Texto universitario

_____________________________
El reinado del valor p ha terminado: ¿qué análisis alternativos podríamos emplear para llenar el vacío de poder?
Resumen
El valor p ha sido durante mucho tiempo la figura decorativa del análisis estadístico en biología, pero su posición está amenazada; p es ahora ampliamente reconocido por proporcionar información bastante limitada sobre nuestros datos y por ser fácilmente malinterpretado. Muchos biólogos son conscientes de las debilidades de p, pero no tienen menos claro cómo podrían cambiar la forma en que analizan sus datos en respuesta. Este manuscrito destaca y resume cuatro enfoques estadísticos generales que aumentan o reemplazan el valor p, y que son relativamente sencillos de aplicar. Primero, puede aumentar su valor p con información sobre qué tan seguro está en él, qué tan probable es que obtenga un valor p similar en un estudio replicado, o la probabilidad de que un hallazgo estadísticamente significativo sea de hecho falso. positivo. En segundo lugar, puede mejorar la información proporcionada por las estadísticas frecuentistas con un enfoque en los tamaños del efecto y una confianza cuantificada de que esos tamaños del efecto son precisos. En tercer lugar, puede aumentar o sustituir los valores p con el factor de Bayes para informar sobre los niveles relativos de evidencia para las hipótesis nula y alternativa; este enfoque es particularmente apropiado para estudios en los que desea seguir recopilando datos hasta que se hayan acumulado pruebas claras a favor o en contra de su hipótesis. Finalmente, específicamente cuando está utilizando múltiples variables para predecir un resultado a través de la construcción de modelos, los criterios de información de Akaike pueden tomar el lugar del valor p[1], proporcionando información cuantificada sobre qué modelo es mejor. Con suerte, esta guía rápida y fácil de algunas opciones estadísticas simples pero poderosas ayudará a los biólogos a adoptar nuevos enfoques cuando sientan que el valor p por sí solo no está haciendo justicia a sus datos.
_________________________________________________
1. Introducción
La posición materializada del valor p en los análisis estadísticos no fue cuestionada durante décadas a pesar de las críticas de los estadísticos y otros científicos[2]. En los últimos años, sin embargo, esta inquietud se ha intensificado, con una plétora de nuevos artículos que llevan a casa los argumentos anteriores en contra de p o suscitan críticas adicionales[3]. Catalizada por el papel que ha jugado el valor p en la crisis de reproducibilidad de la ciencia, esta crítica nos ha llevado al borde de un levantamiento contra el reinado de p.
En consecuencia, se está formando un vacío de poder de análisis, con una gama de enfoques alternativos que compiten por llenar el espacio. Los comentarios que critican el valor p a menudo sugieren paradigmas alternativos de análisis estadístico, y ahora una serie de opciones han tomado semilla en el campo de la biología. Los nuevos métodos estadísticos generalmente involucran conceptos que son contrarios a la intuición de nuestro entrenamiento basado en p; representan formas radicalmente diferentes de interrogar datos que involucran enfoques dispares para generar evidencia, diferentes paquetes de software y una serie de nuevos supuestos para comprender y justificar. Las curvas pronunciadas para aprender nuevos métodos podrían sofocar una mayor expansión de su uso en lugar de análisis estadísticos centrados en p en las ciencias biológicas.
Para brindar claridad y confianza a los biólogos que buscan expandir y diversificar sus enfoques analíticos, este manuscrito resume algunas alternativas manejables a la centralidad del valor p. Pero primero, aquí hay una breve descripción general sobre los límites del valor p y por qué, por sí solo, rara vez es suficiente para interpretar nuestros datos ganados con tanto esfuerzo. Junto con muchos otros estadísticos se han escrito convincentemente sobre sus preocupaciones con el concepto fundamental de prueba de significación de hipótesis nula. Debido a que el valor p se basa en que la hipótesis nula es verdadera, no nos da ninguna información sobre la hipótesis alternativa, la hipótesis en la que generalmente estamos más interesados. Para agravar este problema, si nuestro valor p es alto y por lo tanto no lo es rechazar la hipótesis nula, esto no puede interpretarse como si la nula sea verdadera; más bien, nos quedamos con un "veredicto abierto[4]". Además, con un tamaño de muestra suficientemente grande, inevitablemente se rechazará la hipótesis nula; perversamente, un resultado estadístico basado en el valor p es tan informativo sobre nuestra muestra como sobre nuestra hipótesis[5].
