son el microfarad (10^-6 F) y picofarad (10^-2F).
Nótese que V es, por definición, el potencial del conductor positivo menos del negativo; del mismo modo, Q es la carga en el conductor positivo. Por tanto, la capacidad es una cantidad intrínsecamente positiva. Por cierto, de vez en cuando escucharás a alguien hablar de la capacidad de un solo conductor. En este caso, el “segundo conductor”, con carga negativa, es una cáscara esférica imaginaria de radio infinito que rodea al conductor. No aporta nada el campo, por lo que la capacidad está dada por:
 11.27.13a.m.png)
Donde V es el potencial con infinito como punto de referencia.
 11.32.21a.m.png)
Para “carga” un condensador, tienes que extraer electrones de la placa positiva y llevarlos a la placa negativa Al hacerlo, luchas contra el campo eléctrico, que los trae hacia el conductor positivo y los aleja negativo. ¿Cuánto trabajo se necesita, entonces, para cargar el condensador hasta una cantidad final Q? Supongamos que en alguna etapa intermedia del proceso la carga en la placa positiva es q, de modo que la diferencia de potencial es q/C. Según:
 11.31.53a.m.png)
El trabajo que se debe hacer para transportar la siguiente pieza de carga, descalificación, es:
 11.33.22a.m.png)
El trabajo total necesario, entonces, para pasar de q=0 a q=Q, es:
 11.34.21a.m.png)
O, ya que Q=CV;
 11.35.08a.m.png)
Donde V es el potencial final del condensador.
6.22 Polarización
6.22.1 Dieléctricos
Estudiaremos los campos eléctricos en la materia. La materia, por supuesto, se presenta de muchas formas —sólidos, líquidos, gases; metales, madera, vidrio— y estas sustancias no responden todas de la misma manera a los campos electrostáticos. No obstante, la mayoría de los objetos cotidianos pertenece a una de dos grandes clases: conductores y aislantes (o dieléctricos).
Ya hemos hablado de los conductores: son sustancias que contienen un suministro prácticamente “ilimitado” de cargas que pueden circular libremente a través del material. En la práctica, esto suele significar que muchos de los electrones (uno o dos por átomo, en un metal típico) no están asociados a ningún núcleo en particular, sino que se desplazan en respuesta a campos aplicados. En los dieléctricos, en cambio, todas las cargas están ligadas a átomos o moléculas específicas: se encuentran bajo una restricción estricta y lo único que pueden hacer es desplazarse ligeramente dentro del átomo o de la molécula.
Estos desplazamientos microscópicos no son tan dramáticos como la reorganización global de la carga en un conductor, pero sus efectos acumulativos explican el comportamiento característico de los materiales dieléctricos. En realidad, existen dos mecanismos principales mediante los cuales los campos eléctricos pueden distorsionar la distribución de carga de un átomo o molécula dieléctrica: el estiramiento y la rotación.
6.22.2 Dipolos inducidos
¿Qué le ocurre a un átomo neutro cuando se coloca en un campo eléctrico E? La primera suposición podría ser que no ocurre absolutamente nada: dado que el átomo no está cargado, el campo no tendría efecto alguno sobre él. Pero esta suposición es incorrecta. Aunque el átomo en su conjunto es eléctricamente neutro, el núcleo es empujado en la dirección del campo y los electrones en sentido contrario. En principio, si el campo es lo suficientemente intenso, puede separar completamente el átomo, ionizándolo (la sustancia se convierte entonces en conductora). Sin embargo, para campos menos extremos, pronto se establece un equilibrio, ya que, si el centro de la nube electrónica no coincide con el núcleo, las cargas positivas y negativas se atraen entre sí, y esta atracción mantiene unido al átomo. Las dos fuerzas opuestas —el campo eléctrico, que tiende a separar el núcleo de los electrones, y su atracción mutua, que los vuelve a reunir— alcanzan un equilibrio, dejando al átomo polarizado, con la carga positiva ligeramente desplazada hacia un lado y la negativa hacia el otro. El átomo adquiere entonces un momento dipolar diminuto p, que apunta en la misma dirección que E. Normalmente, este momento dipolar inducido es aproximadamente proporcional al campo, siempre que este último no sea demasiado intenso:
 8.01.06p.m.png)
La constante de proporcionalidad α se denomina polarizabilidad atómica. Su valor depende de la estructura detallada del átomo en cuestión. Algunas polarizaciones atómicas determinadas experimentalmente:
 10.21.05a.m.png)
Polarizabilidad atómica (α/4πεo, en unidades de 10^-30 m3). Datos de Handbook of Chemistry and Physics, CRC Press, Boca Raton (2010).
Para las moléculas la situación no es tan simple, porque frecuentemente se polarizan más eficientemente en algunas direcciones que en otras. El dióxido de carbono, por ejemplo, tiene una polarizabilidad de 4.5x10^-40C^2 m/N cuando se aplica el campo a lo largo del eje de la molécula, siendo solo 2x10^-40 para campos perpendiculares, y multiplicar cada una por la polarización pertinente:
 8.15.50p.m.png)
En ese caso, el momento dipolar inducido puede ni siquiera estar en la misma dirección que E. Y el CO2 es relativamente sencillo, en cuanto a moléculas, ya que al menos átomos se disponen en línea recta; para una molécula completamente asimétrica, la ecuación
 8.19.33p.m.png)
 8.24.59p.m.png)
Se reemplaza por la relación lineal más general entre E y p:
 8.20.29p.m.png)
El conjunto de nueve constantes αij constituye el tensor de polarizabilidad para la molécula. Sus valores dependen de la orientación de los ejes que se utilicen, aunque siempre es posible elegir ejes “principales” de modo que todos los términos fuera de la diagonal (αxy, αzx…) se anulen, dejando solo tres polarizaciones distintivas de cero: αxx, αyy y αzz.
6.22.3 Alineación de moléculas polares
En el apartado anterior se discutió que el átomo neutro no posee un momento dipolar intrínseco; p es inducido por el campo aplicado. Sin embargo, algunas moléculas presentan momentos dipolares permanentes incorporados en su propia estructura. En la molécula de agua, por ejemplo, los electrones tienden a concentrarse alrededor del átomo de oxígeno y, dado que la molécula tiene una geometría angular de aproximadamente 105°, esto deja una carga parcial negativa cerca del oxígeno y una carga parcial neta positiva en el lado opuesto.
 11.04.05p.m.png)
El oxígeno es más electronegativo → acumula densidad electrónica. La geometría no lineal impide la cancelación de los dipolos de enlace. La interacción con campos eléctricos favorece la electroforesis y absorbe microondas (rotación forzada de dipolos → calentamiento). El momento dipolar del agua es inusualmente grande en coulomb por metro: 6.1x10^-30C?m; de hecho, esto explica su eficiencia como disolvente. El vector momento dipolar apunta por convencionalidad desde el oxígeno a los hidrógenos.
 11.16.52p.m.png)
(donde εr es la permitividad relativa o constante dieléctrica).
¿Qué ocurre cuando tales moléculas llamadas polares se colocan en un campo eléctrico? Si el campo es uniforme, al fuerza en el extremo positivo, F+=qE, cancela exactamente a la fuerza en el extremo negativo, F-=-qE. Sin embargo, habrá un par motor:
 11.26.52p.m.png)
Así, un dipolo p=qd en un campo uniforme E experimenta un par motor:
 11.28.54p.m.png)
Nótese que N está en una dirección tal que alinea p paralela a E; una molécula polar que puede girar libremente girará hasta apuntar en la dirección del campo aplicado.
Si el campo no es uniforme, de modo que F+ no equilibra exactamente F-, habrá una fuerza resultante neta sobre el dipolo, además del par. Por supuesto, E debe cambiar de forma bastante abrupta para que haya una variación significativa en el espacio de una molécula, por lo que esto suele ser una consideración principal al discutir el comportamiento de los dieléctricos. No obstante, la fórmula de la fuerza sobre un dipolo en un campo no uniforme es de cierto interés:
 11.34.39p.m.png)
Donde ΔE representa la diferencia entre el campo en el extremo positivo y el campo en el extremo negativo. Suponiendo que el dipolo es muy corto, podemos usar la ecuación:
 11.38.28p.m.png)
Para aproximar el pequeño cambio en Ex:
 11.39.38p.m.png)
Con fórmulas correspondientes para Ey y Ez. De forma más compacta:
 11.41.13p.m.png)
Y por lo tanto:
 11.42.05p.m.png)
Para un dipolo “perfecto” de longitud infinitesimal, la ecuación:
 11.43.10p.m.png)
Da el par alrededor del centro del dipolo incluso en un campo no uniforme; sobre cualquier otro punto:
 11.44.05p.m.png)
6.22.4 Polarización
¿Qué ocurre cuando un trozo de material dieléctrico se coloca en un campo eléctrico? Si la sustancia está formada por átomos neutros (o moléculas no polares), el campo inducirá en cada uno un diminuto momento dipolar, apuntando en la misma dirección que el campo. Si el material está compuesto por moléculas polares, cada dipolo permanente experimentará un par motor que tiende a alinearlo con la dirección del campo. Los movimientos térmicos aleatorios compiten con este proceso, por lo que la alineación nunca es completa, especialmente a temperaturas más altas, y desaparece casi inmediatamente cuando se elimina el campo. Obsérvese que estos dos mecanismos producen el mismo resultado básico: muchos pequeños dipolos orientados en la dirección del campo; el material, en conjunto, se polariza. Una medida conveniente de este efecto es:
P ≡ momento dipolo por unidad volumen.
Se llama polarización. A partir de ahora no nos detendremos demasiado en cómo se origina. En realidad, los dos mecanismos que describimos no son tan nítidos como intentamos presentarlos. Incluso en moléculas polares habrá cierta polarización por desplazamiento de cargas (aunque, por lo general, es mucho más fácil girar una molécula que deformarla, por lo que predomina el segundo mecanismo). Asimismo, en algunos materiales es posible que la polarización quede “congelada”, de modo que persista aun después de eliminar el campo. Pero podemos dejar momentáneamente de lado la causa de la polarización: debemos estudiar el campo que produce un fragmento de material polarizado. Luego, sumaremos el campo original —responsable de P— con el nuevo campo debido a P.
6.22.5 Cargas ligadas
Supongamos que tenemos un trozo de material polarizado, es decir, un objeto que contiene muchos dipolos microscópicos alineados. Se define el momento dipolar por unidad de volumen como P. La pregunta es: ¿cuál es el campo producido por este objeto? (No el campo que causó la polarización, sino el campo que la polarización misma genera). Sabemos cómo es el campo de un dipolo individual, así que, ¿por qué no dividir el material en dipolos infinitesimales e integrarlos para obtener el total? Como casi siempre, es más sencillo aprovechar el potencial. Para un solo dipolo p…
 7.24.28p.m.png)
Donde r es el vector desde el dipolo hasta el punto en el que evaluamos el potencial.
 7.25.33p.m.png)
En el contexto actual, tenemos un momento dipolar p = P dτ’ en cada elemento de volumen dτ’, por lo que el potencial total es:
 7.29.04p.m.png)
Este es todo, en principio. Pero un pequeño truco de manos convierte esto en una forma mucho más iluminadora. Observando que:
 7.30.29p.m.png)
Donde la diferenciación es repescó a las coordenadas fuente (r’), tenemos:
 7.32.02p.m.png)
Integrando por piezas, usando la regla de producto número 5 (dentro de la cubierta frontal) se obtiene:
 7.33.16p.m.png)
O, invocando el teorema de divergencia:
 7.34.04p.m.png)
El primer término se refiere al potencial de una carga superficial:
 7.35.01p.m.png)
Donde n^ es el vector unitario normal, mientras que el segundo término se refiere al potencial de una carga volumétrica:
 7.36.10p.m.png)
Con estas definiciones, la ecuación:
 7.34.04?p.m.png)
se convierte en...
 7.37.21p.m.png)
Esto significa que el potencial (y por tanto también el campo) de un objeto polarizado es el mismo que el producido por una densidad de carga volumétrica ρb=-∇?P más una densidad de carga superficial σb=P ? n. En lugar de integrar las contribuciones de todos los infinitesimales, como en:
 7.42.32p.m.png)
Podríamos primero encontrar esas cargas ligadas y luego calcular los campos que producen, de la misma manera que calculamos el campo de cualquier otro volumen y carga superficial (por ejemplo, usando la ley de Gauss).
6.22.5.1 Interpretación física de cargas ligadas
En la última sección encontramos que el campo de un objeto polarización es idéntico el campo que produciría una cierta distribución de “carga ligadas”, σb y ρb. Pero esta conclusión surgió en el curso de manipulaciones abstractas de la integral en:
 7.49.03p.m.png)
Y no nos dejó ninguna pista sobre el significado físico de estas cargas ligadas. De hecho, algunos autores dan la impresión de que las cargas encuadernadas son, en cierto sentido, “ficticias” —meros dispositivos de contabilidad usados para facilitar el cálculo de campos. Nada podría estar más lejos de la realidad: σb y ρb representan algo perfectamente genuino acumulaciones de carga.
La idea básica es muy simple: Supongamos que tenemos una carga cadena de dipolos:
 7.39.57p.m.png)
A lo largo de la línea, la cabeza de uno cancela efectivamente la cola de su vecino, pero en los extremos quedan dos cargas: más en el extremo derecho y menos en el izquierdo. Es como si hubiéramos arencado un electrón de un extremo y lo hubiéramos llevado hasta el otro, aunque en realidad ningún electrón hizo todo el viaje: muchos desplazamientos diminutos suman uno grande. Llamemos carga neta en los extremos para recordarnos que no puede eliminarse; en un dieléctrico, cada electrón está unido a un átomo o molécula específico. Pero aparte de eso, la carga ligada no es diferente de cualquier otro tipo.
Para calcular la cantidad real de carga ligada resultante de una polarización dada, examinemos un “cubo” de dieléctrico paralelo a P. El momento dipolar del pequeño fragmento mostrado es P(Ad) , donde A es el área de la sección transversal del tubo y d es la longitud del bloque. En términos de la carga q al final, este mismo momento dipolar puede escribirse como qd. La carga ligada que se acumula en el extremo derecho del tubo es por tanto:
 7.49.37p.m.png)
 7.56.10p.m.png)
Si los extremos han sido cortados perpendicularmente, la densidad de carga superficial es:
 7.57.11p.m.png)
Para un corte oblicuo, la carga sigue siendo la misma, pero A= Aend cos θ, es:
 7.58.56p.m.png)
 7.59.20p.m.png)
El efecto de polarización, entonces, es pintar una carga ligada:
 8.00.10p.m.png)
Sobre la superficie del material. Esto es exactamente lo que encontramos por medios más rigurosos. Pero ahora sabemos de dónde proviene la carga vinculada. Si la polarización no es uniforme, se obtienen acumulaciones de carga unidad dentro del material, así como en la superficie. Un vistazo que una divergente da lugar a una acumulación de carga negativa. De hecho, la carga neta ligada:
 8.36.56p.m.png)
en un volumen dado es igual y opuesta a la cantidad que ha sido empujaba hacia fuera a través de la superficie. La segunda (por el mismo razonamiento que usamos antes) es
 8.39.25p.m.png) de área, así que:
de área, así que:
 8.02.39p.m.png)
 8.40.58p.m.png)
Dado que esto es cierto para cualquier volumen, tenemos:
 8.42.07p.m.png)
Confirmando, de nuevo la conclusión pero más rigurosa.
Evaluación 13__________
6.23 Cálculo de la velocidad de la luz
El electromagnetismo es una teoría basada en una serie de experimentos cuantitativos llevados a cabo durante muchos años, a partir del siglo XVIII. Estos experimentos fueron compilados en una teoría consistente de fenómenos eléctricos y magnéticos por James Clerk Maxwell en 1865. Hasta entonces, las interacciones eléctricas y magnéticas se consideraban dos fenómenos independientes. Las ecuaciones de Maxwell proporcionan la primera unificación de dos tipos de interacciones aparentemente diferentes.
Estas ecuaciones permiten modelar los campos eléctricos y magnéticos E y B como funciones de posición y tiempo, en términos de la densidad de carga y la densidad de corriente j que los produce. Las ecuaciones (1.1) constituyen la base de una teoría que describe de forma unificada fenómenos eléctricos, magnéticos y ópticos. Su validez se ha comprobado desde escalas atómicas hasta astronómicas. A nivel atómico, debe hacerse compatible con las leyes de la mecánica cuántica.
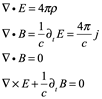 Ec.1.1
Ec.1.1
Ecuación de onda
Dicho simplemente, la función de onda de cualquier onda, es la función que define el valor de la perturbación en cada lugar y tiempo. Al leer acerca de las funciones de onda, a menudo se encontrará con declaraciones matemáticas aparentemente redundantes, como:
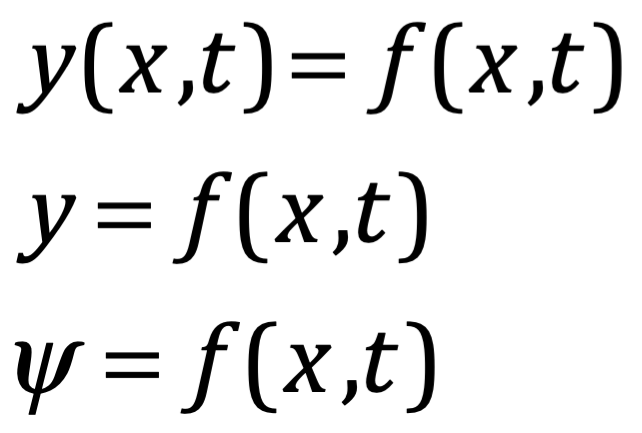
En estas ecuaciones, “y” y representan la función de onda del desplazamiento. En su lugar,
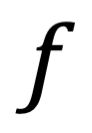 representa una función de posición (x) y tiempo (t). ¿Y exactamente cuál es esa función? En cualquier función que describa la forma de la onda en el tiempo y el espacio. Más tarde no usaremos f para representar la función, por la posible confusión que genera con el concepto de frecuencia f asociada a la onda.
representa una función de posición (x) y tiempo (t). ¿Y exactamente cuál es esa función? En cualquier función que describa la forma de la onda en el tiempo y el espacio. Más tarde no usaremos f para representar la función, por la posible confusión que genera con el concepto de frecuencia f asociada a la onda.
Para comprender esto, solo recuerde que decir “una función de x y t solo significa, las variables independientes x y t. Por lo tanto, una ecuación como la de 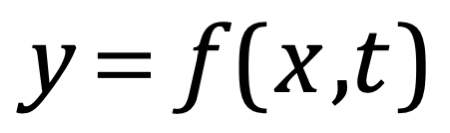 significa que el valor del desplazamiento (y) depende tanto de la ubicación (x) como del tiempo (t) al que se mide la onda. Así que si la función f cambia muy lentamente con (x) y con (t), tendrías que mirar la onda en dos lugares muy separados o en dos momentos muy diferentes para ver mucha diferencia en la perturbación producida por la onda.
significa que el valor del desplazamiento (y) depende tanto de la ubicación (x) como del tiempo (t) al que se mide la onda. Así que si la función f cambia muy lentamente con (x) y con (t), tendrías que mirar la onda en dos lugares muy separados o en dos momentos muy diferentes para ver mucha diferencia en la perturbación producida por la onda.
Y, ya que la elección de la función f(x,t) determina la forma de la onda, a través de la indicación del desplazamiento de onda en cualquier lugar del tiempo depende de la forma de la onda y su posición. La forma de pensar más fácil es imaginar tomar una instantánea de la onda en algún instante de tiempo: la fase. Para mantener la notación simple, puede llamar al tiempo en la que se toma la instantánea: t=0; las instantáneas tomadas más tarde se cronometrarán en relación con esta primera. En el momento de esa primera instantánea se puede escribir como:
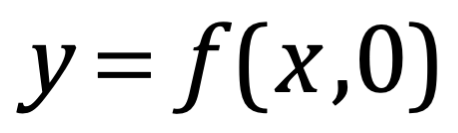
Muchas ondas mantienen la misma forma con el tiempo: la onda se mueve en la dirección de propagación, pero todos los picos y valles se mueven al unísono, por lo que la forma no cambia a medida que se mueve. Por tales ondas “no dispersivas” f(x,0) se puede escribir como f(x), ya que la forma de la onda no depende de cuando tome la instantánea. La función f(x) se puede llamar “perfil de onda”. Algunos perfiles de onda por ejemplo son:
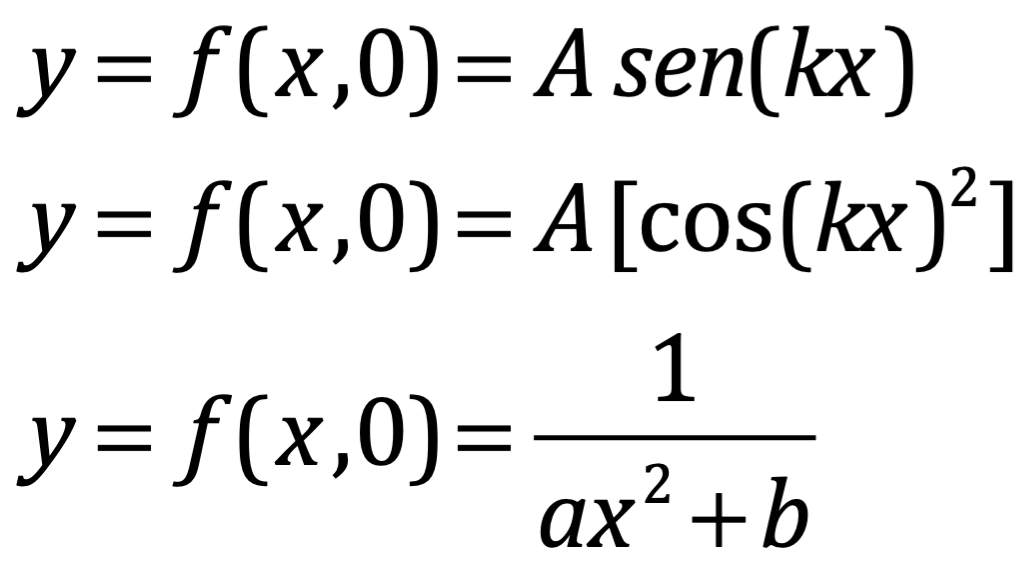
Un graficador puede observarse el perfil de estas ondas.