Recientemente, se han documentado más preocupaciones sobre p, vinculando el valor p con problemas con la replicación experimental[6]. Se ha demostrado que p es "voluble" porque puede variar mucho entre réplicas incluso cuando el poder estadístico es alto, y argumentó que esto hace que la interpretación del valor p sea insostenible a menos que p sea extremadamente pequeño[7]. Se ha argumentado que los valores p significativos justo por debajo de 0.05 son evidencia extremadamente débil contra la hipótesis nula porque hay una probabilidad de 1 en 3 de que el resultado significativo sea un falso positivo (también conocido como error tipo 1[8]). Interpretar p dicotómicamente como "significativo" o "no significativo" es particularmente atroz por muchas razones, pero lo más pertinente aquí es que este enfoque fomenta la repetición de experimentos fallidos. Los estudios a menudo están diseñados para tener un poder estadístico del 80%, lo que significa que existe un 80% de probabilidad de que se detecte un efecto en los datos. La probabilidad de que dos estudios idénticos potenciados estadísticamente al 80%, ambos arrojen p ≤ 0.05 es en el mejor de los casos 80% × 80% = 64%, mientras que la probabilidad de que uno de estos estudios arroje p ≤ 0.05 y el otro no es 2 × 80% × 20% = 32[9]%. Juntos, estos trabajos y cálculos demuestran que el valor p es típicamente muy impreciso sobre la cantidad de evidencia en contra de la hipótesis nula y, por lo tanto, se debe considerar que p proporciona solo evidencia vaga de primer paso sobre el fenómeno que se está estudiando[10].
Con la comprensión cada vez mayor entre los biólogos de que los valores p proporcionan solo evidencia tentativa sobre nuestros datos, y, de hecho, que exactamente lo que esta evidencia nos dice es fácil de malinterpretar, es importante que nos equipemos de una comprensión amplia de lo que son las opciones estadísticas. disponible que puede aclarar, o incluso suplantar, p. Si bien será difícil librarnos de nuestro enfoque adoctrinado para interpretar cada análisis estadístico a través del prisma de significación o no significación, podemos estar motivados por el conocimiento de que realmente hay otras formas, y de hecho formas más intuitivas, de investigar nuestro análisis datos. A continuación, una guía rápida y fácil de algunas opciones estadísticas simples pero poderosas que actualmente están disponibles para los biólogos que realizan diseños de estudios estándar. Cada enfoque estadístico distinto interroga los datos a través de una lente diferente, es decir, formulando una pregunta científica fundamentalmente diferente; esto se refleja en los títulos de las subsecciones que siguen. Comenzaremos con la opción menos disruptiva para el paradigma del valor p: aumentar p con información sobre su variabilidad.
2. Valor p: ¿cuánta evidencia hay en contra de la hipótesis nula?
p proporciona información poco intuitiva sobre sus datos. Sin embargo, quizás se pueda interpretar mejor como caracterizando la evidencia en los datos contra la hipótesis nula[11]. Y a pesar de sus limitaciones, el valor p tiene cualidades atractivas. Es un número único a partir del cual se puede realizar una interpretación objetiva de los datos. Además, podría decirse que esa interpretación es independiente del contexto; Los valores p se pueden comparar entre diferentes tipos de estudios y pruebas estadísticas[12]. Se sostiene que centrarse en el valor p es un primer paso adecuado para el cribado de múltiples hipótesis, como ocurre en la "biología de alto rendimiento", como el análisis de expresión génica y los estudios de asociación de todo el genoma[13].
Sin embargo, p se ve defraudado por la considerable variabilidad que presenta entre las muestras de estudio, variabilidad disfrazada por el informe de p como un valor único con varios decimales. Entonces, podría decirse que si desea continuar calculando p como parte de sus análisis de pruebas individuales, debe proporcionar alguna información adicional sobre esta variabilidad, para informar al lector sobre la incertidumbre de esta estadística. Una forma de lograrlo es proporcionar un valor que sea similar al intervalo de confianza en torno al tamaño del efecto, que caracteriza la incertidumbre del valor p de su estudio y se denomina intervalo de predicción del valor p. Otra opción es calcular el intervalo de predicción que caracteriza la incertidumbre del valor p de un estudio replicado futuro. Según una calculadora, si el valor p de su experimento es, por ejemplo, 0.01, tendrá un intervalo de predicción del 95% de 5.7−6 a 0.54. Claramente, esto nos proporcionaría poca confianza en que p sea replicable en este escenario experimental. Un valor p de 0.0001 tiene un intervalo de predicción del 95% de 0 a 0.05. En este segundo escenario, el intervalo de predicción del 95% de un estudio replicado futuro es 0-0.26[14]. Se argumenta que el intervalo de predicción alrededor de p calculado por este método devuelve subestimaciones de los límites superior e inferior. No obstante, la amplitud del intervalo de predicción, independientemente de cómo se calcule, será sorprendentemente grande para aquellos de nosotros acostumbrados a ver el valor p como un valor único desnudo informado con gran precisión.
Si ha calculado la potencia planificada de su estudio y está preparado para cuantificar el nivel de creencia que tenía antes de realizar el experimento de que la hipótesis nula es verdadera, puede aumentar p con la probabilidad estimada de que si obtiene un valor p significativo, está rechazando falsamente la hipótesis nula. Esto se denomina riesgo estimado de falso positivo (descubrimiento) y se puede estimar fácilmente a partir de un marco bayesiano simple[15]:
Riesgo falso positivo estimado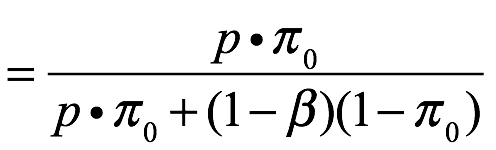
donde p es el valor p de su estudio, π0 es la probabilidad de que la hipótesis nula sea cierta según la evidencia previa y (1 - β) es el poder del estudio.
Por ejemplo, si ha potenciado su estudio al 80% y antes de realizar su estudio, cree que hay un 30% de posibilidad de que su perturbación tenga un efecto (por lo tanto, π0 = 0.7), y luego de haber realizado el estudio, su análisis devuelve p = 0.05, el riesgo de falso positivo estimado es del 13%. Es decir, muchas réplicas de este experimento indicarían un efecto estadísticamente significativo de la perturbación y se equivocarían al hacerlo aproximadamente el 13% de las veces. Sin embargo, tenga en cuenta que, dada la inconstancia de p antes mencionada, esta estimación del riesgo de falso positivo podría ser igualmente caprichosa. Esta preocupación se puede eludir para estudios de alto rendimiento, reemplazando p en la ecuación anterior por α (el umbral de significación de la prueba estadística) y estimando π0 a partir de los valores p observados[16].
Para aquellos que no están realizando estudios de alto rendimiento y a quienes no les gusta la idea de cuantificar subjetivamente sus expectativas a priori sobre la veracidad de su perturbación experimental, los cálculos pueden invertirse de manera que su valor p esté acompañado por un cálculo de la expectativa previa de que sería necesario
para producir un riesgo específico (por ejemplo, 5%) de que un valor p significativo sea un falso positivo ( y el autor proporciona una calculadora web[17] fácil de usar para este propósito[18]: http: // fpr- calc.ucl.ac.uk/). Esto proporciona una forma alternativa de evaluar la probabilidad de que un valor p significativo sea un verdadero positivo. Si, por ejemplo, su valor p es 0.03 para un estudio potenciado a aproximadamente el 70%, para limitar el riesgo de un falso positivo al 5%, su expectativa previa de que la perturbación tendrá un efecto debería ser del 77% (basado en el caso 'p-igual').
3. Tamaño del efecto e intervalo de confianza: ¿cuánto y con qué precisión?
Un resultado estadísticamente significativo nos dice relativamente poco sobre el fenómeno que estamos estudiando, solo que la hipótesis nula de ningún “efecto” en nuestros datos ha sido rechazada[19]. En lugar de la pregunta científica del valor p '¿hay o no hay un efecto?', Se obtiene mucha más información preguntando '¿qué tan fuerte es el efecto en nuestra muestra?', Junto con la pregunta '¿qué tan exacto es ese valor como una estimación de cuán fuerte es el efecto poblacional? '.