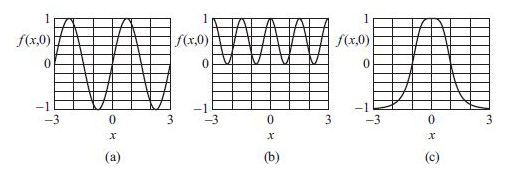
Una vez que tenga un perfil de onda f(x), es un paso corto a la función de onda 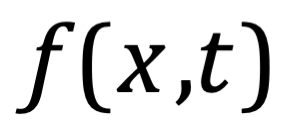 . Para dar ese paso, hay que pensar en la manera de incluir el hecho de que la perturbación física producida por la onda, depende tanto del espacio, como del tiempo. Recuerde que el desplazamiento responde a la pregunta ¿qué tan grande es la onda en este espacio y tiempo? La fase responde a la pregunta qué parte de la onda está en el tiempo y en el espacio? Por lo tanto, tiene sentido que la dependencia funcional del desplazamiento esté relacionada con la fase de onda.
. Para dar ese paso, hay que pensar en la manera de incluir el hecho de que la perturbación física producida por la onda, depende tanto del espacio, como del tiempo. Recuerde que el desplazamiento responde a la pregunta ¿qué tan grande es la onda en este espacio y tiempo? La fase responde a la pregunta qué parte de la onda está en el tiempo y en el espacio? Por lo tanto, tiene sentido que la dependencia funcional del desplazamiento esté relacionada con la fase de onda.
Para hacer esto explícito, la fase de onda depende del espacio:
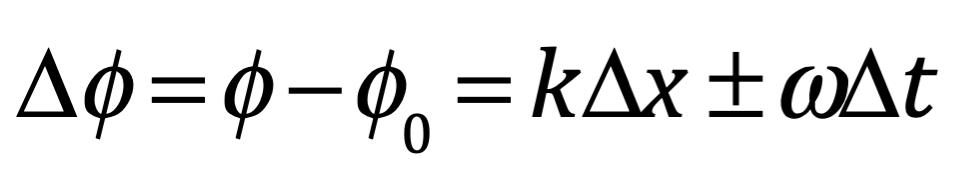
Donde el 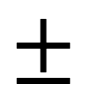 permite la propagación de ondas en cualquier dirección: positiva o negativa. Escribiendo el cambio de ubicación como:
permite la propagación de ondas en cualquier dirección: positiva o negativa. Escribiendo el cambio de ubicación como:
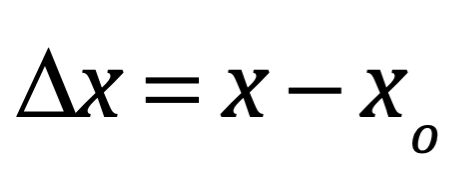
Cambio en el tiempo como:
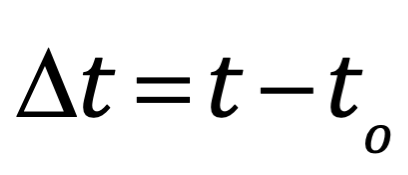
Si el tiempo inicial es cero, entonces
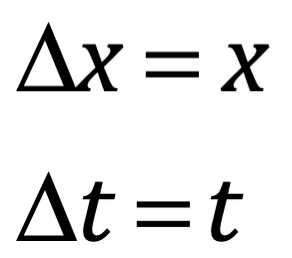
La fase inicial 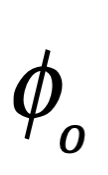 se toma como cero, la fase en cualquier ubicación x y tiempo t se puede escribir como:
se toma como cero, la fase en cualquier ubicación x y tiempo t se puede escribir como:
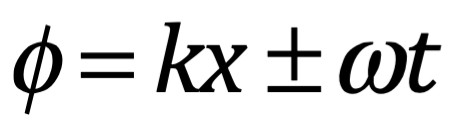
Donde la función f determina la forma de la onda y el argumento de la función es decir, 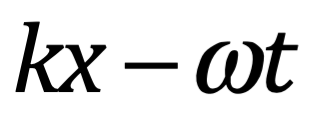 es la fase de la onda en cada ubicación x y en el tiempo t. Esta ecuación es extremadamente útil para resolver una amplia gama de problemas de onda, ya que tiene la velocidad de la onda incorporada. Por lo tanto, la forma del desplazamiento puede escribirse como:
es la fase de la onda en cada ubicación x y en el tiempo t. Esta ecuación es extremadamente útil para resolver una amplia gama de problemas de onda, ya que tiene la velocidad de la onda incorporada. Por lo tanto, la forma del desplazamiento puede escribirse como:
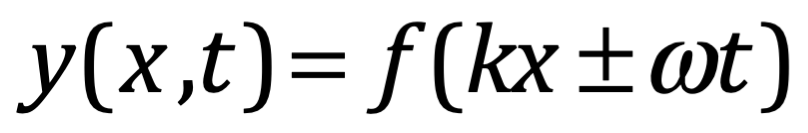
Donde la función f determina la forma de la onda y el argumento de la función 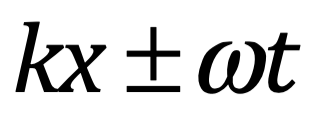 es la fase de la onda
es la fase de la onda  de la onda para cada ubicación x en el tiempo t.
de la onda para cada ubicación x en el tiempo t.

Por ejemplo, A es la amplitud de la onda de 3 metros, 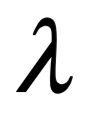 la longitud de onda de 1 metro, el periodo de onda T es de 5 segundos. Encuentre el valor desplazamiento de
la longitud de onda de 1 metro, el periodo de onda T es de 5 segundos. Encuentre el valor desplazamiento de 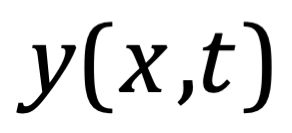 en la posición x=0.6 m y un tiempo de t=3 segundos.
en la posición x=0.6 m y un tiempo de t=3 segundos.
La amplitud de la onda nos dice que tan grande es la onda en los picos, la longitud de onda nos dice lo lejos que se diferencia para espaciar los picos en cada página, y el periodo de onda le dice cuánto cambia la onda entre páginas ya que tiene que moverse una distancia de uno en la dirección de propagación durante cada periodo.
La longitud de onda de 1 metro significa que el número de onda es:
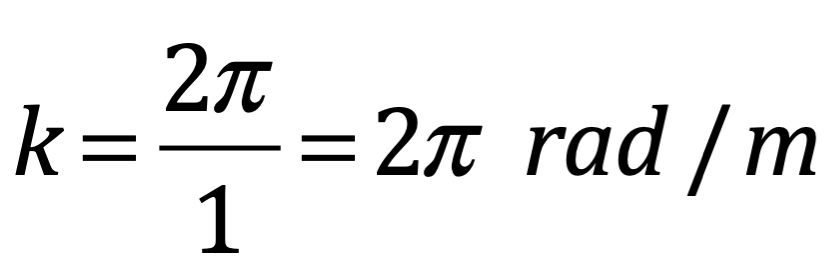
El periodo de 5 segundos le indica que la frecuencia es f=1/5 segundos:
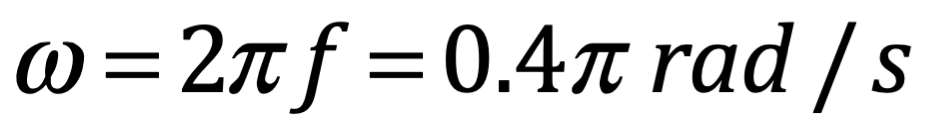
Conectando estos valores da:
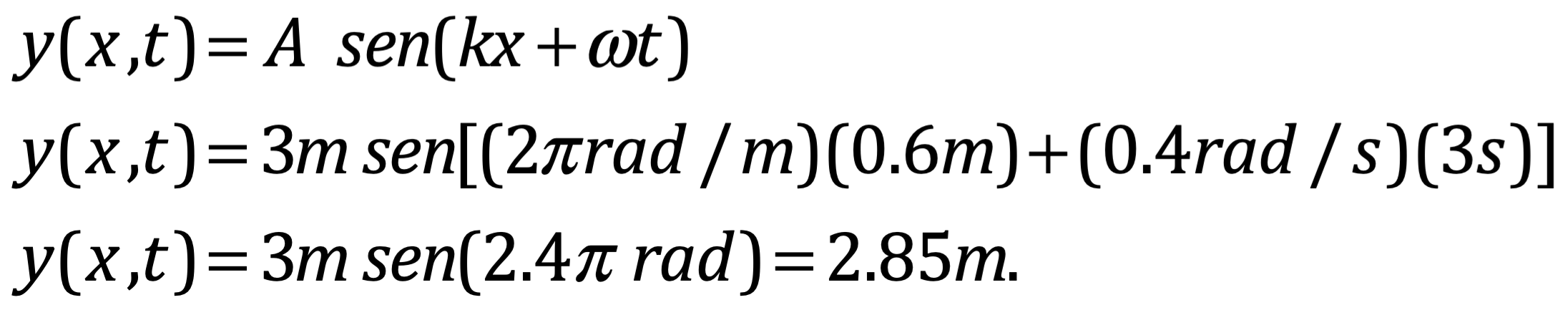
Si 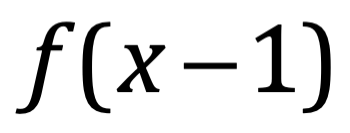 se desplaza en dirección x negativa. Esto significa que si una función se desplaza a la izquierda o la derecha con solo mirar el signo del término adicional en el argumento, debemos comparar el signo de ese término con el signo del término x. Si esto signos son los mismos, la función se desplaza en la dirección x positiva.
se desplaza en dirección x negativa. Esto significa que si una función se desplaza a la izquierda o la derecha con solo mirar el signo del término adicional en el argumento, debemos comparar el signo de ese término con el signo del término x. Si esto signos son los mismos, la función se desplaza en la dirección x positiva.
Con esto en mente debería ver que una función se mueve en la dirección x negativa ya que los signos en el termino x y en tiempo son positivos.

Representa que una onda se mueve en la dirección x negativa.
Caso contrario se mueve en la dirección x positiva, ya que los signos en el término x y el plazo temporal son opuestos.

La velocidad v, por la unidad de tiempo que demora en recorrer esa distancia.
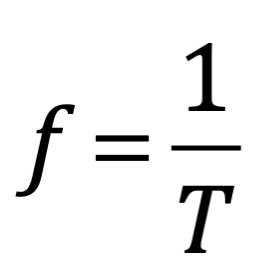
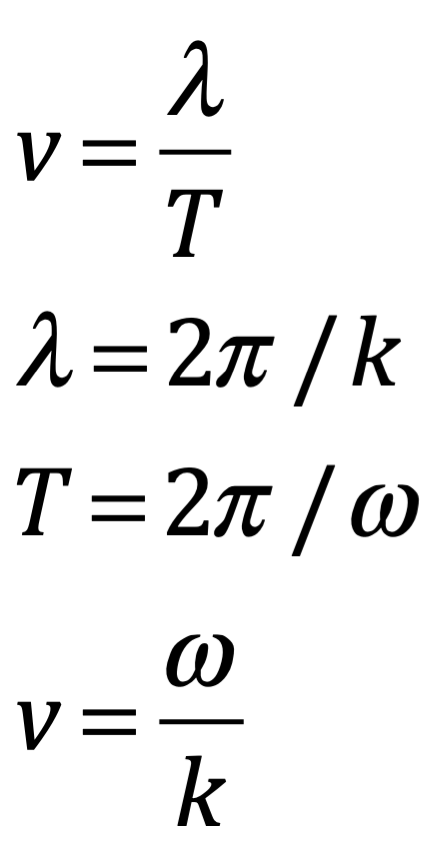
Donde:
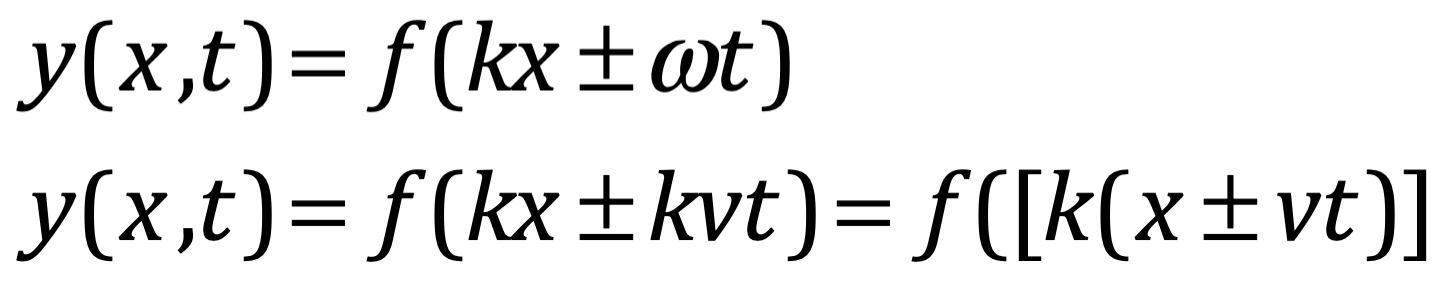
Aveces se escribe como
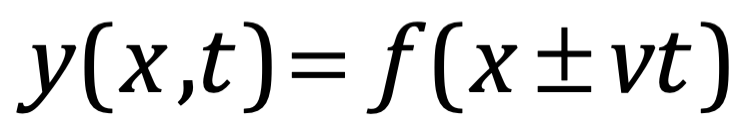
Ambos términos tienen unidades de distancia, es solo porque el propósito de esta ecuación es mostrar la dependencia funcional del desplazamiento f en x y t, por lo que el factor del número de onda k no se muestra explícitamente.
 (La letra omega griega) la frecuencia angular, indica cuánto ángulo avanza la fase de onda en una cantidad determinada por el tiempo, por lo que las unidades SI están dadas en radianes por segundo. Está relacionada con la frecuencia por la ecuación:
(La letra omega griega) la frecuencia angular, indica cuánto ángulo avanza la fase de onda en una cantidad determinada por el tiempo, por lo que las unidades SI están dadas en radianes por segundo. Está relacionada con la frecuencia por la ecuación:
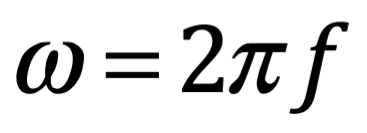
Relaciona la frecuencia f o el periodo T con los ángulos.
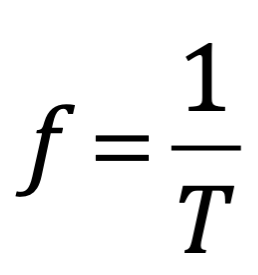
La amplitud A, es una valor espacial relacionado con el desplazamiento vertical produce picos y valles como máximos y mínimos. Se mide desde la condición de equilibro hasta el pico. La v velocidad de onda, se esta hablando de velocidad de fase. Si medimos cuánto tarda una cresta de una onda en recorrer una cierta distancia, estamos midiendo la velocidad de fase de onda. ¿Qué determina qué parte de una onda está en un lugar determinado en un instante?
 14.36.49.png)
 , la fase es el argumento de la función que describe la onda, la fase tiene unidades SI en radianes y valores entre 0 y
, la fase es el argumento de la función que describe la onda, la fase tiene unidades SI en radianes y valores entre 0 y  durante un ciclo (también fase de onda puede verse expresada en unidades de grados, en cuyo, un ciclo de 360º =
durante un ciclo (también fase de onda puede verse expresada en unidades de grados, en cuyo, un ciclo de 360º = ).
).
Lo que determina el punto de partida de una onda, es la constante de onda.
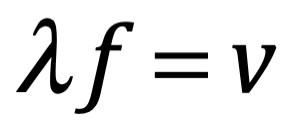
La velocidad de onda v es constante, la longitud de onda 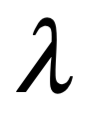 es variable, si la longitud de onda es corta, la frecuencia debe ser alta.
es variable, si la longitud de onda es corta, la frecuencia debe ser alta.
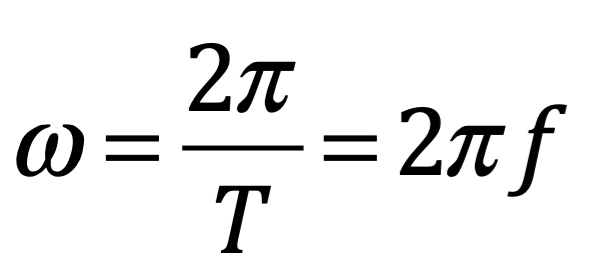
Puede verse en esta ecuación que la frecuencia angular tiene dimensiones de ángulo a lo largo del tiempo, rad/s. Por lo tanto, la frecuencia f le indica el número de ciclos por segundo, y la frecuencia angular  le indica el número de radianes por segundo. He aquí por qué la frecuencia angular de una onda es un parámetro útil. Supongamos que desea saber cuánto cambiará la fase de una onda en una ubicación determinada en una cantidad de información de tipo (t). Para encontrar ese cambio de fase
le indica el número de radianes por segundo. He aquí por qué la frecuencia angular de una onda es un parámetro útil. Supongamos que desea saber cuánto cambiará la fase de una onda en una ubicación determinada en una cantidad de información de tipo (t). Para encontrar ese cambio de fase 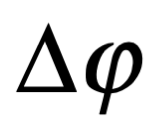 , solo tiene que multiplicar la frecuencia angular
, solo tiene que multiplicar la frecuencia angular  por el intervalo de tiempo
por el intervalo de tiempo 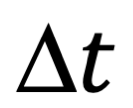 .
.
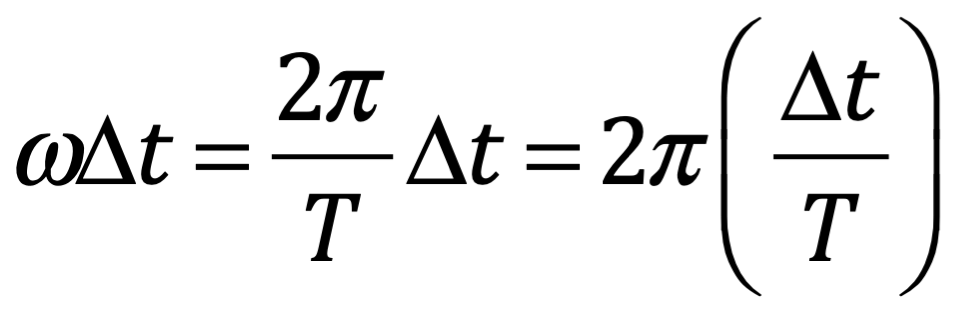
Esto ilustra por qué la frecuencia angular puede considerarse un convertidor de tipo fase. Dada cualquier cantidad de tiempo t, puede con ese tiempo obtenerse el cambio de fase como el producto 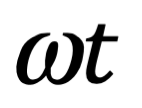 .
.
En número de onda k y la longitud de onda se relacionan:
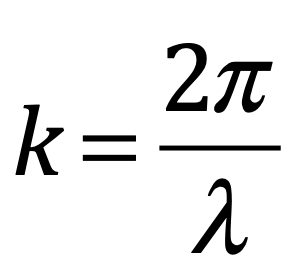
El cambio de fase:
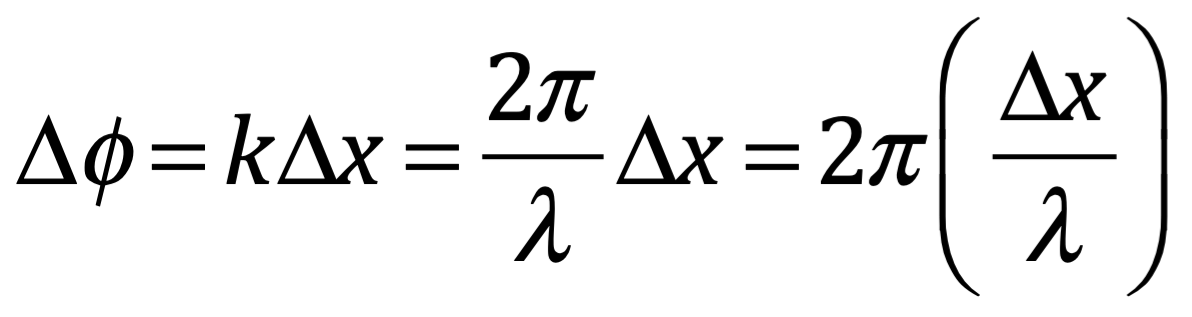
Donde el tiempo es constante, esto nos recuerda que el cambio de fase se debe solo al cambio de ubicación. Así que las ondas son perturbaciones que pueden o no ser propagadas, periódicas y armónicas. Una onda itinerante clásica es una perturbación autosostenible en un medio, que se mueve a través del espacio transformando energía y momentum. Su representación matemática da lugar a una ecuación diferencial parcial de una forma particular, conocida como ecuación de onda. La característica esencial del movimiento de onda es que una condición de algún tipo se trasmite de un lugar a otro donde el medio no se transporta. La propagación o ondas viajeras, la perturbación de las ondas debe moverse de un lugar a otro, llevando energía con ella. Pero la combinación de ondas periódicas puede sumar perturbaciones no periódicas, como un pulso de onda. Las ondas armónicas son funciones seno, en el espacio y el tiempo.