La forma más sencilla de analizar sus datos para responder estas dos preguntas es calcular el tamaño del efecto en la muestra junto con los intervalos de confianza del 95% alrededor de esa estimación[20]. Afortunadamente, el tamaño del efecto a menudo es fácil de calcular o extraer de los resultados estadísticos, ya que normalmente es la diferencia media entre dos grupos o la fuerza de la correlación entre dos variables. Y aunque la definición de un intervalo de confianza es compleja, se argumenta de manera convincente que es razonable interpretar un intervalo de confianza como una indicación de la precisión de la estimación del tamaño del efecto; es la estimación del error probable[21].
Los cálculos de los intervalos de confianza y los valores p comparten el mismo marco matemático[22], pero esto no quita el hecho de que centrar la interpretación de los datos en los tamaños del efecto y sus intervalos de confianza es un enfoque fundamentalmente diferente al de la interpretación de enfoque. sobre si rechazar o no la hipótesis nula[23]. Estos dos procedimientos plantean preguntas muy diferentes sobre los datos y obtienen respuestas distintas. Una interpretación basada en el tamaño del efecto y los intervalos de confianza podría, por ejemplo, afirmar: nuestros resultados sugieren que el… sin embargo, una diferencia en también es razonablemente probable. Se señala que el último enfoque reconoce la incertidumbre en el tamaño del efecto estimado y al mismo tiempo garantiza que no haga una afirmación falsa, ya sea sin efecto si p> 0,05, o una afirmación demasiado confiada. Y si todos los valores dentro del intervalo de confianza no son biológicamente importantes, entonces también se puede hacer una declaración de que sus resultados no indican ningún efecto importante[24].
El enfoque de centrarse en la estimación del tamaño del efecto suele ir acompañado de un énfasis en la visualización de los datos para respaldar su evaluación. Un formato gráfico sólido que logre esto implica un panel principal que muestra los datos brutos y paneles laterales que ayudan a ilustrar el tamaño del efecto estimado[25]. Se han desarrollado recientemente “ESTIMATION STATISTICS BETA ANALYZE YOUR DATA WITH EFFECT SIZES” para diferentes plataformas como R, todas las versiones tienen instrucciones de memoria fáciles de usar para producir gráficos que permiten una exploración completa de sus datos (ver URL:https://www.estimationstats.com/#/).
La investigación científica busca centrarse en las "respuestas", y los tamaños de efecto estimados y sus intervalos de confianza son fundamentales para este objetivo. En biología al menos, buscar una respuesta casi inevitablemente requiere múltiples estudios, que luego deben analizarse juntos, a través del metanálisis. Los tamaños del efecto y los intervalos de confianza son la información vital para este proceso, lo que proporciona otro buen argumento para su informe exhaustivo en los artículos. Por lo general, los intervalos de confianza alrededor de un tamaño del efecto calculado a partir de un metanálisis son mucho más pequeños que los de los estudios individuales[26], lo que proporciona una imagen mucho más clara sobre el verdadero tamaño del efecto a nivel de población. Sin embargo, los metanálisis pueden verse profundamente comprometidos por el "fenómeno del cajón de archivos", donde los resultados no significativos no se publican[27], ya sea porque los investigadores no los envían o las revistas no los aceptan. Afortunadamente, las actitudes de los patrocinadores de la ciencia, los editores y los investigadores están comenzando a cambiar sobre el valor y la importancia de informar sobre resultados no significativos; este impulso debe continuar.
4. Factor de Bayes: ¿cuál es la evidencia de una hipótesis en comparación con otra?
En contraste con el valor p que proporciona solo información sobre la probabilidad de que la hipótesis nula sea verdadera, el factor de Bayes aborda directamente tanto la hipótesis nula como la alternativa. El factor de Bayes cuantifica la evidencia relativa en los datos que ha recopilado sobre si esos datos están mejor predichos por la hipótesis nula o la hipótesis alternativa (un efecto de magnitud declarada). Por ejemplo, un factor de Bayes de 5 indica que la fuerza de la evidencia es cinco veces mayor para la hipótesis alternativa que para la hipótesis nula; un factor de Bayes de 1/5 indica lo contrario.
El factor de Bayes es una forma simple e intuitiva de realizar la versión bayesiana de la prueba de significación de hipótesis nula. Recientemente, los factores de Bayes se han hecho manejables para el biólogo en ejercicio, y ahora son fácilmente calculables para una variedad de diseños de estudios estándar. Los factores de Bayes para muchos diseños se pueden ejecutar en calculadoras basadas en web (por ejemplo en leguaje R: https://richarddmorey.github.io/BayesFactor/).
Una controversia del enfoque bayesiano es la necesidad de que usted especifique su fuerza de creencia en el efecto que se está estudiando antes de que tenga lugar el experimento (la distribución previa de la hipótesis alternativa[28]). Por lo tanto, su elección algo subjetiva del "anterior o prior“ influye en el resultado del análisis. Se argumentan que esta crítica de las estadísticas bayesianas es a menudo exagerada porque la influencia del prior es limitada cuando se usa una distribución previa razonable. Puede evaluar la influencia del previo con un análisis de sensibilidad simple mediante el cual el análisis se ejecuta utilizando un rango limitado de probabilidades previas realistas[29]. También hay una prior predeterminado que puede usar en situaciones comunes cuando tiene poca evidencia previa al estudio sobre el tamaño del efecto esperado.
No obstante, la realización de análisis bayesianos es más complicado que la prueba de significación de hipótesis nulas, y especificar lo anterior indudablemente añade cierto grado de subjetividad. Afortunadamente, existe una fórmula simple y única que puede aplicar para convertir un valor p en una forma del factor de Bayes sin ninguna otra información. Este factor de Bayes simplificado, denominado límite superior, establece que lo más probable es que la hipótesis alternativa sea verdadera en lugar de la hipótesis nula sobre cualquier distribución previa razonable[30]:
Factor de Bayes en el límite superior
Por ejemplo, si sus datos generan un valor p de 0.07 (a veces denominado "tendencia"), el límite superior del factor de Bayes es 1.98 y puede concluir que la hipótesis alternativa es como mucho dos veces más probable que la hipótesis nula. Un valor p de 0.01 indica que la hipótesis alternativa es como máximo 8 veces más probable que la nula. Se argumenta que este enfoque es una alternativa fácil de interpretar p, que debería satisfacer tanto a los practicantes de la estadística bayesiana como a los practicantes de la prueba de significación de hipótesis nulas[31].
Suele argumentarse que el factor de Bayes puede usarse para informar cuando un estudio ha asegurado un tamaño de muestra suficiente y puede ser detenido. Las reglas de detención efectivas en la investigación pueden ser invaluables para controlar el tiempo y los costos financieros al tiempo que aumentan la replicabilidad del estudio, y son éticamente importantes para ciertos estudios en animales o estudios intrusivos en humanos; el uso de sujetos debe minimizarse al tiempo que se asegura que los experimentos sean sólidos y reproducibles[32] (URL: https://www.nc3rs.org.uk/contemporary-training-3rs). Podría decirse que las reglas de detención deberían usarse mucho más de lo que se usan actualmente, y pueden ser un método mucho más efectivo para apuntar a un tamaño de muestra adecuado que el análisis de poder. Sin embargo, un gran error que se comete a menudo es implementar el valor p en la regla de detención; el estudio se detiene cuando los datos recopilados hasta ahora arrojan un valor p estadísticamente significativo. La suposición subyacente es que aumentar aún más el tamaño de la muestra probablemente disminuiría p aún más. Un modelo simple demuestra que este pensamiento es espurio y, por lo tanto, conduce a una práctica muy mala. Para aquellos de nosotros que basamos nuestro estudio en el valor p, es preferible continuar un estudio hasta que se alcance un tamaño de muestra predeterminado que haya sido decidido a priori por análisis de poder[33]. Sin embargo, este enfoque está muy influenciado por la estimación del tamaño del efecto a priori asociado que hemos proporcionado y puede haber una fuerte tentación de aumentar el tamaño de la muestra más allá del número predeterminado; los investigadores que anhelan un resultado estadísticamente significativo pueden sucumbir fácilmente a la tentación de recopilar puntos de datos adicionales cuando su valor p es 0.06 o 0.07[34].