Ecuación de onda clásica
Así que mientras que la ecuación de onda de primer orden se aplica a las ondas que viajan en una dirección, la ecuación de onda de segundo orden toma la misma forma que las ondas que viajan en la dirección x positiva o en la dirección x negativa. Aunque utilizamos funciones sinusoidales para demostrar este concepto, el resultado es general y se aplica a las ondas de cualquier perfil.
La ruta directa a la ecuación de primer y segundo orden para las ondas sinusoidales se basa en las derivadas de una función de onda
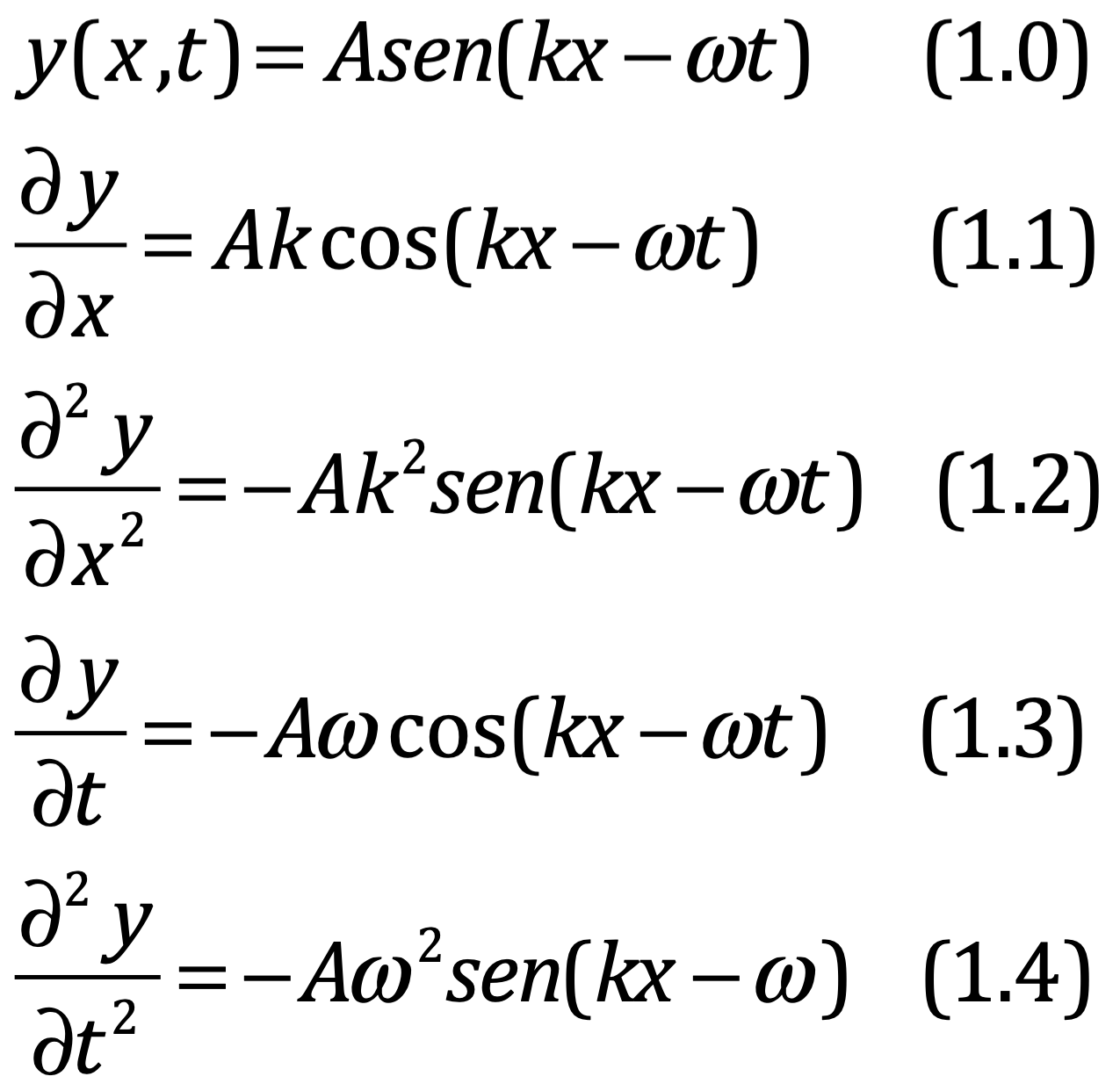
Podemos llegar a la ecuación de onda de primer orden resolviendo (1.3) para
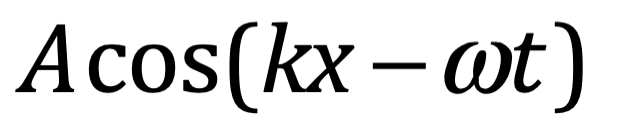
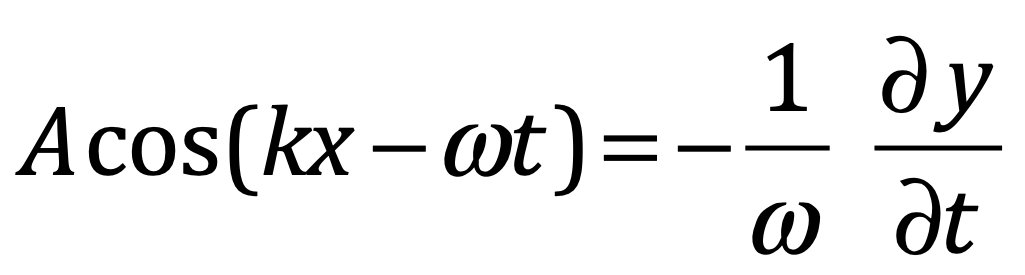
Sustituimos en (1.1)
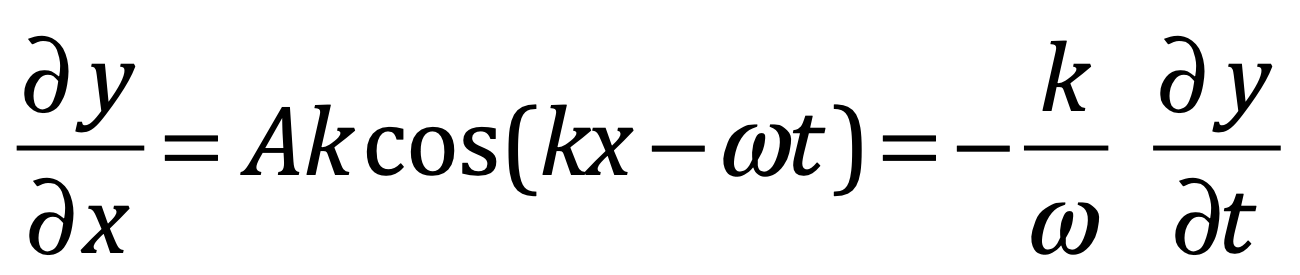
Usamos la relación 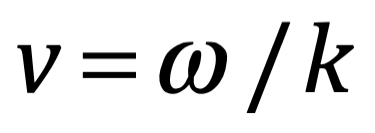 hace que
hace que
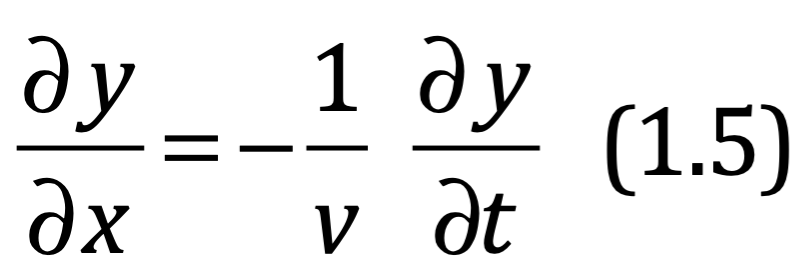
Realizando un análisis similar en las ecuaciones (1.2) y (1.4) se produce la ecuación de segundo orden clásica. Primero resolver (1.4) para 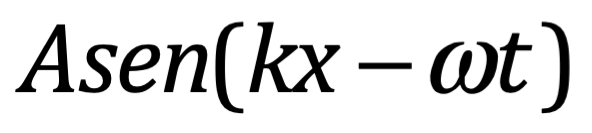
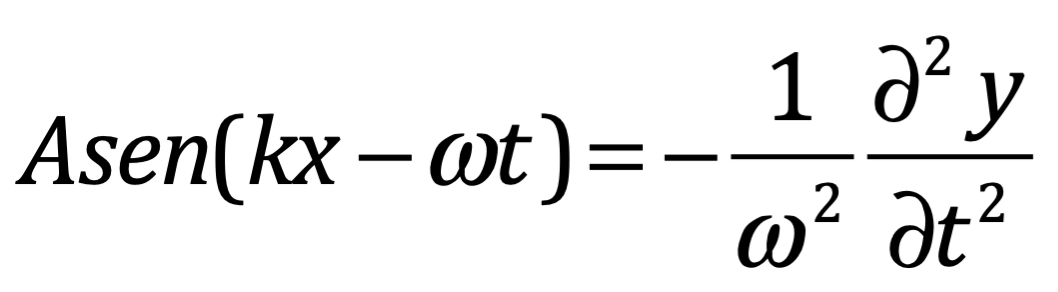
Luego sustituimos en (1.2)
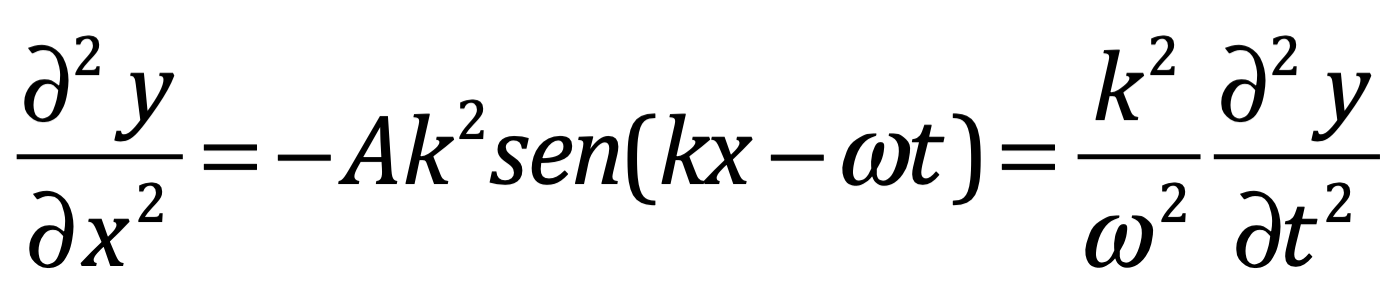
Una vez más utilizamos la relación 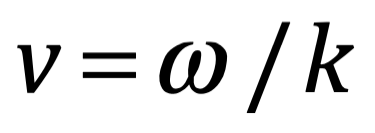 da
da
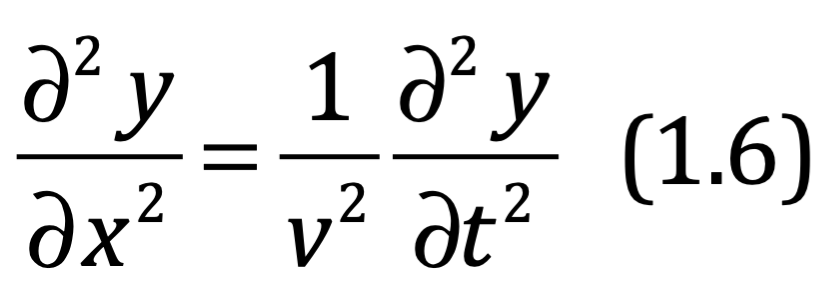
Que es la ecuación clásica de onda de segundo orden (1.6), si comenzamos con

llegamos a mismo resultado. Una vez más, aunque utilizamos armónicos (sinusoidal). La ecuación de onda clásica se puede extender a dimensiones más altas mediante la adición de derivadas parciales en otras direcciones.
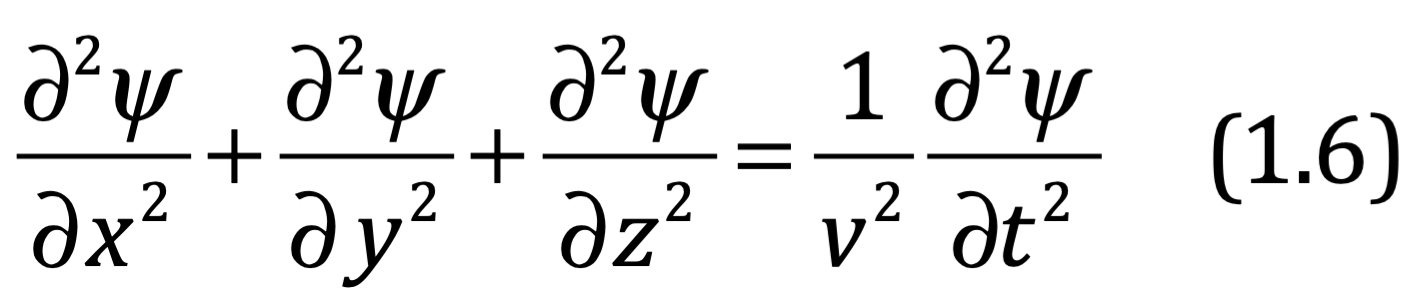
Esto se puede ver como
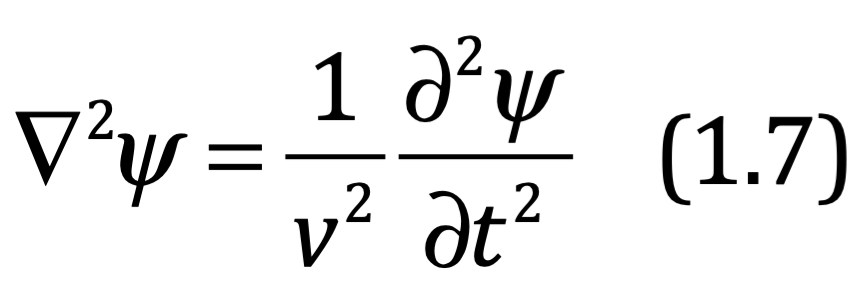
Representa el operador Laplaciano.
Independientemente de la forma que la encuentre, recordemos que la ecuación de onda nos indica el cambio en la pendiente de la forma de onda sobre la distancia, es igual a 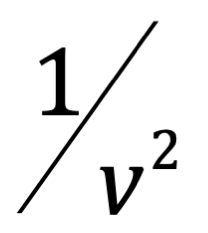 veces el cambio en la pendiente de la función de onda en el tiempo.
veces el cambio en la pendiente de la función de onda en el tiempo.
La ecuación de onda clásica es homogénea porque contiene solo términos que implican la variable dependiente (en este caso el desplazamiento y) o derivadas de la variables dependientes (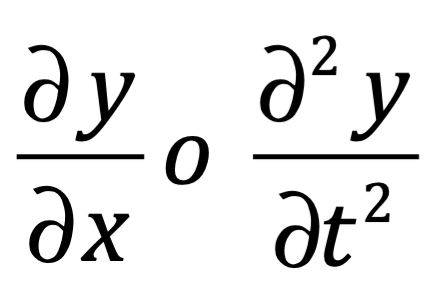 ) Matemáticamente se expresa:
) Matemáticamente se expresa:
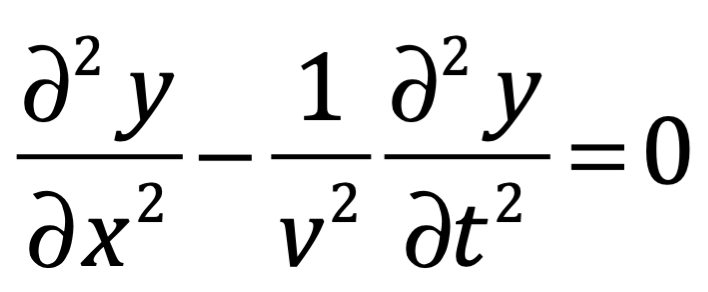
Caso no homogéneo
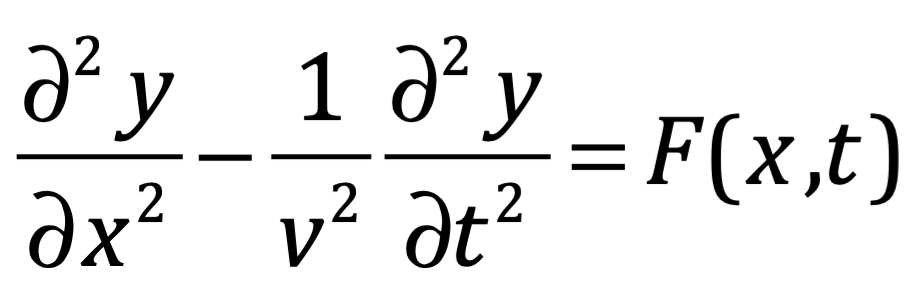
Una característica extremadamente poderosa de todas las ecuaciones diferenciales lineales, incluía la ecuación de onda clásica, es que las soluciones obedecen al principio de superposición. Este principio describe lo que sucede cuando dos o más ondas ocupan el mismo tiempo y el mismo espacio. Este es comportamiento muy distinto al que sucede con objetos sólidos. Cuando los objetos sólidos intentan ocupar al mismo tiempo un mismo espacio se producen choques que alteran sus movimientos o formas, pero cada objeto tiene que conservar su identidad. Por contrario, cuando las ondas lineales ocupan simultáneamente el mismo lugar, sus desplazamientos en el equilibrio se combinan para producir una nueva onda que también satisface la ecuación de onda. La ecuación de onda clásica es lineal porque todos los términos que implican estas f(x,t) y sus derivadas se elevan a la primera potencia. Ninguna de las ondas se destruye en este proceso, aunque solo la onda combinada es observable durante la interacción. Si las ondas se propagan lejos de la región de superposición, las características originales de cada onda son de nuevo observables. Por lo tanto, a diferencia de las particulares, las ondas pueden pasar entre sí en lugar de colisionar, produciendo una nueva onda mientras se superponen.
El principio de superposición explica por qué sucede esto. Matemáticamente, el principio para dos ondas
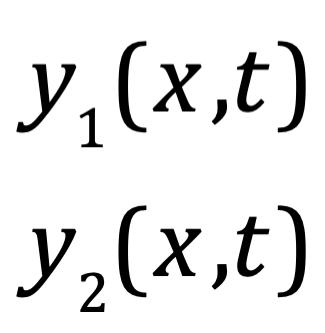
Cada una solución de la ecuación de onda lineal, entonces su suma en cada punto en el espacio tiempo total es
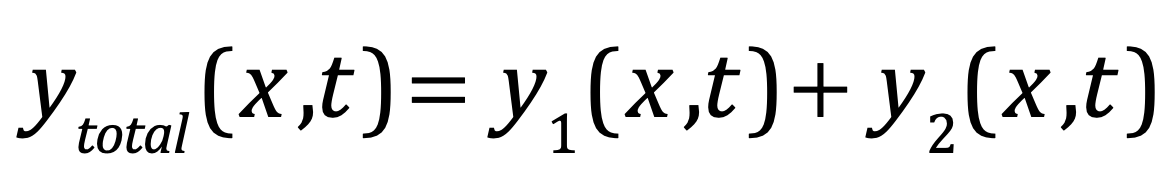
También solución de la ecuación de onda clásica.