El factor Bayes es mucho más apropiado aquí. Proporciona evidencia para el nulo, y con una muestra lo suficientemente grande, el factor de Bayes convergerá en 0 (el nulo es verdadero) o infinito (la alternativa es verdadera). Si el factor de Bayes de sus datos alcanza 10 o 1/10, es casi seguro que esto representa la situación real y su estudio puede detenerse. Alternativamente, si su estudio debe detenerse por razones logísticas, el factor de Bayes final aún se puede interpretar; por ejemplo, un factor de Bayes de 1/7 indicaría evidencia moderada para la hipótesis nula. Además, tiene derecho a seguir muestreando si cree que los datos no son lo suficientemente concluyentes; si los resultados no son claros, recopile más datos. Todas estas decisiones no afectan la interpretación del factor de Bayes[35]. Una gran motivación final para emplear el factor de Bayes sobre el valor p en los procedimientos de detención es que, a largo plazo, el primero utiliza una muestra más pequeña y, al mismo tiempo, genera menos errores de interpretación. Aún no se ha alcanzado un consenso general sobre los antecedentes más adecuados para cada situación, y hasta ahora solo se han producido procedimientos de factor de Bayes manejables para algunos diseños experimentales. Pero no dejes que esto te desanime. En lugar del factor de Bayes, se puede utilizar el límite superior del factor de Bayes, como se describe anteriormente.
5. Criterio de Akaike
Si su estudio implica medir una variable de resultado y múltiples variables explicativas potenciales, entonces tiene muchos modelos posibles que podría construir para explicar la varianza en sus datos. Los procedimientos escalonados de construcción de modelos a menudo se centran en los valores p, al aferrarse solo a las variables explicativas asociadas con una p baja. Aparte de las preocupaciones generales acerca de p, las críticas específicas a la construcción de modelos basados ??en el valor p incluyen el riesgo inflado de errores de tipo 1[36]. Un enfoque alternativo a la evaluación del modelo es el criterio de información de Akaike (AIC), que se puede calcular fácilmente en paquetes de software estadístico, y en R utilizando AIC (). El AIC le proporciona una estimación de qué tan cerca está su modelo de representar la realidad completa[37], o en otras palabras, su precisión predictiva. Enmarcado en el principio de simplicidad y parsimonia, un aspecto fundamental del AIC es que intercambia la bondad de ajuste de un modelo con la complejidad de ese modelo para asegurarse contra un ajuste excesivo[38] [52].
Imaginemos que ha generado tres modelos, devolviendo AIC de 443 (modelo 1), 445 (modelo 2) y 448 (modelo 3). Su modelo preferido en términos de calidad relativa será el que devuelva el AIC mínimo. Pero no necesariamente debe descartar los otros modelos. Con el AIC calculado para múltiples modelos, puede calcular fácilmente la probabilidad relativa de que cada uno de esos modelos sea el mejor de todos los modelos presentados dados sus datos, es decir, la evidencia relativa para cada uno de ellos. Por ejemplo, el modelo preferido siempre tendrá una evidencia relativa de 1 y, en el ejemplo actual, el segundo mejor modelo, el modelo 2, tiene una evidencia relativa de 0.37 y el modelo 3 tiene 0,08. Por último, puede calcular una relación de evidencia entre cualquier par de modelos; Siguiendo el ejemplo anterior, la evidencia para el modelo 1 sobre el modelo 2 es 1 / 0.37 = 2.7, es decir, la evidencia para el modelo 1 es 2.7 veces más fuerte. En este escenario, aunque el modelo 1 tiene el AIC absoluto más bajo, la evidencia de que el modelo 1 en lugar del modelo 2 es el mejor de los generados no es sólida, y con algunas variables explicativas presentes en solo uno de los modelos, la respuesta más adecuada podría Debe hacer sus inferencias basadas en ambos modelos. El enfoque AIC lo alienta a pensar detenidamente sobre modelos alternativos y, por lo tanto, hipótesis, en contraste con la interpretación del valor p que alienta a rechazar el nulo cuando p es pequeño y respaldar la hipótesis alternativa por defecto[39]. En términos más generales, el paradigma AIC implica descartar hipótesis consideradas inverosímiles, refinar las hipótesis restantes y agregar nuevas hipótesis, una estrategia científica que argumenta y promueve un aprendizaje rápido y profundo sobre el fenómeno que se estudia.