Demostración
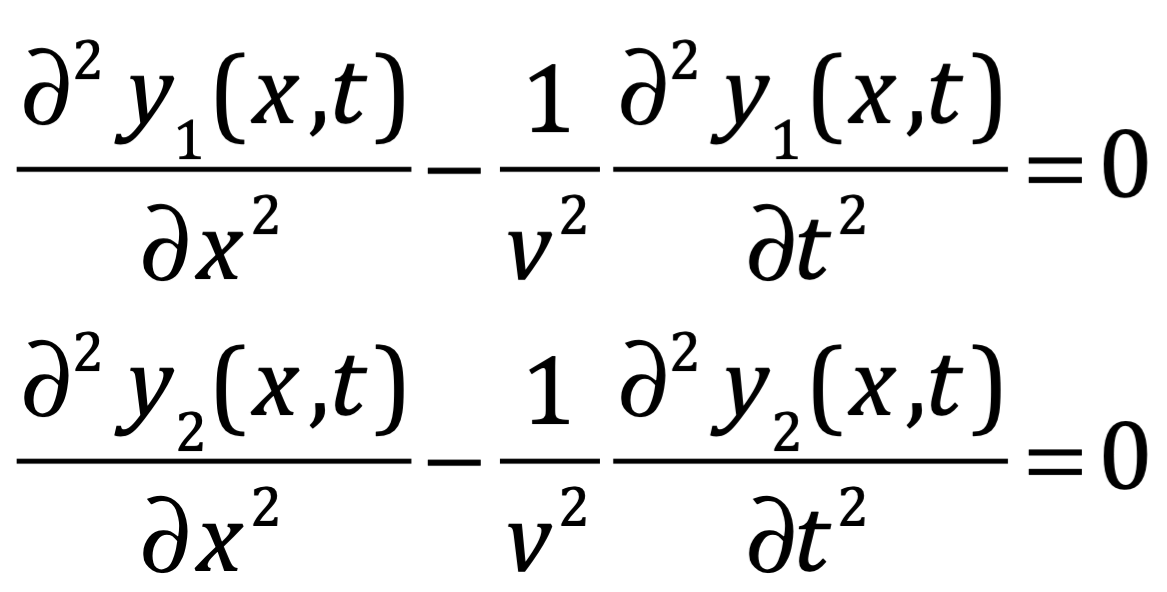
Sumas
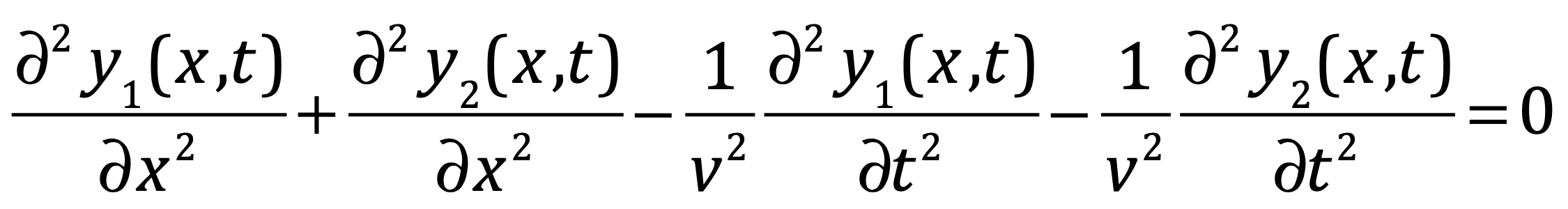
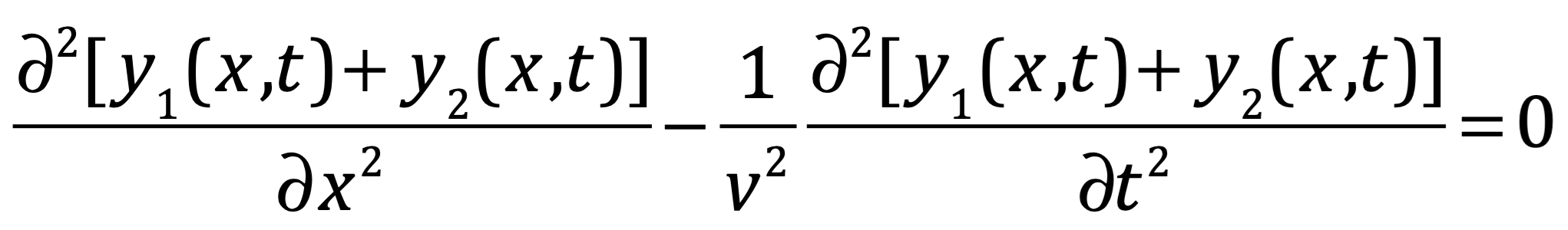
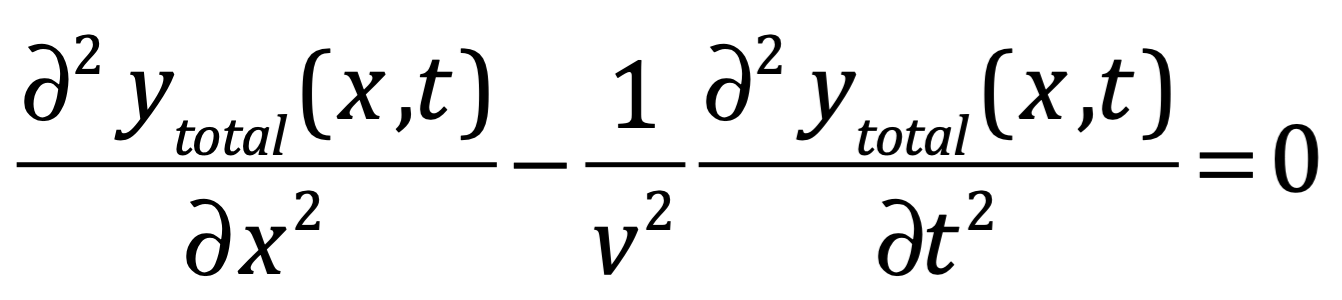
Por lo tanto, el resultado de agregar dos o más ondas que satisfacen la ecuación de onda es otra onda que también satisface la ecuación de onda. Y si estás preguntando si esto funciona cuando las ondas están viajando a diferentes velocidades, la respuesta es sí.
Ecuación de onda electromagnética
 12.37.24.png)
I) Ley de Gauss’s para el campo eléctrico:
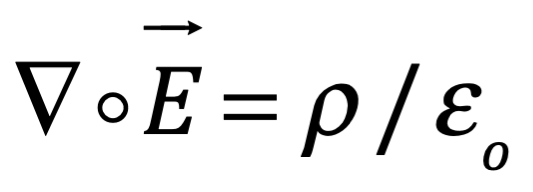
La divergencia del campo eléctrico en cualquier lugar es proporcional a la densidad de carga eléctrica en ese lugar 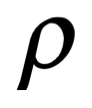 . Esto se debe a que las líneas de campo electrostáticas comienzan en la carga positiva y terminan en la carga negativa (de aquí que las líneas de campo tienden a divergir de la ubicación positiva y convergen en la ubicación de carga negativa). El símbolo
. Esto se debe a que las líneas de campo electrostáticas comienzan en la carga positiva y terminan en la carga negativa (de aquí que las líneas de campo tienden a divergir de la ubicación positiva y convergen en la ubicación de carga negativa). El símbolo  representa la permeabilidad eléctrica del espacio libre, una cantidad que tiene que ver con la impedancia de ondas electromagnéticas.
representa la permeabilidad eléctrica del espacio libre, una cantidad que tiene que ver con la impedancia de ondas electromagnéticas.
II) Ley de Gauss para campos magnéticos:
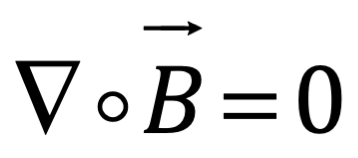
Dice que la divergencia del campo magnético en cualquier lugar debe ser igual a cero. Esto es cierto, porque aparentemente no hay una carga magnética aislada en el universo, por lo que las líneas de campo magnético no divergen ni convergen (circulan sobre sí mismas).
III) Ley de Faraday:
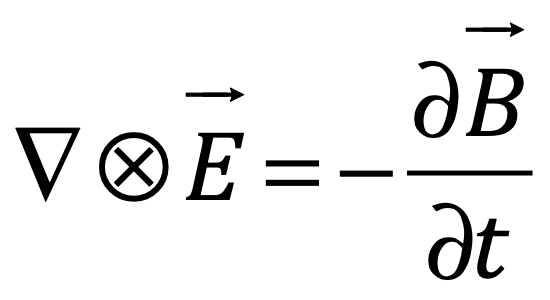
Indica que el producto cruz vectorial sobre el campo eléctrico en cualquier ubicación, es igual al negativo de la tasa de tiempo del campo negativo en esa ubicación. Esto se debe a que, un campo magnético cambiante produce un campo eléctrico.
IV) Ley de Amper-Maxwell:
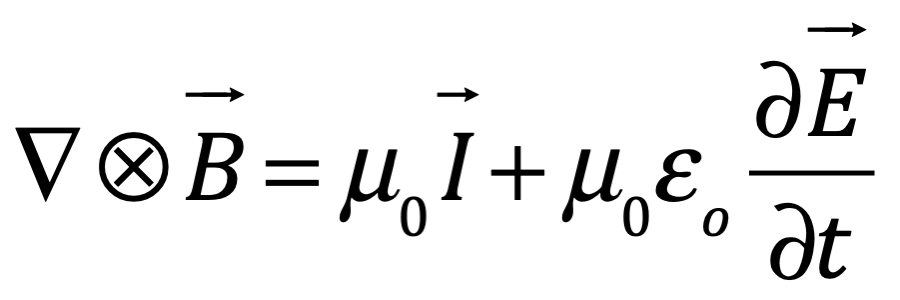
La ley de Amper modificada por Maxwell, dice que el producto cruz del campo magnético en cualquier ubicación es proporcional a la densidad de corriente eléctrica, más la tasa de tiempo de cambio del campo eléctrico en esa ubicación. Este es el caso porque un flujo magnético de campo es producido tanto por una corriente eléctrica como por un campo eléctrico cambiante. El símbolo 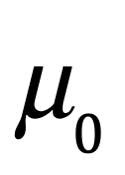 representa la permeabilidad magnética del espacio libre, cantidad que vera con al velocidad de fase de la ondas electromagnéticas y al impudencia electromagnética.
representa la permeabilidad magnética del espacio libre, cantidad que vera con al velocidad de fase de la ondas electromagnéticas y al impudencia electromagnética.
Observe que las ecuaciones de Maxwell relacionan el comportamiento espacial de los campos con los orígenes de esos campos. Estas fuentes son densidades de carga eléctrica  que aparecen en la ley de Ampere-Maxwell y el cambio del campo eléctrico.
que aparecen en la ley de Ampere-Maxwell y el cambio del campo eléctrico.
Tomadas individualmente a las ecuaciones de Maxwell proporcionan relaciones importantes entre las fuentes de campos eléctricos y magnéticos y el comportamiento de esos campos. Pero el verdadero poder de esta ecuaciones se realiza en su combinación para producir la ecuación de onda electromagnética.
Comencemos por producto cruz del en ambos lados de la ley de Faraday:
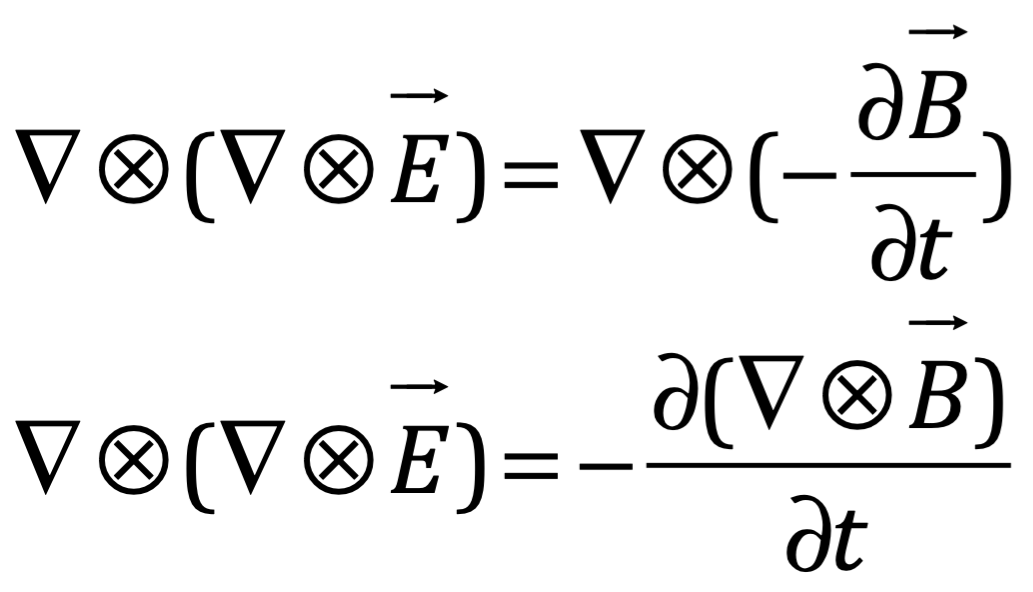
En el que la inserción de la expresión para el producto cruz del campo magnético 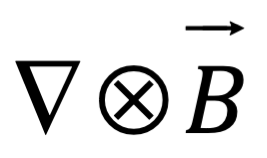 de la ley de Amper-Maxwell hace que
de la ley de Amper-Maxwell hace que
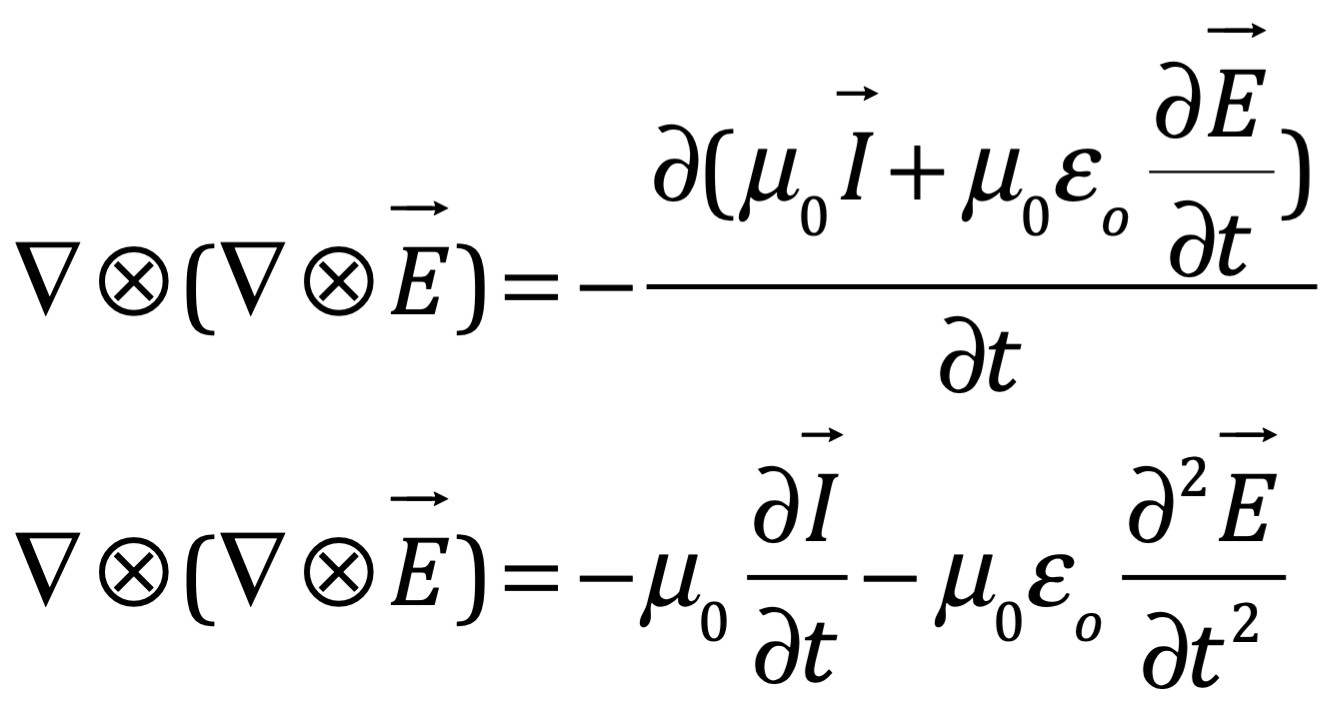
Finalmente requerimos el uso de la identidad vectorial para el producto cruz de una función
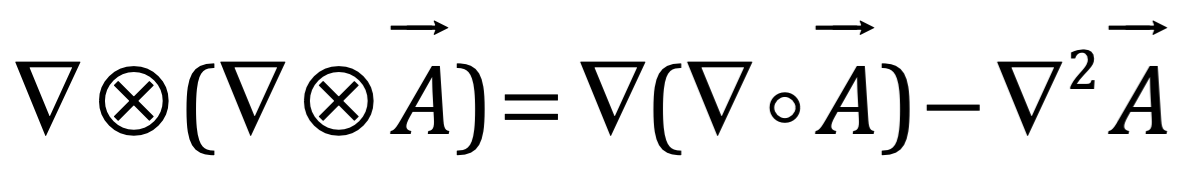
Donde 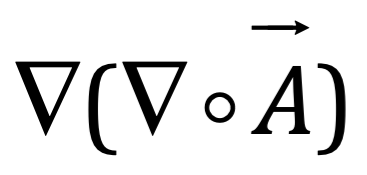 es el gradiente del divergente de
es el gradiente del divergente de  y
y 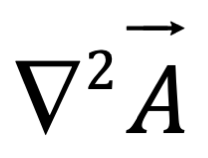 el Laplaciano de
el Laplaciano de  , aplicando esta identidad a la ecuación anterior:
, aplicando esta identidad a la ecuación anterior:
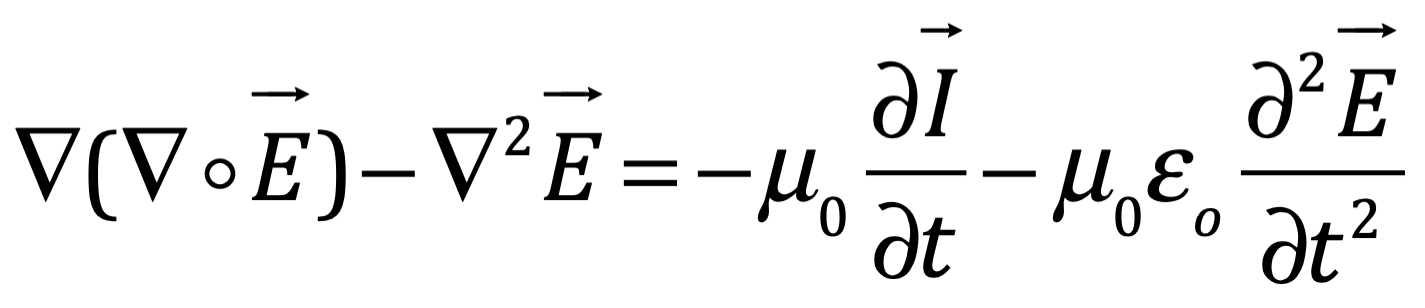
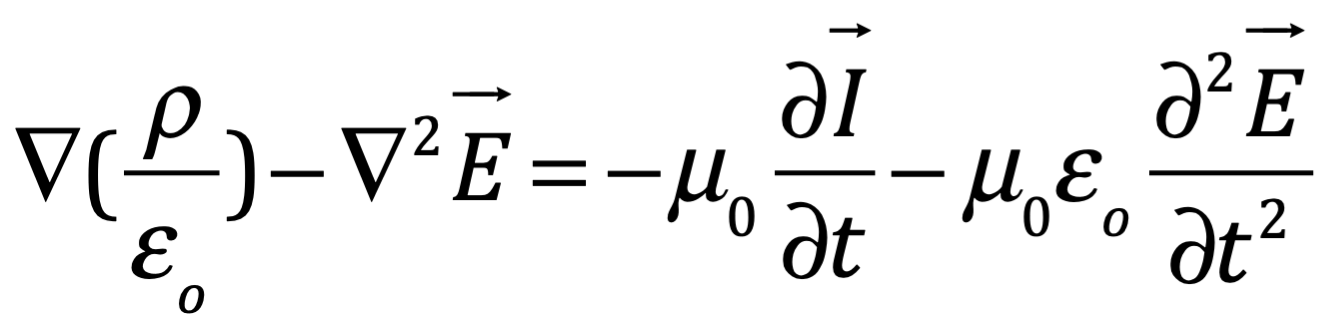
En el vacío la densidad de carga y la densidad de corriente son cero.