Aunque el AIC está relacionado matemáticamente con el valor p (son diferentes transformaciones de la razón de verosimilitud), el primero es mucho más flexible en los modelos que puede comparar. El AIC es una opción sólida para elegir entre múltiples modelos que ha generado para explicar sus datos, es decir, elegir qué modelo representa su mejor comprensión del fenómeno que ha medido, particularmente cuando los datos observados son complejos y poco entendidos y usted no espere que sus modelos tengan un poder predictivo particularmente fuerte[40].
Una limitación clave del AIC es que proporciona una prueba relativa, no absoluta, de la calidad del modelo. Es fácil caer en la trampa de asumir que el mejor modelo también es un buen modelo para sus datos; este puede ser el caso, o en cambio, el mejor modelo puede tener solo la mitad de un ojo en la variación en sus datos, mientras que todos los demás modelos son ciegos. La cuantificación de la calidad absoluta de sus mejores modelos requiere el cálculo del tamaño del efecto, como se discutió anteriormente (en el caso de los modelos, normalmente R^2 es adecuado).
6. Conclusión
La buena ciencia genera datos sólidos listos para la interpretación. Hay varios enfoques amplios para el análisis estadístico de datos, cada uno de los cuales interroga las variables recopiladas a través de una línea distinta de preguntas. Popper argumentó que la ciencia se define por la falsificación de sus teorías. Tomando este enfoque de la ciencia, los valores p podrían ser la pieza central legítima de su análisis estadístico, ya que brindan evidencia en contra de la hipótesis nula. Basándose en este paradigma, puede mejorar fácilmente la interpretación del valor p aumentando p con un intervalo de predicción y/o una estimación del riesgo de falso positivo: información sobre la confiabilidad de p. Sin embargo, un argumento en contra es que debido a que el valor p no prueba la hipótesis nula ni la hipótesis alternativa, nunca se puede usar para falsificar una teoría. Convertir el valor p en un factor de Bayes atiende a esta preocupación, proporcionando evidencia relativa para una hipótesis u otra. Pero muchos han argumentado que la prueba de hipótesis con cualquier enfoque se reemplaza al enfocarse en el efecto en los datos, específicamente tanto en su magnitud como en su precisión, porque su mejor estimación de la magnitud del fenómeno que está estudiando es, en última instancia, lo que desea saber. Y si realiza un análisis multivariable, especialmente cuando el fenómeno en estudio no se comprende bien, la AIC puede servirle bien, lo que fomenta la consideración de múltiples hipótesis y su refinamiento gradual.
Es importante enfatizar que estos múltiples enfoques no son todos mutuamente excluyentes; por ejemplo, muchos argumentarían que las estimaciones del tamaño del efecto son un componente esencial de la mayoría de los análisis. De hecho, llegan a recomendar el uso de un híbrido para la toma de decisiones que requiere un valor p bajo junto con un tamaño del efecto por encima de un mínimo determinado a priori para ser relevante/importante para rechazar la hipótesis nula. Los valores p también se pueden presentar junto con los factores de Bayes para cada prueba estadística realizada ("una B para cada p"). Continuar presentando valores p como parte de su producción estadística mientras diluye su poder interpretativo al incluir otros enfoques estadísticos debería garantizar que su envío no se vea comprometido, y de hecho, este enfoque es probablemente la mejor manera de empujar a los revisores y editores a aceptar, incluso alentar, la aplicación de paradigmas inferenciales alternativos. Cualquiera que sea su enfoque estadístico elegido, es importante que se haya determinado antes de la recopilación de datos. Armarse con más opciones estadísticas podría correr el riesgo de la tentación de probar diferentes enfoques hasta que se logre un resultado emocionante; esto debe ser resistido.
Independientemente del paradigma estadístico que emplee para investigar patrones en sus datos, muchos han recomendado que los resultados de las pruebas estadísticas siempre se consideren interrogaciones secundarias. En primer lugar, según el argumento, debe priorizar la interpretación de los diagramas gráficos de sus datos, cuando sea posible, y tratar los análisis estadísticos como información de apoyo o confirmación. Una gráfica que no parece respaldar los hallazgos de su análisis estadístico no debe explicarse automáticamente como una demostración de que su análisis ha descubierto patrones que son más profundos de lo que se pueden visualizar.