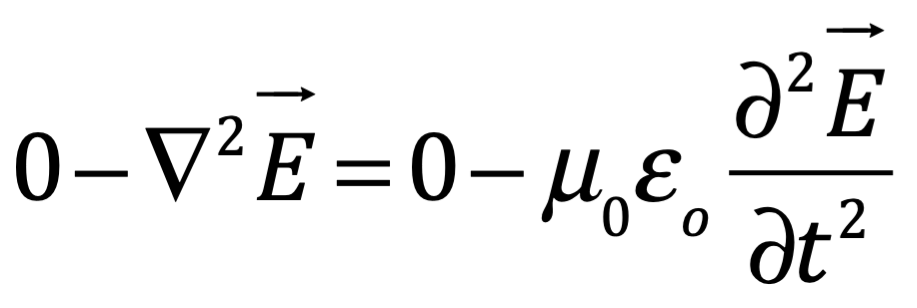
Y por tanto la ecuación de onda para el campo eléctrico es:
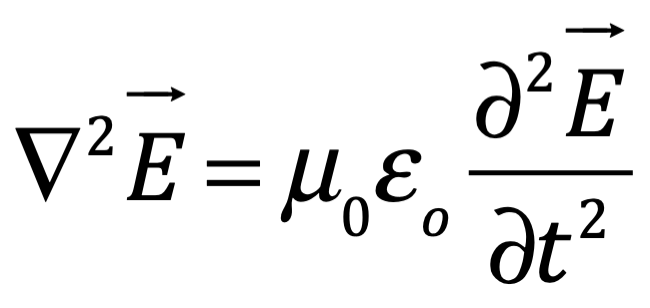
dado que se trata de una ecuación vectorial, en realidad se trata de tres ecuaciones separadas, una para cada componente del vector. En coordenadas cartesianas esas ecuaciones son:
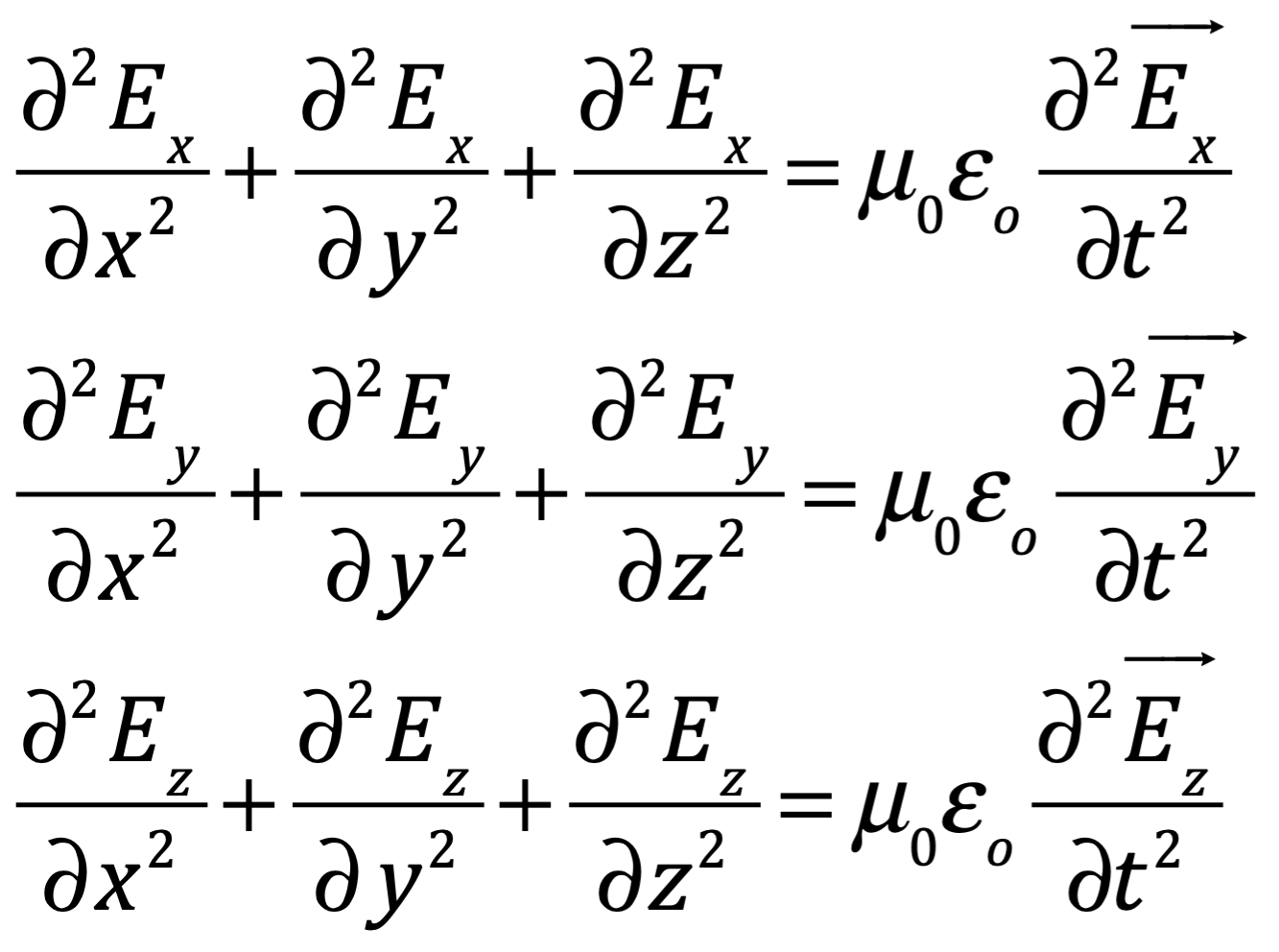
Podemos encontrar de forma equivalente para el campo magnético tomando del producto cruz de ambos lados de la ley de Amper-Maxwell y luego insertando el producto cruz de la ley de Faraday. Esto da
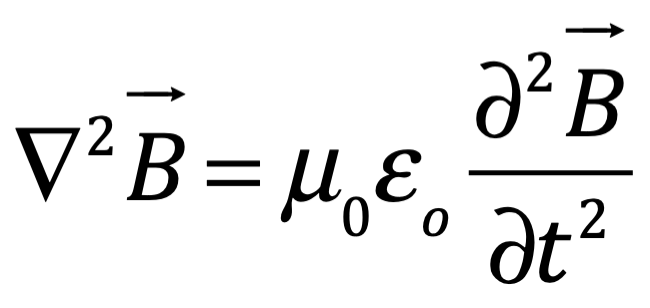
Esta también es una ecuación vectorial:
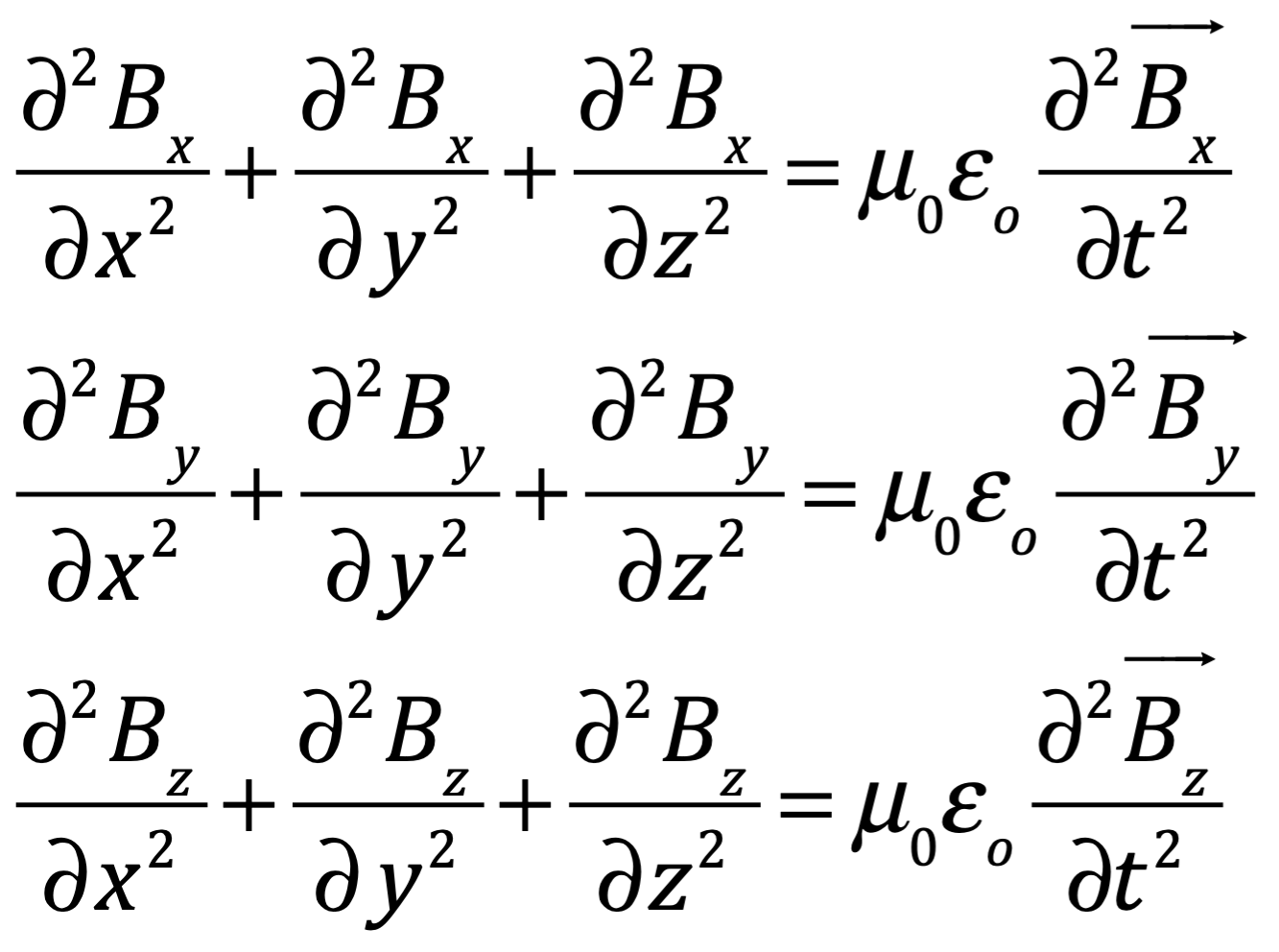
La ecuación general de propagación de onda comparandolas con las ondas electromagnéticas:
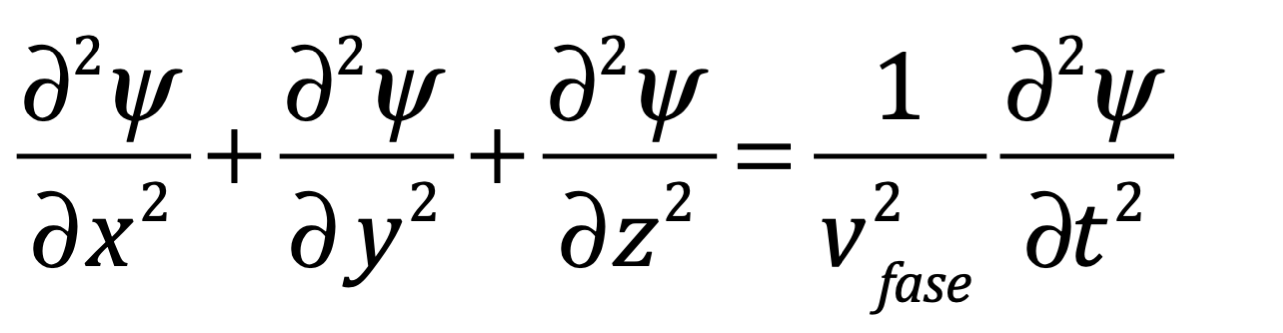
La equiparación de los factores a los derivados del tiempo revela que la velocidad de fase de las ondas electromagnéticas es:
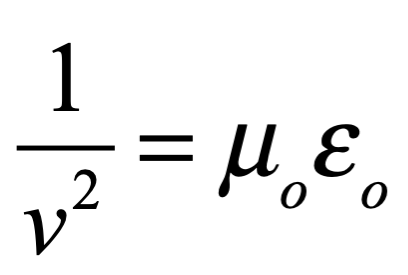

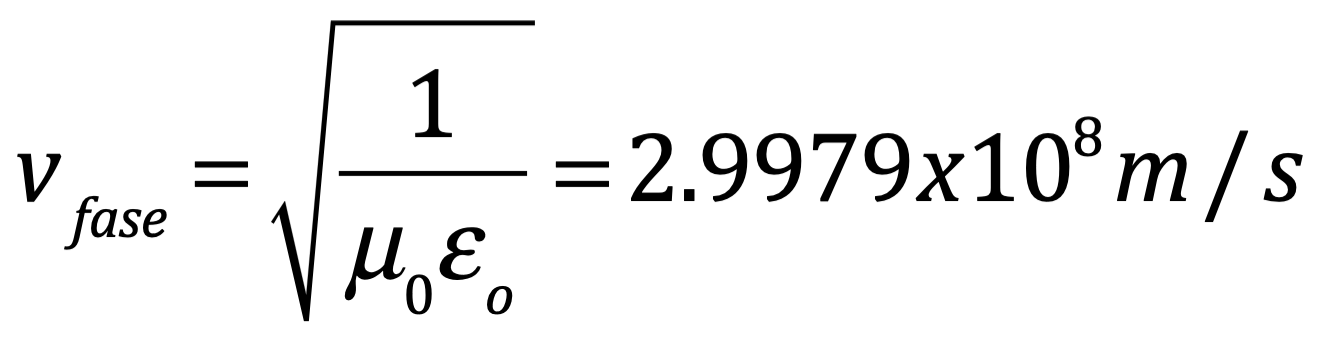
Esta es la velocidad de la luz en el vacío, un resultado sorprendente que hizo Maxwell que concluyera que la luz es una perturbación electromagnética con límite cosmológico para su propagación en nuestro universo. Las ondas electromagnéticas deben satisfacer no solo la ecuación de onda, sino también las ecuaciones de Maxwell dado que se generan en átomos con restricciones de cuantización para estas.

Se puede observar a Thomson el cuarto por la izquierda de la fila inferior, situado entre Wilhelm Wien y Emil Warburg. Congreso Solvay (1913)
Evaluación 14__________
6.24 Campos microscópico y macroscópicos
He sido descuidado con la distinción entre dipolos «puros» y dipolos «físicos». Al desarrollar la teoría de cargas ligadas, supusimos que trabajábamos con el tipo puro; de hecho, comenzamos con la ecuación
 10.45.30a.m.png)
para el potencial de un dipolo perfecto. Y, sin embargo, un dieléctrico polarizado real consiste en dipolos físicos, aunque extremadamente pequeños. Además, asumimos que podíamos representar dipolos moleculares discretos mediante una función de densidad continua P. ¿Cómo podemos justificar este método? Fuera del dieléctrico no hay un problema real: allí estamos lejos de las moléculas (a distancias muchas veces mayores que la separación entre las cargas positiva y negativa), por lo que el potencial dipolar domina abrumadoramente y la “granularidad»”detallada de la fuente se difumina con la distancia. Sin embargo, dentro del dieléctrico difícilmente podemos pretender estar lejos de todos los dipolos, y el procedimiento que utilizamos queda abierto a un serio desafío.
De hecho, si te detienes a pensarlo, el campo eléctrico dentro de la materia debe de ser fantásticamente complicado a nivel microscópico. Si estás muy cerca de un electrón, el campo es gigantesco, mientras que a poca distancia puede ser pequeño o apuntar en una dirección totalmente diferente. Además, un instante después, cuando las cargas se muevan, el campo habrá cambiado por completo. Este verdadero campo microscópico sería totalmente imposible de calcular; y, aun si pudieras, no te interesaría demasiado. Así como, para fines macroscópicos, consideramos el agua como un fluido continuo, ignorando su estructura molecular, también podemos ignorar las irregularidades microscópicas del campo eléctrico dentro de la materia y concentrarnos en el campo macroscópico. Este se define como el campo medio sobre regiones lo suficientemente grandes como para contener miles de átomos, de modo que las fluctuaciones microscópicas poco relevantes se suavizan y, sin embargo, lo suficientemente pequeñas como para evitar que se eliminen variaciones significativas a gran escala en el campo. En la práctica, esto significa que debemos promediar sobre regiones mucho menores que las dimensiones del propio objeto. Normalmente, el campo macroscópico es al que se hace referencia cuando se habla de “campo” dentro de la materia. Es decir, aquí aparece con claridad una de las claves conceptuales del electromagnetismo en medios: el campo que usamos no es el “real” en sentido microscópico, sino un campo promediado, una construcción teórica que filtra el ruido para dejar visible la estructura.
Pero ¿es realmente el campo macroscópico lo que obtenemos cuando usamos los métodos de cargas ligadas? El argumento es sutil, así que presta atención. Supongamos que queremos calcular el campo macroscópico en algún punto r dentro de un dieléctrico.
Sé que debo promediar el campo verdadero (microscópico) sobre un volumen apropiado, así que déjame imaginar una pequeña esfera alrededor de r, de radio, digamos, mil veces el tamaño de una molécula. El campo macroscópico en r, entonces, consta de dos partes: el campo medio sobre la esfera debido a todas las cargas exteriores, más el promedio debido a todas las cargas interiores:
 11.33.22a.m.png)
El campo medio sobre una esfera, producido por cargas exteriores, es igual al campo producen en el centro, por lo que Eout es el campo en r debido a los dipolos exteriores de la esfera. Están lo suficiente lejos como para que podamos usar seguridad de la ecuación:
 11.36.58a.m.png)
Lo dipolos dentro de la esfera están demasiado cerca para tratarlos de esta manera. Pero afortunadamente solo necesitamos su campo medio, y que, según:
 11.38.07a.m.png)
Independientemente de los detalles de la distribución de carga dentro de la esfera. La única cantidad relevante es el momento dipolar total;
 11.39.50a.m.png)
 11.40.23a.m.png)
Ahora, por supuesto, la esfera es lo suficientemente pequeña como para que P no varía significativamente en su volumen, por lo que el término omitido en la integral
 11.42.02a.m.png)
Corresponde al campo en el centro de una esfera polarizada uniformemente, es decir,
 11.43.36a.m.png)
Pero esto es precisamente lo que Ein devuelve a poner. El campo macroscópico, entonces, esta dado por el potencial:
 11.43.50a.m.png)
Donde la integral recorre todo el volumen del dieléctrico. Esto es exactamente lo que usamos en el método de cargas ligadas; sin darnos cuenta, estábamos calculando correctamente el campo macroscópico promedio para puntos dentro del dieléctrico.
Puede que tengas que releer los últimos apartados para que el argumento cale bien. Observa que todo gira en torno al curioso hecho de que el campo medio sobre cualquier esfera, debido a la carga interior, es el mismo que el campo en el centro de una esfera polarizada uniformemente con el mismo momento dipolar total. Esto significa que, por muy caótica que sea la configuración real de carga microscópica, podemos reemplazarla por una distribución suave de dipolos perfectos si solo queremos el campo macroscópico (promedio).
Por cierto, aunque el argumento aparentemente se basa en la forma esférica que elegí para promediar, el campo macroscópico es, en realidad, independiente de la geometría de la región de promediado, y esto se refleja en el resultado final:
 11.56.40a.m.png)
Presumiblemente se podría reproducir el mismo argumento para un cubo, un elipsoide o lo que sea; el cálculo podría ser más difícil, pero la conclusión sería la misma.
6.25 La constante de Planck (h)
En los siglos transcurridos desde el Principia de Newton, los científicos descubrieron numerosos fenómenos que debían encajar en aquel gran diseño mecánico del universo. La electricidad fue uno de ellos. El científico francés Charles Coulomb y otros investigadores estudiaron las fuerzas eléctricas de repulsión y atracción siguiendo el modelo de la ley universal de la gravitación de Newton. Descubrieron que la fuerza entre dos cargas eléctricas es proporcional al producto de dichas cargas e inversamente proporcional al cuadrado de la distancia que las separa. Allí surge el concepto de campo: una magnitud que adquiere un valor específico en cada punto del espacio y del tiempo, ampliando de manera decisiva el alcance explicativo de la mecánica newtoniana. Más tarde, otros científicos demostraron que corrientes eléctricas variables producen campos magnéticos cambiantes, estableciendo así un vínculo profundo entre electricidad y magnetismo; fue James Clerk Maxwell quien culminó la formulación teórica de este edificio conceptual.
Sin embargo, conforme avanzaban tanto la teoría como sus aplicaciones, comenzó a parecer que el universo no era una relojería estrictamente newtoniana. Los científicos advirtieron que el mundo contenía comportamientos que revelaban el azar en su estructura. Desde la geología hasta la termodinámica y el estudio del comportamiento de los gases, se desarrollaron métodos para describir procesos irreversibles y herramientas estadísticas para calcular la incertidumbre. Se trataba de lo que los filósofos denominan incertidumbre epistemológica: incertidumbre acerca de lo que sabemos sobre los fenómenos, y no incertidumbre ontológica, es decir, acerca de la naturaleza misma de la realidad.
Cuando la teoría cuántica apareció por primera vez en 1900, lo hizo aún dentro del territorio conceptual newtoniano; fue identificada precisamente porque representaba una desviación respecto de las expectativas clásicas sobre el comportamiento de la luz en circunstancias específicas. El mundo cuántico emergió inicialmente como una anomalía frente al mundo newtoniano. Durante algún tiempo, los científicos esperaron que estos nuevos hechos terminaran por integrarse en el gran diseño, del mismo modo en que lo habían hecho los fenómenos anteriores.
Pero cuando los investigadores comenzaron a observar el mundo subatómico, por así decirlo, fotograma a fotograma, encontraron una discontinuidad extraña y una sucesión de acontecimientos gobernados por el azar. Sabían también que la experiencia humana no es completamente ajena a ese carácter imprevisible: nuestro mundo no siempre se presenta como suave, continuo y regido por leyes estrictamente deterministas. El universo contemporáneo ya no posee la geometría sólida del cosmos newtoniano; se asemeja más a la superficie de un agua en ebullición. Así, el mundo newtoniano —estable y convincente durante más de dos siglos— comenzó a perforarse por sus propias lagunas e inconsistencias, incapaz de explicar esas “burbujas” que emergían de lo real.
Para comprender cómo ocurrió esta transformación, es necesario detenerse brevemente en la vida de Max Planck (1858–1947), quien introdujo el concepto de cuanto en la física. Temperamentalmente, era uno de los científicos más conservadores de su tiempo y no tenía intención alguna de convertirse en un revolucionario. Aprendió a mantener un perfil discreto para sobrevivir a épocas turbulentas marcadas por la guerra. Cuando tenía cincuenta años, vivía en Berlín y presenció la derrota de Alemania en la Primera Guerra Mundial; a los sesenta y cuatro años se encontraba también en Berlín cuando los nazis tomaron el poder. Sobrevivió a numerosas tragedias personales: uno de sus hijos fue ejecutado por los nazis tras participar en la resistencia contra Hitler, y su casa fue destruida por los bombardeos aliados. No era judío, pero el terror del régimen no distinguía con indulgencia. Pero Planck logró sobrevivir en Alemania a través de la guerra por permanecer en perfil bajo, frente al conflicto[3].
Científicamente, Planck también era conservador. En su juventud estaba fuertemente atraído a la ciencia porque le permitió estudiar un mundo que era absoluto e independiente de las acciones humanas. La ciencia ofrece un maravilloso refugio ante las matanzas de las guerras en el mundo. Cuando él era un estudiante en Múnich, uno de sus profesores le desanima a esta sublime búsqueda, diciéndole, en física, “casi todo está ya descubierto y todo lo que queda es rellenar unos agujeros”. Él pensó que podría llenar esos agujeros y barrer esos rincones polvorientos de la física[4].
Cuan irónico es que este hombre, que pretende poner en orden los extremos sueltos de la física, sería al introducir una idea nueva, quien pone a temblar hasta sus cimientos más profundos el conocimiento newtoniano. Lo hizo mientras trabajaba en el primer laboratorio de pesas y medidas en el mundo. El gobierno alemán le encomendó calificar la bombilla de luz, ante la necesidad de analizar lo que sucede cuando materiales absorben toda la luz que reside en ellos y luego la vuelven a emitir en una distribución uniforme de colores. Materiales en esa condición, se perciben como los mejores amortiguadores de luz y que fueron bautizados como “cuerpos negros” por el maestro de Planck, Gustav Kirchhoff. Le fue encomendada la tarea de investigación de la radiación de un cuerpo negro para producir una fórmula que describa su espectro normal, en cuanto a su perfil, intensidades y frecuencias de variación por temperatura[5].
Planck, que en 1892 relevo a Kirchhoff como profesor en Berlín, le gustaba este problema. Por un lado, él quería responder al interés nacional de esta investigación. Por otra parte, él fue preparado, para el problema en sus estudios anteriores. Por último, el hecho de que el resplandor dependía solamente de la temperatura del material y no de su composición química, sugirió que la solución sería fundamental –similar a la forma en que la naturaleza fundamental de la fuerza gravitatoria depende exclusivamente de lo masivo del objeto-. Ya que siempre Planck consideró la meta de lo absoluto, como la meta más alta de la actividad científica.
Planck descubrió que podía producir una fórmula para los datos de Reichanstalt, el supone que los materiales absorben y emiten luz selectivamente, solo en números enteros múltiplos de una determinada cantidad de energía que llamo 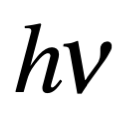 , donde
, donde 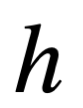 es la constante que lleva el nombre de Planck , y v es la frecuencia de la radiación. Si E es la energía, y n un número entero, la fórmula de radiación de Planck es
es la constante que lleva el nombre de Planck , y v es la frecuencia de la radiación. Si E es la energía, y n un número entero, la fórmula de radiación de Planck es 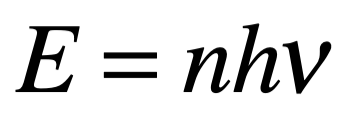 . Planck dijo que hizo esta asunción por pura desesperación. No fue una explicación sino un truco matemático, se dio cuenta, y pensó que finalmente se podría desechar la idea. Pocos prestaron atención a la idea de Planck. Una excepción, tan solo cincuenta años más tarde, fue hecha por un empleado de oficina de patentes de 20 años de edad, conocido como Albert Einstein, al que le valió el premio Nobel por explicar el efecto fotoeléctrico. Einstein explica la fórmula de Planck por una sugerencia radical que considera a la energía de la luz en sí misma, que viene dada en múltiplos de h. Es decir, en quantums de energía de luz, se reconocería más tarde como fotón. En definitiva, el quantum era un truco matemático, como Planck lo hizo, pero con Einstein fue una realidad física. Esto era muy revolucionario. Pocos tomaron en serio la idea de Einstein. Pero para 1910, en el interés de los físicos en la cuántica se hacia una fisura. La razón fue que todos los intentos por eliminar la necesidad de hacerlo así y reconciliar todo con la física clásica, habían fallado. La cuántica fue surgiendo dentro de la teoría molecular de la conducción de calor en sólidos. Los científicos miran en el mundo subatómico, encontrando este invitado incomodo[6]:
. Planck dijo que hizo esta asunción por pura desesperación. No fue una explicación sino un truco matemático, se dio cuenta, y pensó que finalmente se podría desechar la idea. Pocos prestaron atención a la idea de Planck. Una excepción, tan solo cincuenta años más tarde, fue hecha por un empleado de oficina de patentes de 20 años de edad, conocido como Albert Einstein, al que le valió el premio Nobel por explicar el efecto fotoeléctrico. Einstein explica la fórmula de Planck por una sugerencia radical que considera a la energía de la luz en sí misma, que viene dada en múltiplos de h. Es decir, en quantums de energía de luz, se reconocería más tarde como fotón. En definitiva, el quantum era un truco matemático, como Planck lo hizo, pero con Einstein fue una realidad física. Esto era muy revolucionario. Pocos tomaron en serio la idea de Einstein. Pero para 1910, en el interés de los físicos en la cuántica se hacia una fisura. La razón fue que todos los intentos por eliminar la necesidad de hacerlo así y reconciliar todo con la física clásica, habían fallado. La cuántica fue surgiendo dentro de la teoría molecular de la conducción de calor en sólidos. Los científicos miran en el mundo subatómico, encontrando este invitado incomodo[6]: 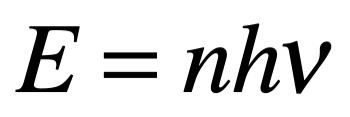 .
.
En 1911, un grupo de veintiún líderes científicos de Europa, se reunieron en Bruselas para una cumbre sobre la cuántica. Organizada por el químico y físico Walther Nernst. El propio Nernst había rechazado la idea cuántica y luego admitió que era indispensable como hombre serio de ciencia sujetarse a la investigación cuidadosa. Esta conferencia de Solvay Brúcelas de 1911 fue un punto de inflexión en la respetabilidad de la cuántica, se hace noticia en todo el mundo, Rutherford la llevo a Inglaterra, a Dinamarca lo hizo Niels Bohr, a Francia Henri Poincaré.
Robert A. Millikan (1868-1953), de la universidad de Chicago, estaba decidido a ayudar a sus colegas estadounidenses a conciliar el sueño, intentaría matar la idea cuántica al modo de hacer experimentos de vanguardia y poner a prueba las predicciones que en papel en 1904 Einstein realizó. Millikan fue sorprendido por sus experimentos, confirmándole cada una de las predicciones de Einstein. Su asombro y consternación quedo exhibido en su artículo que anunció los resultados. Se vio obligado a admitir que la teoría cuántica de Einstein realmente representa muy exactamente el efecto fotoeléctrico[7].
Mientras tanto la cuántica surge con nuevas explicaciones de fenómenos subatómicos. En 1913-14, el joven físico Niels Bohr estaba interesado en esto, porque su doctorado demostró que la física clásica no podía explicar las propiedades electromagnéticas de los metales, aplicando a átomos de una gran variedad haciendo surgir con fuerza la física atómica. La teoría clásica predice que al moverse los electrones en órbita alrededor del núcleo irradian energía y colapsan en el núcleo. Bohr demostró que si se asume el momento angular para las órbitas de los electrones en múltiplos de una nueva unidad natural  , entonces los electrones no tienen un número infinito de posibles órbitas alrededor del núcleo como planetas alrededor del sol, es decir, solamente una sección pequeña encaja, fue un resultado dramáticamente coherente con la evidencia experimental[8].
, entonces los electrones no tienen un número infinito de posibles órbitas alrededor del núcleo como planetas alrededor del sol, es decir, solamente una sección pequeña encaja, fue un resultado dramáticamente coherente con la evidencia experimental[8].
Otro fenómeno descubierto aproximadamente al mismo tiempo era el efecto Stark, o el hecho de que las líneas espectrales están divididas por un campo eléctrico. El efecto fue descubierto en 1913 y explicado por la teoría cuántica en un artículo de 1916. Si bien el experimento de Millikan sirvió como punto de inflexión en la recepción de la teoría cuántica, Max Jammer, historiador de ciencia escribió: la cuántica se convirtió en física real accesible directamente al experimentador y la conjetura de Einstein sobre el quantum, fue dotada de significado físico y un fundamento experimental a partir del efecto Stark[9].
Todas estas discusiones se llevaron a cabo dentro de la comunidad de la física, con poca participación de la opinión pública. El leguaje ordinario continuó utilizando el quantum en su significado de “cantidad”, que podría ser grande o pequeña y hasta insignificante. No en el sentido de Planck como una cantidad finita, de alguna magnitud suficiente para marcar una diferencia estructural importante. Las noticias fueron que Planck fue galardonado con el Premio Nobel en 1918 en reconocimiento por los servicios prestados al avance de la física por su descubrimiento de la energía cuántica. En 1919 Einstein se convirtió en renombrado científico al confirmarse las predicciones de su teoría de la relatividad general, y fue más aún a pesar de que recibió el Premio Nobel en 1912 por su descubrimiento de la ley del efecto fotoeléctrico, es decir, por su contribución a la teoría cuántica. Y en 1923 Millikan recibió el Nobel por su trabajo sobre la carga eléctrica elemental y sobre la experimentación del efecto fotoeléctrico. Ya para entonces, la prensa para las audiencias educadas mencionaría con más insistencia la idea de Planck: se ha descubierto un mundo que no era continuo en el sentido de lo expresado por el pensamiento de Newton.
La ecuación de Planck, para 1930 se vuelve famosa por los libros de divulgación científica y artículos que inundan los medios, transformando la historia de la ciencia. La comunidad reconoce en Planck, un nuevo Colón que nos abrió un nuevo mundo científico y una nueva cultura en sí. Planck, por supuesto, nada de esto tenía en mente; reflexiones sobre las implicaciones de su concepción científica en el arte, cine y literatura se multiplicaron. En 1947, el último año de su vida, Planck fue invitado por la Royal Society de Londres a una celebración con motivo de Newton. El evento se llevó a cabo en una gran sala, y distinguidos invitados fueron honrados uno por uno, en una página se dio lectura a sus nombres y países de una lista en voz alta. Planck fue especialmente invitado y no estaba en la lista. El lector de la página, confundido, de repente tuvo que improvisar y tropezó: “profesor Max Planck, de ningún país”, los asistentes rieron y dieron a Planck una ovación de pie, Planck con sus noventa años de edad, con dificultad se levantó para aceptar el aplauso cálido. Avergonzada, la Royal Society ha añadido a Planck a la lista de citación para el segundo día, pero Planck insistió en que fuera nombrado “desde el mundo de la ciencia[10]”.
Con la electrificación del siglo XIX y en particular con la aparición de la bombilla eléctrica, se comenzó a preguntar sobre el principio detrás de estos cuerpos que emiten calor y luz en rangos visibles y más allá. Estas gamas de luz tiene un perfil particular. Cada material irradia el mismo espectro de colores a la misma temperatura; registros con madera y piezas de cerámica todos brillan al mismo color que una barra de hierro por ejemplo. Con lámparas eléctricas fabricadas a principios de siglo XX se intentó para su diseño, que optimizaran la producción de luz blanca y redujeran las otras frecuencias. Se demostró que la intensidad de la luz emitida aumenta con la temperatura, pero el aumento no se distribuye igual a través de todas las frecuencias y cambia o es desplazado hacia longitudes de ondas más cortas, esto se le conoce como la ley de desplazamiento Wien.
Planck observó un modelo de la manera en que los materiales absorben y emiten radiación en la forma tradicional de representar a los materiales, como un conjunto de osciladores, como resortes de Hooke de flexibilidad variable. Sus índices de oscilación dependían por así decirlo, de la rigidez de los muelles. Cuando el material absorbe energía, los resortes osciladores captan más energía; cuando ellos emiten energía sus oscilaciones son menores. Un material puede tratarse como un conjunto de tales resortes de diferente rigidez para absorber y emitir energía en distintas frecuencias. En 1899 Planck estaba encantado cuando encontró que podía usar este modelo para derivar la ley de desplazamiento Wien. Pero solo un año después Reichanstalt, experimentando con hornos mide longitudes de onda más largas (infrarrojo), estos resultados están en desacuerdo con la fórmula de Wien, con una función espectral más proporcional a la temperatura, más en consonancia con la fórmula clásica, conocida más tarde como fórmula de Rayleigh-Jeans. Sobre la propia fórmula de Planck a principios de 1900 existía una suposición empírica pero sin verdadero significado físico. Fue en noviembre de 1900 que empleando termodinámica para calcular la energía distribuida entre los modelos de los resonadores, con la esperanza de obtener alguna pista fundamental, esa luz llego, levantando de la oscuridad una mirada inesperada, apareció en sus actos de desesperación. Se encontró que tenía que asumir que la energía total E es distribuida entre los N resonadores consistentes con un conjunto de 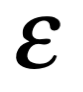 elementos de energía, cuyo valor estaba relacionado con una nueva constante fundamental de la naturaleza que llamo simplemente
elementos de energía, cuyo valor estaba relacionado con una nueva constante fundamental de la naturaleza que llamo simplemente  . Fue esta constante invocada para aplicar solamente el mecanismo de la interacción entre materia y la luz que irradia.
. Fue esta constante invocada para aplicar solamente el mecanismo de la interacción entre materia y la luz que irradia.
Las tres leyes propuestas para la radiación de un cuerpo negro radiante, radiación versus frecuencia como lo explica el siguiente gráfico. La ley Wien, que sigue la línea punteada debajo del ajuste a los datos experimentales de la radiación emitida a altas frecuencias, describiendo, a la derecha del gráfico, como picos en una frecuencia específica, que es mayor cuanto más caliente es la temperatura. La fórmula clásica, que sigue la línea punteada en la parte superior, no cupieron los datos, pero fue asumida para describir datos de frecuencia inferiores a la izquierda del gráfico. La fórmula de Planck, la línea de conexión, por lo tanto como ideal, ni demasiado grande o muy pequeña, fue justa con los datos experimentales.
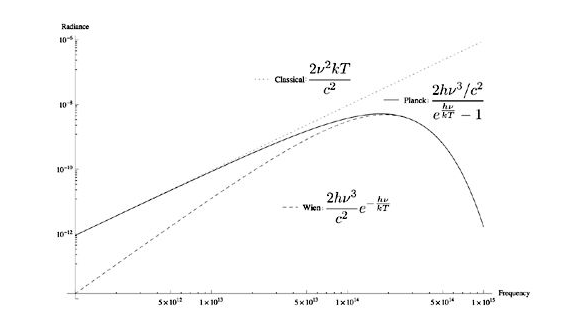
Para frecuencias suficientemente altas, el termino 1 en el denominador es insignificante comparado con el enorme término exponencial. Dejando de lado el 1, el exponencial en el denominador se convierte en una exponencial con exponente negativo en el numerador, reproduciendo exactamente la fórmula de Wien. Para frecuencias pequeñas la exponencial en el denominador aproxima a 1 y solo la diferencia de dos términos es importante y la diferencia se puede aproximar como 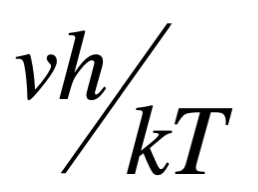 , por lo que
, por lo que 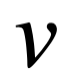 es reducida a 1 y un factor
es reducida a 1 y un factor 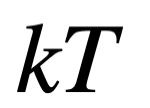 en el numerador. Esto es precisamente lo que la teoría clásica no observo de los efectos cuánticos. Por lo menos en retrospectiva la fórmula de Planck interpola suavemente entre la física clásica en frecuencias bajas y la fórmula de Wien a altas frecuencias. Aunque es un truco matemático, resultó en uno de los más importantes logros históricos de la física.
en el numerador. Esto es precisamente lo que la teoría clásica no observo de los efectos cuánticos. Por lo menos en retrospectiva la fórmula de Planck interpola suavemente entre la física clásica en frecuencias bajas y la fórmula de Wien a altas frecuencias. Aunque es un truco matemático, resultó en uno de los más importantes logros históricos de la física.
Considerando este punto esencial de todo cálculo de E, que se compone de un número bien definido de partes iguales y al utilizar la contante natural 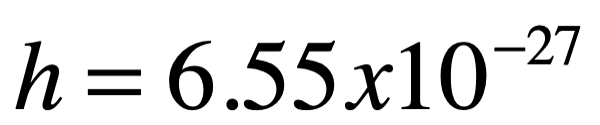 ergio x segundo. Esta constante multiplicada por la común frecuencia de los resonadores nos da la energía de los elementos
ergio x segundo. Esta constante multiplicada por la común frecuencia de los resonadores nos da la energía de los elementos 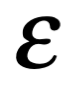 en ergios, y divide a
en ergios, y divide a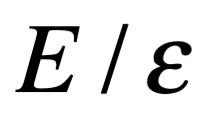 obteniendo el número P de elementos de energía que deben ser divididos sobre los N resonadores.
obteniendo el número P de elementos de energía que deben ser divididos sobre los N resonadores.
Esta última frase dice en palabras lo que se conoce ahora como fórmula de energía de Planck 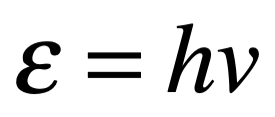 o
o 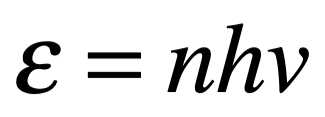 , donde n es algún número entero múltiplo de esta cantidad básica, una de las ecuaciones fundamentales que estructuran el mundo. Aunque Planck no se refiera a esta idea como un quantum. Él utiliza la palabra, sin embargo, la dice cuando explícitamente asume que los resonadores no pueden tener cualquier energía, como lo pensó la física clásica, las energías permitidas se separarían por múltiplos enteros, Planck consiguió algo fundamental, pero no lo que él esperaba, intentar salvar la teoría clásica, terminando por derribarla ante la contundencia de la evidencia experimental hasta 1900. Cinco años más tarde Albert Einstein volvió el truco matemático en un concepto físico. En 1905 publicó cuatro extraordinarios textos que rompieron con la física clásica. Uno fue el efecto fotoeléctrico, el hecho de que la luz se incide a un metal hace saltar electrones de su superficie. La teoría clásica predice que la energía de los electrones debería depender de la intensidad de la luz. No lo hizo así; en su lugar solo depende de la frecuencia de la luz, si brilla una luz más intensamente sobre una superficie, más electrones saltan pero con la misma energía. Aunque Planck había hecho con cautela la predicción de introducir
, donde n es algún número entero múltiplo de esta cantidad básica, una de las ecuaciones fundamentales que estructuran el mundo. Aunque Planck no se refiera a esta idea como un quantum. Él utiliza la palabra, sin embargo, la dice cuando explícitamente asume que los resonadores no pueden tener cualquier energía, como lo pensó la física clásica, las energías permitidas se separarían por múltiplos enteros, Planck consiguió algo fundamental, pero no lo que él esperaba, intentar salvar la teoría clásica, terminando por derribarla ante la contundencia de la evidencia experimental hasta 1900. Cinco años más tarde Albert Einstein volvió el truco matemático en un concepto físico. En 1905 publicó cuatro extraordinarios textos que rompieron con la física clásica. Uno fue el efecto fotoeléctrico, el hecho de que la luz se incide a un metal hace saltar electrones de su superficie. La teoría clásica predice que la energía de los electrones debería depender de la intensidad de la luz. No lo hizo así; en su lugar solo depende de la frecuencia de la luz, si brilla una luz más intensamente sobre una superficie, más electrones saltan pero con la misma energía. Aunque Planck había hecho con cautela la predicción de introducir 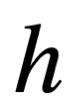 , advirtió que los resonadores solo podrían absorber y emitir luz con energías en múltiplos de
, advirtió que los resonadores solo podrían absorber y emitir luz con energías en múltiplos de 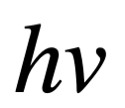 . Einstein dice que
. Einstein dice que 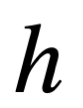 es una característica de la luz en sí misma. La luz es granulada, localizada en el espacio y con energías en múltiplos de
es una característica de la luz en sí misma. La luz es granulada, localizada en el espacio y con energías en múltiplos de 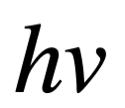 , o quantums (cuantos) de luz, más tarde llamados fotones. Además, la energía durante la propagación de un rayo de luz, la describió, como algo no distribuido continuamente sobre el espacio, en constante aumento, pero consta de un número finito de cuantos de energía localizados en los puntos en el espacio, sin dividir y capaces de ser absorbidos o generados solo como cantidades discretas. Por lo tanto, la energía de los fotones que brilla en la superficie de un metal tiene que ser al menos tan grande como la suma de la energía final del electrón que salta de la superficie, además la energía necesaria para que un electrón deje el metal está en función del trabajo:
, o quantums (cuantos) de luz, más tarde llamados fotones. Además, la energía durante la propagación de un rayo de luz, la describió, como algo no distribuido continuamente sobre el espacio, en constante aumento, pero consta de un número finito de cuantos de energía localizados en los puntos en el espacio, sin dividir y capaces de ser absorbidos o generados solo como cantidades discretas. Por lo tanto, la energía de los fotones que brilla en la superficie de un metal tiene que ser al menos tan grande como la suma de la energía final del electrón que salta de la superficie, además la energía necesaria para que un electrón deje el metal está en función del trabajo: 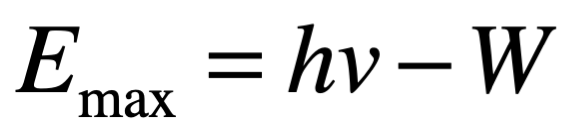 . Es como la forma de la energía de una bala en el cañón de un rifle, es menos de lo que era cuando inicialmente exploto debido a la energía perdida viajando por el cañón.
. Es como la forma de la energía de una bala en el cañón de un rifle, es menos de lo que era cuando inicialmente exploto debido a la energía perdida viajando por el cañón.
Por un tiempo Planck luchó con sus colegas para adaptar la idea de 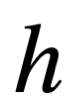 en el marco de la física convencional. Todo fue en vano, la evidencia experimental hace que no se puede ignorar a
en el marco de la física convencional. Todo fue en vano, la evidencia experimental hace que no se puede ignorar a 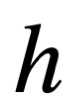 , cada vez que las frecuencias altas o bajas estaban implícitas, exigían la entrada de esta constante en el cálculo. Es durante la conferencia de 1911 en Bruselas que Planck señala otra implicación bizarra. Su constante no es una cantidad específica de energía, pero establece una proporcionalidad entre dos cantidades. La ecuación
, cada vez que las frecuencias altas o bajas estaban implícitas, exigían la entrada de esta constante en el cálculo. Es durante la conferencia de 1911 en Bruselas que Planck señala otra implicación bizarra. Su constante no es una cantidad específica de energía, pero establece una proporcionalidad entre dos cantidades. La ecuación 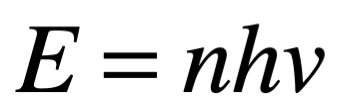 , por ejemplo relaciona energía con frecuencia; si una sube, la otra también lo hace. Los físicos llaman constantes de proporcionalidad entre energía y frecuencia o constantes de acción. Es sorprendente que
, por ejemplo relaciona energía con frecuencia; si una sube, la otra también lo hace. Los físicos llaman constantes de proporcionalidad entre energía y frecuencia o constantes de acción. Es sorprendente que 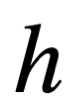 es una cantidad de acción a través de la noción del espacio de fase, o la representación abstracta de todos los valores claves posibles que un sistema puede tener. En la física clásica, cada punto de la tabla es una posición posible para un objeto. Cuando un objeto cambia de posición y su impulso, se mueve de un punto a otro, traza una línea, y las leyes de Newton pueden utilizarse para predecir su trayectoria. Planck observó que en el mundo cuántico, tal objeto no tiene un número infinito de posiciones. La tabla está formada por pixeles, cada uno en la zona de
es una cantidad de acción a través de la noción del espacio de fase, o la representación abstracta de todos los valores claves posibles que un sistema puede tener. En la física clásica, cada punto de la tabla es una posición posible para un objeto. Cuando un objeto cambia de posición y su impulso, se mueve de un punto a otro, traza una línea, y las leyes de Newton pueden utilizarse para predecir su trayectoria. Planck observó que en el mundo cuántico, tal objeto no tiene un número infinito de posiciones. La tabla está formada por pixeles, cada uno en la zona de 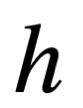 , que representa un estado posible como una gama de valores de posición y momentos para el objeto. Sus posibilidades son ahora enormemente restringidas. No se puede mover continuamente de un punto a otro, pero se ha quedado atascado en una región por lo menos tan grande como un quantum. Cada pixel es un espacio de acción y movimiento del objeto, son discontinuos entre ellos. Con el beneficio de la retrospectiva, muchos de los principios de la teoría cuántica están incluidos en este comportamiento, tal como el de incertidumbre que predice este pixelado o cuantizado. La cuántica se definía entonces por poner entrelazamientos y burbujas en lugares del universo, abriendo una nueva era en la ciencia.
, que representa un estado posible como una gama de valores de posición y momentos para el objeto. Sus posibilidades son ahora enormemente restringidas. No se puede mover continuamente de un punto a otro, pero se ha quedado atascado en una región por lo menos tan grande como un quantum. Cada pixel es un espacio de acción y movimiento del objeto, son discontinuos entre ellos. Con el beneficio de la retrospectiva, muchos de los principios de la teoría cuántica están incluidos en este comportamiento, tal como el de incertidumbre que predice este pixelado o cuantizado. La cuántica se definía entonces por poner entrelazamientos y burbujas en lugares del universo, abriendo una nueva era en la ciencia.
La notación de salto cuántico se introduce en la física atómica desde la cuántica de Niels Bohr. Gracias a una beca de la cervecera Carlsberg, Bohr viajó al laboratorio Cavendish en Cambridge Inglaterra, cuyo jefe era Thomson, quien había ayudado a descubrir el electrón. Pero Thomson no encontró interés en la investigación Bohr. A finales de 1911, en visita a Manchester, Bohr conoció a Ernest Rutherford experimentador del mundo de la radiactividad. Esto hace que Bohr deje Cavendish y se una al laboratorio de Rutherford en marzo de 1912. Allí Bohr sentó las bases para una de las mayores revoluciones en la física mediante la incorporación de la cuántica a la estructura atómica. El trabajo de Thomson demostró que partículas de átomos llamadas electrones, están cargadas negativamente. La existencia de la partícula protón con carga positiva fue propuesta pero no aceptada inmediatamente. Rutherford adujo que toda carga positiva estaba alojada en el núcleo atómico central y propuso que los electrones giran como si fueran planetas alrededor del sol. Pero la idea trajo poca atención y no fue promovida porque los científicos tenían buenas razones para ser escépticos.
Cargas eléctricas, no son planetas. Cuando estas cargas se arremolinan bajo la influencia de otra carga, irradian energía. Los electrones en los átomos de Rutherford rápidamente disminuyen sus órbitas y en espiral caen al núcleo. Según las leyes tradicionales del movimiento y la atracción, la idea de Rutherford no funcionaría. Bohr, sin embargo, presintió que el quantum jugaba un rol extraño en la fabricación de átomos estables. Desde luego que no fue el primero en pensar esto, Planck lo hizo primero. Pero Bohr estaba en una posición especial para encontrar el camino correcto para resolver el problema. Conocía el modelo de Rutherford a profundidad, y estaba armado con la información más reciente sobre el quantum. La solución vino a Bohr en varios pasos audaces en 1912.
¿Por qué no podían los electrones orbitar el núcleo similar a los planetas?, por qué no irradian energía los planetas cuando orbitan. La respuesta la da Bohr, tiene que ver con la acción cuántica, con el hecho de que el espacio de fase se da en trozos. Esta acción se relaciona con energía multiplicada por tiempo. En el mundo newtoniano, acción es una variable continua, pero para la implicación atómica esto resultó bizarro. La intuición de Bohr, por contrario, se inclinó por ver a la acción de cuantización, para explicar la estabilidad del átomo. Para probarlo, él tendría que encontrar una conexión entre energía cinética de los electrones girando en el núcleo y su frecuencia. Estaba emocionado y perplejo ante un rayo pulsado con líneas espectrales. Esta luz que se desprende del movimiento de los electrones, que saltan entre orbitales hacia delante o hacia tras entre ellos, absorbiendo y emitiendo energía en forma de luz en frecuencias especificas en el proceso. Tales líneas se habían estudiado durante medio siglo, los científicos llamados espectroscopistas conocían estas líneas. En 1885 un maestro de escuela Johann Balmer hizo un hallazgo sorprendente: matemáticamente logro ajustar las frecuencias de la líneas espectrales de hidrógeno a una fórmula que predice otras líneas que él desconocía. En notación moderna, la fórmula de producción de series 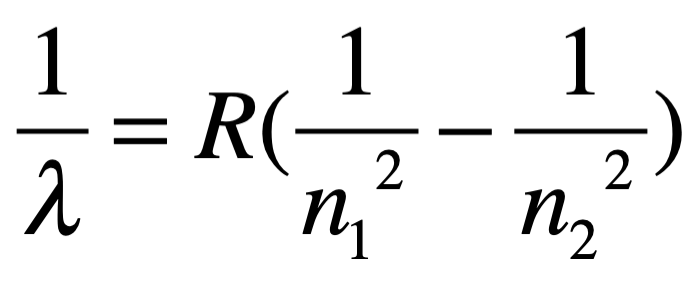 , donde R es una constante, llamada constante Rydberg, n1 es un entero mayor que cero, n2 es un entero mayor que n1.
, donde R es una constante, llamada constante Rydberg, n1 es un entero mayor que cero, n2 es un entero mayor que n1.
Tan pronto como Bohr advirtió la fórmula de Balmer dijo que todo fue claro para él. La fórmula demostró una cantidad clásica continua, la longitud de onda, tomando valores enteros múltiplos de una unidad básica. Pero eso fue un signo de cuantización. Bohr se dio cuenta, y la fórmula le dio una señal para la observación de la naturaleza cuántica de la estructura atómica. Cuando los electrones absorben energía de los fotones, almacenan energía moviéndose a una órbita más alta y la liberan en forma de fotones de una frecuencia específica al regresar a un nivel más bajo. Las matemáticas demuestran que la energía de enlace en la segunda órbita es un cuarto de la primera, la tercera una novena y luego un dieciseisavo y así sucesivamente. El salto de transición de una más alta a una órbita más baja de la energía se emite en forma de luz una frecuencia especifica: una línea espectral. La acción cuántica significó que hay solo determinadas órbitas atómicas permisibles. Era como si hubiera solo ciertas órbitas permitidas alrededor del sol y un planeta no pudiera hacer una transición de una a otra, pero en su lugar se materializaría en el lugar permitido. Bohr se dio cuenta de que la serie de Balmer le permitía conectar un conocimiento entre la acción cuántica y las líneas espectrales. Era una huella de la estructura cuántica del átomo.
Después de intenso trabajo en marzo de 1913 Bohr escribió un artículo llamado “La constitución de átomos y moléculas, parte I”. Si bien demostró que los electrones no tienen un infinito de posibilidad alrededor del núcleo, sino que están confinados en una pequeña sección de órbitas, se enfrentó con no poder explicar por qué los electrones no caen al núcleo, él simplemente declaró que el estado es estable, así para no contravenir todos los conocimientos sobre radiación ya revelados hasta ese momento.
La explicación de Bohr funciona muy bien con el hidrogeno, pero no ocurrió así para otros elementos. Cuando un átomo tiene más de un electrón, la interacción entre los electrones sirve para detectar la carga positiva del núcleo que afecta firmemente el enlazado externo de los electrones, claro está que esto presenta complejidades que no se manejan fácilmente por el tratamiento de Bohr.
Si bien Bohr no bautizó las palabras “salto” y ”saltar” en sus primeros trabajos, pero sí habló de simples órbitas del electrón o estados estacionarios. Sin embargo, su modelo dijo que los electrones podrían tener solo valores de energía específicos, lo que significaba en el lenguaje de las órbitas y trayectorias entre órbitas, era algo insatisfactorio. Los electrones no podrían pasar de transición sin problemas entre una ubicación atómica y otra – como un satélite cambia de órbita - pero hizo la transición instantánea de alguna manera. Dentro de unos años, los textos científicos popularizarían en un lenguaje más preciso este hecho como saltos o tirones entre estados. Por tanto la energía es discontinua y atómica, se da en tirones, como Imag6 en movimiento, pero los tirones suceden tan rápido que vemos una continuidad. Esta comparación, con secuencias de Imag6 de cine, es justo una buena idea para extender el concepto de saltos cuánticos como una función de nuestro mundo.
La palabra cuántica, rápidamente se convirtió en una metáfora de la discontinuidad. Discontinuidades no son necesariamente azar o sin causa; los tirones aún estaban incluidos en las fuerzas continuas newtonianas. El quantum era ahora una idea de encendido y apagado, en lugar de grados de libertad. Así nació el término salto cuántico, referido como un aumento repentino, significativo o muy evidente o avance. Si consideramos un salto grande o pequeño depende de su escala. Un salto cuántico es un pequeño paso para un hombre pero un paso grande para conocer el átomo, como lo es para un universo discontinuo para un electrón.
Es decir, las palabras simples o compuestas son metamorfosis, no tienen un significado fijo. Pueden explotar creativamente como nuevos conceptos. El cambio en el significado de “salto cuántico” no es el único caso. Varias palabras del lenguaje ordinario tales como momento, fuerza, gravedad…, han terminado como términos científicos, pero otras en sentido inverso su fluidez hacia la sociedad es limitada, por ejemplo, principio de incertidumbre, complementariedad, entropía y catalizador entre muchos otros términos que vienen a enriquecer la vida ordinaria del lenguaje. La ciencia es una forma de laboratorio en el que se intenta que las palabras sean utilizadas con un significado en correlación objetiva con la realidad ontológica. Solo un pequeño grupo de palabras tienden a pasar de conceptos científicos a una revolución social del imaginario ordinario, este es el caso de la relatividad y la cuántica. En la física, por ejemplo, una “onda”, significaba originalmente en lenguaje ordinario algo que tuvo lugar en un medio. Sin embargo, su extensión metafórica respecto de la luz, dice, que no requiere de un medio para propagarse, y luego en la cuántica implica a la probabilidad como cambio de significado. Una “onda” ahora es una nueva metáfora donde no hay medio de propagación, de este modo a nuestro lenguaje se le exige adecuar los términos que emplea para intervenir en la realidad científica, así salto cuántico representa parte de una nueva imagen mental de la realidad.
Cuando Bohr introduce el quantum a la estructura atómica, su idea era simple. Dentro de sus supuestos consideró que el electrón viajaba muy por debajo de la velocidad de la luz para no entrar en juego contra la relatividad. Él asumió que las órbitas eran circulares y que el electrón no irradiaba energía como sugerían las leyes clásicas de Maxwell. La descripción mecánica de las órbitas, en términos clásicos, era la fuerza centrípeta necesaria para mantener al electrón en su órbita circular ![]() , igualada a la fuerza eléctrica de atracción entre electrones y su núcleo
, igualada a la fuerza eléctrica de atracción entre electrones y su núcleo 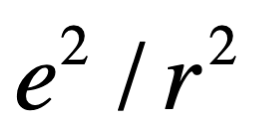 . Es decir
. Es decir 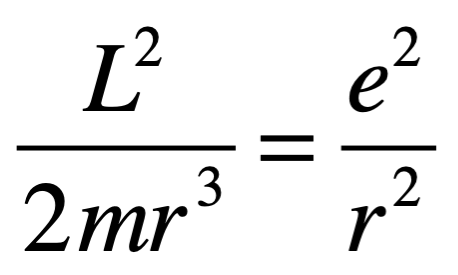
Esto da lugar a algo similar a las leyes de Kepler de los movimientos planetarios. En esta imagen atómica, la metáfora es, el núcleo, el sol y el electrón es un planeta. Si esto fuera totalmente cierto, el electrón podría orbitar el núcleo en un número finito de maneras posibles, pero al seguir perdiendo energía, se hundirá eventualmente en el núcleo atómico. Bohr entonces hizo otra hipótesis, solo algunas de estas órbitas son posibles, y usó la idea cuántica para escoger estas órbitas seleccionadas. Permite en su modelo órbitas, las cuales el momento angular del electrón, son enteros múltiplos de una constante formada por la constante de Planck: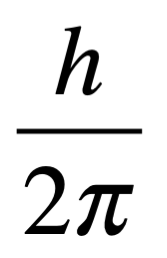 , llamada “hbar” y representada por h.
, llamada “hbar” y representada por h.  veces el momento angular igual a nh, con n como número entero. El radio de las órbitas permitidas ahora es
veces el momento angular igual a nh, con n como número entero. El radio de las órbitas permitidas ahora es
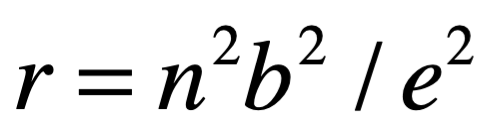
Cuando los electrones saltaban o saltan desde una de estas órbitas a otra, la diferencia de sus energías es:
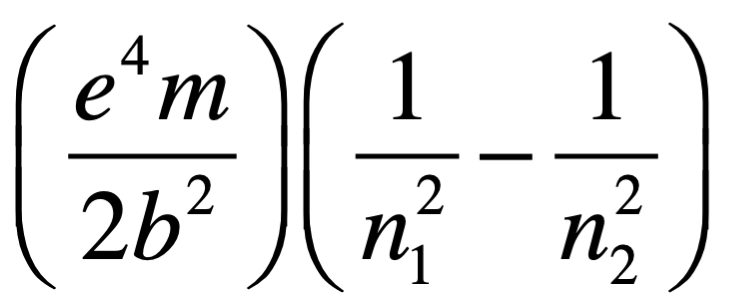
Esto condujo directamente a través de la relación de Planck 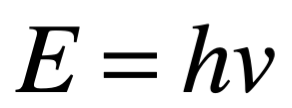 , a la siguiente fórmula de longitud de onda:
, a la siguiente fórmula de longitud de onda:
Para 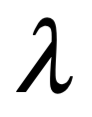 , esto corresponde a la serie original de Balmer para el hidrogeno, con líneas en el espectro visible. Así el átomo de Bohr era un hibrido; tomó el modelo clásico e impuso una restricción cuántica. Se rompió casi inmediatamente esta idea, porque solo aplica al hidrogeno. Tuvo que esperar más conocimiento para dar un paso trascendental, sin embargo, demostró que la cuántica estaba inscrita en la estructura de la materia. La materia se mantiene unida debido a h. Sí, h es pequeña, si fuera cero los átomos colapsarían en fracciones de segundo. En los saltos cuánticos, h fuerza a los electrones a dar estabilidad al átomo dentro de la mecánica en este micromundo. ¿Por qué esto para todos los átomos de hidrogeno y cualquier otro átomo? La cuantización es la respuesta, porque todos tienen la misma estructura. Hay esencialmente una manera en la que podemos mantener juntos electrones y protones para hacer estable un átomo de hidrogeno. Y la misma vale para otros átomos.
, esto corresponde a la serie original de Balmer para el hidrogeno, con líneas en el espectro visible. Así el átomo de Bohr era un hibrido; tomó el modelo clásico e impuso una restricción cuántica. Se rompió casi inmediatamente esta idea, porque solo aplica al hidrogeno. Tuvo que esperar más conocimiento para dar un paso trascendental, sin embargo, demostró que la cuántica estaba inscrita en la estructura de la materia. La materia se mantiene unida debido a h. Sí, h es pequeña, si fuera cero los átomos colapsarían en fracciones de segundo. En los saltos cuánticos, h fuerza a los electrones a dar estabilidad al átomo dentro de la mecánica en este micromundo. ¿Por qué esto para todos los átomos de hidrogeno y cualquier otro átomo? La cuantización es la respuesta, porque todos tienen la misma estructura. Hay esencialmente una manera en la que podemos mantener juntos electrones y protones para hacer estable un átomo de hidrogeno. Y la misma vale para otros átomos.
Un salto cuántico, dijimos, es un pequeño paso para un hombre, pero un gran paso para un electrón. ¿Qué tan grande es? Para darnos una idea, consideramos la energía y las distancias involucradas. ¿Sí pudiéramos saltar 10 metros en el aire, sería enorme la energía involucrada? Ahora vamos a ver si comparamos a este salto con la energía de un electrón que va desde el primer estado a un segundo dentro de un átomo de hidrogeno. ¿Cuánto es para nosotros este salto quivalente?, sería hacer saltar un electrón fuera del campo gravitacional de la tierra, tendría que ser lanzado con la misma energía necesaria para romper la fuerza de gravedad. La respuesta es alrededor de 100 millones de kilómetros, lo que significa una distancia comparable a la distancia de la tierra al sol. La comparación muestra que el electrón hace un salto verdaderamente enorme.
La energía de salto de los electrones es muy pequeña en comparación, esencialmente con cualquier energía requerida para un objeto macroscópico del tamaño humano. La masa de un electrón es tan pequeña que esta energía tiene un efecto mayúsculo sobre la velocidad del electrón, que implica aceleraciones que aplastarían a un ser humano. La perspectiva de grandes o pequeños para el cambio de energía del electrón depende sobre lo que comparemos.
La nube cuántica de electrones puede parecer un comportamiento azaroso. La aleatoriedad y la incertidumbre están en el centro del universo colocadas juntas para darnos una visión de la aleatoriedad cuántica, como un orden difuso del cosmos. En el mundo newtoniano clásico la respuesta a estas preguntas es ¡No!, la materia no baila en desorden; el comportamiento causal a gran escala debe seguir también el orden más pequeño de la materia según Newton. Laplace pensó que para cada estructura se puede predecir todos los eventos con la suma total de ellos en esa realidad.
Pero los seres humanos no estamos en esa feliz situación. Simplemente no sabemos cómo funciona la mayoría del universo. Para hacer frente a estas situaciones, los científicos crean teorías de probabilidad y error de medición. Algunas distinciones claves son que los eventos aleatorios carecen de fines, razones o causales específicas. Así la estadística es el análisis de la frecuencia de eventos que ya han sucedido y los patrones en ellos. Mientras la probabilidad es el uso de estadísticas para predecir los acontecimientos futuros. La incertidumbre es la cantidad de posibles desviaciones de un resultado presente en el mundo newtoniano, como formas de describir y abordar las situaciones de conocimiento incompleto. Estas herramientas eran necesarias en circunstancias cuando se deseara saber el modelo pero no la forma y el color de cada ladrillo de la realidad.
Hoy azar, incertidumbre y la posibilidad de predecir (probabilidad) a menudo son asociados con el comportamiento cuántico y vistos como características permanentes de nuestro mundo. La transición de la física clásica a la cuántica fue gradual, al ritmo en que la estadística y la probabilidad fueron hechas suyas por la comunidad científica. Esto comenzó en el siglo XIX, cuando aparecieron varios fenómenos en el mundo newtoniano que parecían inofensivos, pero acabaron por ser subversivos y generaron una revolución.
El primero llegó a través de la termodinámica. La palabra fue acuñada a mediados del siglo XIX para referirse a la ciencia del calor, concebida no como una sola sustancia, como lo había sido, sino como un fenómeno derivado de movimientos de numerosas partículas. De una disciplina a otra, la ciencia física tuvo que pedir herramientas de las ciencias sociales para explicar estos movimientos. Gracias al trabajo de Quetelet, la estadística se había convertido en un recurso bien desarrollado para analizar el nacimiento y las tasas de mortalidad, enfermedad, crimen y así sucesivamente donde cada elemento individual de seguimiento del comportamiento era posible. Los científicos que estudian la termodinámica y otras situaciones que implican muchos movimientos de partículas se dieron cuenta que la estadística podría ayudarles al estudio de nubes de partículas. Esta estadística, fue la herramienta para estudiar sistemas complejos como la sociedad humana. Así, los sociólogos investigan el comportamiento de la sociedad y los científicos naturales gases y otras nubes de partículas. La estadística revela el comportamiento global del sistema y no el de cada partícula en lo individual.
El segundo fenómeno subversivo fue el movimiento browniano, referido al hecho misterioso presente bajo observaciones al microscopio, que hace que los granos de polen parezcan revolotear al azar. Este movimiento impredecible de los objetos inanimados no se podía explicar en el momento histórico en que fue identificado. Todavía un tercer fenómeno subversivo apareció, fue la radiación. El fenómeno de ciertas clases de átomos que los llevan a convertirse en otra clase de elemento, y cuyo proceso emite energía. En 1896 fue identificado este fenómeno en el uranio, como radiación en apariencia espontánea, sin causa particular. En 1900, estudiando la radiación de óxido de torio, Ernest Rutherford salió con una ley cuantitativa. La intensidad de la radicación, dijo, cayó con el tiempo (lo que ahora llamamos vida media) de una manera consistente con cada átomo en términos una probabilidad fija de transformación por unidad de tiempo. Este tipo de ley probó en todos los elementos radiactivos su consistencia. Esta ley de Rutherford se parece a la de tasas de mortalidad, fue una tabla de tasas de mortalidad para los átomos. Más información proporciono esta técnica y ayudó a los científicos a encontrar un mecanismo que especifique una explicación causal para cada muerte atómica.
Esta acumulación de evidencia les dió a los científicos una sensación incómoda sobre algo misterioso que se escondía en una escala de distancias muy pequeñas. A finales del siglo XIX el estadounidense Charles S. Pierce propuso que la aleatoriedad residía en el corazón de la naturaleza, esto se sentía, los científicos no llegaran a un final de leyes válidas para todas las escalas y disciplinas necesarias para explicar el universo. Los elementos subversivos parecerían obligar a los científicos a utilizar probabilidad y estadística como la mejor herramienta disponible para elementos de comprensión fuera de alcance, desde luego por su elevada complejidad. El personaje que transformó la estadística y la probabilidad en una herramienta conveniente, aunque cada vez más indispensable y en un elemento estructural del mundo fue Albert Einstein, en una serie de tres artículos sobre la teoría cuántica escritos entre 1916-17.
Estas ideas relacionaron las propiedades ondulatorias de la luz, problemas de termodinámica, y la ley de la radiación cuantitativa de Rutherford, para instalar la probabilidad en el corazón del comportamiento atómico. A pesar que lamentó que esto fuera así. La concepción original de Planck sobre el quantum no implicó a la probabilidad. Ni Einstein lo explicó en 1905 al modelar el efecto fotoeléctrico, aunque estaba preocupado por otros asuntos, especialmente en el desarrollo de la relatividad general. Es hasta que Einstein queda impresionado por el trabajo de Bohr de 1913-1914, que describe los átomos como almacenamiento de energía absorbida de la radiación por electrones en movimiento, de estados inferiores a estados superiores, y luego soltando esa radiación moviendo a los electrones nuevamente hasta un estado más bajo; en el proceso se emite luz en frecuencias específicas correspondientes a la diferencia de energía de los dos estados. Esto es lo que crea el espectro de un elemento, la huella de su estructura cuántica. Pero Bohr aún no usó las distribuciones de probabilidad en la discusión sobre los saltos de los electrones entre estados. Solo a finales de 1915, cuando Einstein completó su teoría de la relatividad general, es que vuelve a examinar cómo los cuántos son emitidos y absorbidos por la materia.
Inmediatamente en agosto de 1916, Einstein escribió a su amigo Michele Besso una idea brillante, una derivación de la fórmula de Planck, asombrosa y simple. Recuerde que Planck había estipulado que estos osciladores trabajan de esa manera particular, no proporcionando la correlación entre h y 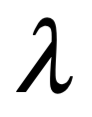 . Entonces Einstein adoptó la estrategia desarrollada para su física relativista especial y general, omitiendo la cuestión de qué tipo de materia emite y absorbe la luz para centrarse en una derivación general. Pero para ello requirió introducir un factor de probabilidad como una parte fundamental, así entre 1916-17 describió la naturaleza en términos de fundamentos de probabilidad como técnica. Todo esto cambiaría en 1925-27 con la revolución de la mecánica cuántica, con la función de onda de Schrödinger y el principio de incertidumbre. Se hace referencia a la aleatoriedad cuántica y de probabilidad cuando el astrónomo británico Arthur Eddington, en un texto titulado “La naturaleza del mundo físico”, dibujo para la atención pública, que función aleatoria en general y en lo particular al principio de incertidumbre dentro de la teoría cuántica: “la mecánica cuántica es un determinismo de probabilidades, una fórmula de hierro, para un determinismo posible limitado”. El desfile de átomos, Eddington lo presentó como una filosofía aleatoria del universo.
. Entonces Einstein adoptó la estrategia desarrollada para su física relativista especial y general, omitiendo la cuestión de qué tipo de materia emite y absorbe la luz para centrarse en una derivación general. Pero para ello requirió introducir un factor de probabilidad como una parte fundamental, así entre 1916-17 describió la naturaleza en términos de fundamentos de probabilidad como técnica. Todo esto cambiaría en 1925-27 con la revolución de la mecánica cuántica, con la función de onda de Schrödinger y el principio de incertidumbre. Se hace referencia a la aleatoriedad cuántica y de probabilidad cuando el astrónomo británico Arthur Eddington, en un texto titulado “La naturaleza del mundo físico”, dibujo para la atención pública, que función aleatoria en general y en lo particular al principio de incertidumbre dentro de la teoría cuántica: “la mecánica cuántica es un determinismo de probabilidades, una fórmula de hierro, para un determinismo posible limitado”. El desfile de átomos, Eddington lo presentó como una filosofía aleatoria del universo.
Cada una de las contribuciones de Einstein a la física cuántica muestra que era el maestro principal del siglo XX de termodinámica y mecánica estadística, campos newtonianos de probabilidad, aleatoriedad y la teoría de la norma estadística. Es lógico entonces pensar que fue el quien introduce en el núcleo atómico la teoría cuántica y escribe las bases de la naturaleza cuántica, a pesar de sus protestas reflejadas en su frase “Dios no juega a los dados”.
En sus documentos de 1916-17 Einstein trata a la luz como partícula –idea introducida en su artículo del efecto fotoeléctrico en 1905- y procedió preguntando: ¿Cuáles son las condiciones en la distribución de partículas de la luz para un sistema de moléculas y fotones para estar en equilibrio térmico a una determinada temperatura? Había ya principios bien aceptados para determinar la distribución de probabilidad de diversas excitaciones de energía de cada molécula. De esta y otras informaciones generales sobre cómo debe comportarse la luz, Einstein dedujo precisamente la distribución de energía de la luz, que obtuvo Planck en 1900 por medios cuestionables.
Einstein imaginó un trozo de materia, lo llamó una molécula, aunque también podría haber sido un oscilador o átomo, bañado en radiación de luz. Se preguntó ¿Cómo debe absorber y emitir radicación? Supongamos que está en equilibrio, lo que significa que absorbe y libera energía al mismo ritmo. Su tasa de emisión en presencia de este baño de radiación es mayor en comparación con lo que sería sino hay otros fotones a su alrededor. Einstein utiliza las ideas de equilibrio termodinámico en la conclusión de que la tasa a la que un átomo sería capaz de emitir un fotón en presencia de un campo externo, es mayor que en el átomo en el espacio vacío. Calculó cómo esto funcionaría, como proceso de emisión y absorción, y predijo que están relacionados entre sí. Hay una parte espontánea relacionada solo entre átomo y electrón, y otra relacionada con los fotones. ¿Pero cuándo va emitir la luz el átomo y de qué manera va a suceder, cuando ambas cosas son impredecibles?, propuso que las probabilidades se tendrían que considerar fundamentales, básicas, físicas de sistemas atómicos. Esto permitió una derivación de la ley de Planck de una manera asombrosamente simple y general.
Pero es en este momento histórico, que Einstein tuvo su primer arrepentimiento. Pensó que estos resultados eran una debilidad de la teoría, que deja tiempo y dirección de los procesos elementales al azar. No había manera de saber cuándo y en qué dirección el fotón saldría, sin embargo, concluyó, “tengo plena confianza en la ruta que se ha tomado”.
Einstein escribió a Max Born que no podía creer que Dios juega a los dados. Pero el propio Einstein fue el primero en dar a entender que esto era de hecho cómo funciona la Deidad, en su simple derivación de la fórmula de Planck. Hacia el final de su vida, cuando hablando con un grupo de cirujanos de Cleveland en 1950, Einstein expuso uno de sus ejemplos más simples de aleatoriedad en la física cuántica. "Suponga que tiene una ola llegando a un límite entre dos medios refractivos. La teoría de Maxwell garantiza que habrá una onda transmitida y una onda reflejada. Haciendo esta onda tan débil que solo una vez al mes llega un fotón: qué pasara ¿se reflejara o se transmitirá?. No hay manera de saber, puede darse la probabilidad de ambas, pero no sabremos qué pasará".
Evaluación 15__________
6.25.1 En sintesis h
En síntesis h nace del problema: la radiación del cuerpo negro a finales del siglo XIX, los físicos estudiaban cómo un objeto caliente emite luz. Un cuerpo negro es un objeto ideal que absorbe toda la radiación que recibe y emite radiación cuya intensidad depende solo de su temperatura. Los experimentos medían: intensidad de radiación en función de la frecuencia a distintas temperaturas. Los datos eran muy precisos, pero la física clásica fallaba. Es decir la catástrofe ultravioleta de la la teoría clásica (Rayleigh–Jeans) predecía que a frecuencias altas, la energía emitida debía crecer sin límite. Es decir, el objeto emitiría energía infinita. Eso es absurdo. Se llamó “Ultraviolet catastrophe” la experimentación mostraba exactamente lo contrario, radiación cae en el ultravioleta.
La solución de Max Planck (1900) intentó ajustar una fórmula matemática que coincidiera con los datos.
Para lograrlo hizo una hipótesis radical: la energía no se intercambia de forma continua, se intercambia en paquetes discretos, propuso que la energía de un oscilador es: E=nhν; donde: ν = frecuencia; n = entero; h = nueva constante universal. Esa constante fue ajustada para que la fórmula coincidiera con los datos experimentales. Así nació la constante de Planck h.
Planck ajustó su ecuación a las curvas experimentales medidas en laboratorio. El valor que mejor reproducía los datos fue:
h≈6.626×10−34 J.s ((julios por segundo)
¡No fue deducida teóricamente!, fue determinada empíricamente.
La constante reapareció en otros fenómenos:
a) Efecto fotoeléctrico, en le que Albert Einstein mostró que la energía de la luz viene en cuantos: E=hν
Los experimentos confirmaron exactamente el mismo valor de h.
b) Espectros atómicos. En el modelo de Bohr las órbitas electrónicas dependen de h. Las líneas espectrales medidas coinciden con ese valor.
Desde 2019, el Sistema Internacional redefinió las unidades. La constante de Planck tiene un valor exacto definido. El kilogramo se define a partir de ella. Es decir: antes medíamos h, ahora definimos unidades usando h.
La constante de Planck marca la escala en la que:
- La naturaleza deja de comportarse clásicamente.
- Aparecen efectos cuánticos.
- La acción no puede ser arbitrariamente pequeña.
Es la “unidad mínima de acción”. Sin ella:
- No habría cuantización.
- No habría incertidumbre.
- No habría fluctuaciones del vacío.
Más comúnmente se usa:
ℏ=h/2π
Esta constante aparece como:
- Factor en la cuantización
- Escala de acción mínima
- Factor en el conmutador [x, p]= i ℏ
No es una consecuencia matemática interna de la teoría. Es un parámetro que fija la escala cuántica del universo. La mecánica cuántica toma ℏ como dada. La teoría cuántica de campos lo toma como dada. La relatividad general no lo determina. ¿Es realmente una h una constante “fundamental”? Sabemos: h fija la escala en la que aparecen efectos cuánticos; no puede deducirse desde teorías actuales; se introduce como parámetro empírico. En ese sentido, es análogo a: la velocidad de la luz antes de la relatividad y la constante gravitacional antes de una teoría más profunda.
Esto nos lleva a una cuestión fuerte: ¿las constantes físicas son necesarias o contingentes?
Si son contingentes:
- El universo podría haber tenido otro valor de h.
- La estructura de la realidad sería distinta.
Si son necesarias:
- Debe existir una teoría más profunda que las fije.
Actualmente no sabemos cuál es el caso.
¿Qué controla realmente h?
Aparece en:
- Principio de incertidumbre: ΔxΔp≥ℏ/2
- Tamaño de órbitas atómicas
- Energía de niveles cuánticos
- Longitud de onda de la luz
Hoy en día, además de ser un número necesario para la mecánica cuántica, h forma parte de un sistema de unidades naturales llamadas unidades de Planck, que se construyen únicamente con constantes fundamentales (velocidad de la luz c, constante gravitacional G, la constante de Boltzmann kB y ?) sin referencia a objetos materiales. Estas unidades son importantes porque señalan escalas en las que la física clásica y la cuántica se entrelazan de forma profunda.
Desde el punto de vista experimental la precisión con que se conoce h ha aumentado mucho en las últimas décadas usando fenómenos cuánticos como el efecto Hall cuántico o el efecto Josephson. En 2019, la constante de Planck fue elegida como uno de los valores exactos para definir el nuevo Sistema Internacional de Unidades (SI), eliminando desviaciones experimentales y volviendo a h un valor sin incertidumbre asociada. Esto refleja una de las aportaciones experimentales más limpias de los últimos años sobre la propia constante.
Cómo relacionar h con el tejido del espacio-tiempo.
ℏ no es solo “una constante pequeña”, es:
— La unidad mínima de acción,
— El factor que convierte conmutadores en cantidades físicas: [x, p]= i ℏ.
— La escala de todas las fluctuaciones cuánticas
Sin ℏ, el mundo sería clásico. Pero cuando introducimos ℏ, ocurre algo radical.
Si combinamos:
G (gravedad),
c (velocidad de la luz),
ℏ (cuántica),
obtenemos las unidades de Planck, por ejemplo:
Longitud de Planck:
 8.19.05p.m.png)
Porque esa longitud (~10^(-35) m) marca la escala donde la gravedad y los efectos cuánticos son igualmente importantes. ℏ determina la escala mínima en la que el espacio-tiempo puede tener sentido clásico. Por debajo de la longitud de Planck:
— La noción clásica de distancia podría dejar de existir.
— El espacio-tiempo podría ser granular.
— Podrían existir fluctuaciones geométricas.
Es decir: ℏ entra directamente en la escala donde el espacio-tiempo deja de ser continuo.
En teoría cuántica de campos el vacío tiene fluctuaciones:
 8.22.56p.m.png)
Si el campo gravitacional también es un campo cuántico, entonces la propia métrica del espacio-tiempo debe fluctuar con amplitud proporcional a ℏ. Eso significa, que el espacio-tiempo no sería una entidad rígida; sería un sistema cuántico con ruido inherente. En este escenario: ℏ no cuantiza cosas que viven en el espacio-tiempo. Cuantiza el propio mecanismo del cual emerge el espacio-tiempo.
La cuestión abierta para relacionar h con el tejido del espacio-tiempo significa investigar si:
— La geometría es discreta.
— La distancia mínima depende de ℏ.
— Las fluctuaciones métricas están gobernadas por ℏ.
— El espacio-tiempo es un estado cuántico colectivo.
Hoy no tenemos una teoría confirmada que lo establezca definitivamente.
Pero sabemos algo firme:
Sin ℏ, no existiría ninguna escala donde la geometría clásica deje de funcionar.
Analicemos con precisión qué significa: ℏ→0
ℏ controla:
La cuantización
Las relaciones de conmutación
Las fluctuaciones cuánticas
La amplitud de interferencia en integrales de camino
Si ℏ→0
entonces:
— [x,p]→0,
— desaparece el principio de incertidumbre,
— las integrales de camino quedan dominadas por una sola trayectoria clásica,
— desaparecen las fluctuaciones del vacío.
Es decir: el mundo se vuelve estrictamente clásico.
Aquí sí es crucial.
La escala natural donde se cuantiza el espacio-tiempo es la longitud de Planck:
 8.35.17p.m.png)
Si
ℏ→0
entonces:
lP→0
Eso implica:
— La escala donde el espacio-tiempo se vuelve granular desaparece.
— No habría “espuma cuántica”.
— No habría fluctuaciones métricas.
— El espacio-tiempo sería perfectamente continuo.
En términos físicos:
La geometría deja de ser un objeto cuántico.
En teoría cuántica de campos, el vacío no es vacío: fluctúa. Pero esas fluctuaciones son proporcionales a ℏ.
Si ℏ→0:
— El vacío se vuelve completamente pasivo.
— No habría creación virtual de partículas.
— No existiría energía de punto cero.
— No habría radiación de Hawking.
— No existiría inflación cuántica primordial.
— El universo temprano sería radicalmente distinto.
En otras palabras si ℏ→0:
— El espacio-tiempo sería un escenario rígido.
— La causalidad sería completamente determinista.
— No existiría el “ruido cuántico” fundamental.
En cierto sentido: ℏ es lo que impide que el universo sea una máquina newtoniana perfecta.
Si ℏ→0 entonces:
— El espacio-tiempo se vuelve completamente clásico.
— No hay granularidad.
— No hay fluctuaciones.
— No hay evaporación de agujeros negros.
— No hay incertidumbre.
— No hay superposición.
El universo sería geométricamente suave y dinámicamente determinista.
¿Qué significa realmente el conmutador?
En mecánica clásica: xp−px=0
En mecánica cuántica, x y p son operadores sobre un espacio de Hilbert, no números.
El conmutador se define como:
[x,p]=xp−px
Que no sea cero significa: posición y momento no pueden tener valores simultáneamente definidos.
¿Por qué aparece exactamente iℏ?
No es arbitrario.
Paso 1: Correspondencia con mecánica clásica
En mecánica clásica existe el corchete de Poisson:
 8.45.42p.m.png)
Cuando cuantizamos, imponemos la regla de correspondencia:
 8.46.34p.m.png)
Por lo tanto:
 8.47.03p.m.png)
Así, ℏ es el factor de conversión entre estructura clásica y estructura cuántica.
Observa dimensiones:
x: longitud
p: momento (masa × velocidad)
Entonces:
[x,p]∼acción
Y ℏ tiene dimensión de acción. Es la unidad natural de acción mínima.
Consecuencia directa: principio de incertidumbre
A partir del conmutador general:
 8.51.10p.m.png)
se obtiene la desigualdad:
 8.51.43p.m.png)
La incertidumbre no es una interpretación filosófica. Es una consecuencia algebraica directa del conmutador.
Podemos decir que: ℏ no es solo una constante.
Es el parámetro que:
— cuantiza la geometría del espacio de fases,
— fija la escala de indeterminación,
— convierte la simetría clásica en álgebra no conmutativa,
En términos más modernos: ℏ es el parámetro de no-conmutatividad del universo.
Qué significa “conmutatividad”
En matemáticas: AB=BA Si esto se cumple, el álgebra es conmutativa.
En física clásica: las variables dinámicas son funciones reales; multiplican conmutativamente; el orden no importa y el espacio de fases clásico es una variedad simpléctica con álgebra conmutativa.
En mecánica cuántica las magnitudes físicas son operadores; el orden importa.
Ejemplo fundamental:
 9.00.07p.m.png)
Si ℏ≠0 entonces:
 9.01.01p.m.png)
La no-conmutatividad es proporcional a ℏ si:
 9.01.42p.m.png)
el conmutador desaparece → se recupera la conmutatividad clásica.
Por eso ℏ mide el “grado” de no-conmutatividad.
La no-conmutatividad implica:
— Principio de incertidumbre.
— Imposibilidad de trayectorias definidas.
— Superposición de estados.
— Fluctuaciones del vacío.
Todas esas propiedades son proporcionales a ℏ.
Sin ℏ, no hay indeterminación.
la i no es un adorno técnico. Es la unidad imaginaria:
 9.06.41p.m.png)
Es decir,
 9.07.06p.m.png)
Pero en mecánica cuántica su presencia es estructural, no opcional.
Los observables físicos (posición, momento, energía) están representados por operadores hermíticos.
Un hecho matemático importante: El conmutador de dos operadores hermíticos es antihermítico.
Y un operador antihermítico puede escribirse como:
 9.09.42p.m.png)
Por eso el conmutador toma la forma:
El factor i garantiza que el lado derecho sea consistente con la estructura algebraica de operadores observables.
ℏ: fija la escala física de la no-conmutatividad.
i: asegura consistencia algebraica, hermiticidad y evolución unitaria.
Podemos decir con precisión: i introduce la estructura compleja necesaria para que la teoría cuántica conserve probabilidad y tenga observables reales. Los números complejos emergen como la única estructura que: permite superposición continua; mantiene conservación de probabilidad y permite transformaciones reversibles no triviales.
Ver: https://youtu.be/kXAvjuDTik4
Evaluación 16__________
[1] Bentley, Richard. (2011). The Correspondence of Richard Bentley. 10.1017/CBO9780511701061.
[2] Robert A. Millikan, The electron and the light-quant [sic] from the experimental point of view. Nobel Lecture, 23 May 1924. https://www.nobelprize.org/uploads/2018/06/millikan-lecture.pdf.
[3] Max-Planck- Gesellschaft. http://www.mpg.de/history_mpg
[4] Hegel Kragh (2000). Max Planck: the reluctant revolutionary. Physics Word p.p. 31-35. Recuperado de http://www.math.lsa.umich.edu/~krasny/math156_article_planck.pdf
[5] Boya Luis J. (2004). The termal radiation formula of Planck 1900. Zaragoza University. Recuperado de http://arxiv.org/abs/physics/0402064v1
[6] J.R. Person (2013). Evolution of quasi-history in a physics textbook. Physics Education. Recuperado de http://arxiv.org/abs/1308.1550
[7] L.A. Du Bridge & Paul A. Epstein (1959). Robert Andrews Millikan. Washington: National Academy of Sciences. Recuperado de http://www.nasonline.org/publications/biographical-memoirs/memoir-pdfs/millikan-robert.pdf
[8] Niels Bohr (1913). On the constitution of Atoms and Molecules. Philosophical Magazine 6, vol. 26: 1-25. Recuperado de http://hermes.ffn.ub.es/luisnavarro/nuevo_maletin/Bohr_1913.pdf
[9] Yatendra S. Jain et al. (2011). On the origin of Stark effect of rotons in He-II and the existence of p = 0 condensate. Current Sciense 101. Recuperado de http://arxiv.org/abs/1111.2665
[10] Paul Hartman (1994). A Memoir on The Physical Review: A History of the First Hundred Years. NY: AIP Press.