Finalmente, aunque esperamos que esta revisión pueda ayudar a los lectores a sentirse un poco más informados y confiados sobre algunas de las opciones estadísticas adicionales y alternativas al valor p, vale la pena recordar las palabras pertinentes de Sir Ronald Fisher en su discurso en 1938: «Llamar a un estadístico una vez realizado el experimento puede que no sea más que pedirle que realice un examen post-mortem: es posible que pueda decir de qué murió el experimento”. Sin un buen conjunto de datos, ninguna de las herramientas estadísticas mencionadas aquí será eficaz. Además, incluso un buen conjunto de datos representa un solo estudio, y no debe olvidarse que un solo estudio proporciona información limitada. En última instancia, la replicación es clave para refinar y tener confianza en nuestra comprensión del mundo biológico.
Referencias
[1] Brooks, Daniel. (2012). Akaike Information Criterion Statistics. Technometrics. 31. 270-271.
DOI:10.1080/00401706.1989.10488538.
[2] Gandevia, Simon & Cumming, Geoff & Amrhein, Valentin & Butler, Annie. (2021). Replication: Do not trust your p-value, be it small or large. The Journal of Physiology. 599.
DOI:10.1113/jp281614.
[3] Senn, Stephen. (2021). Probability, Bayes, P-values, Tests of Hypotheses and Confidence Intervals.
DOI:10.1002/9781119238614.ch4.
[4] Dushoff, Jonathan & Kain, Morgan & Bolker, Benjamin. (2019). I can see clearly now: Reinterpreting statistical significance. Methods in Ecology and Evolution.
DOI:10. 10.1111/2041-210X.13159.
[5] Wilcox, Rand. (2020). Regression: Determining Which of p Independent Variables Has the Largest or Smallest Correlation with the Dependent Variable, Plus Results on Ordering the Correlations Winsorized. Journal of Modern Applied Statistical Methods. 18. DOI:10.22237/jmasm/1604190840.
[6] Pramesh, CS & Ranganathan, Priya. (2019). An Introduction to Statistics: Understanding Hypothesis Testing and Statistical Errors. Indian Journal of Critical Care Medicine. 23.
DOI:10.5005/jp-journals-10071-23259.
[7] Schmalz, Xenia & Biurrun Manresa, José & Zhang, Lei. (2021). What is a Bayes factor?. Psychological Methods. DOI:10.1037/met0000421.
[8] Nostedt Sarah et. al. (2021). Reverse Bayesian Implications of p-Values Reported in Critical Care Randomized Trials. Journal of Intensive Care Medicine. 088506662110537. DOI:10.1177/08850666211053793.
[9] Muff, Stefanie & Nilsen, Erlend & O'Hara, Bob & Nater, Chloé. (2021). Rewriting results sections in the language of evidence. Trends in Ecology & Evolution.
DOI:10.1016/j.tree.2021.10.009.
[10] Boos, Dennis & Stefanski, Leonard. (2011). P-Value Precision and Reproducibility. The American statistician. 65. 213-221. DOI:10.1198/tas.2011.10129.
https://www.researchgate.net/publication/225293821_P-Value_Precision_and_Reproducibility
[11] Lew, Michael. (2013). To P or not to P: on the evidential nature of P-values and their place in scientific inference. Source arXiv
[12] Lu, Jiannan & Qiu, Yixuan & Deng, Alex. (2018). A note on Type S/M errors in hypothesis testing. British Journal of Mathematical and Statistical Psychology. 72.
DOI:10.1111/bmsp.12132.
[13] Altoè, Gianmarco & Bertoldo, Giulia & Zandonella Callegher, Claudio & Toffalini, Enrico & Calcagnì, Antonio & Finos, Livio & Pastore, Massimiliano. (2020). Enhancing Statistical Inference in Psychological Research via Prospective and Retrospective Design Analysis. Frontiers in Psychology. 10.
DOI:10.3389/fpsyg.2019.02893.
[14] Vsevolozhskaya, Olga & Ruiz, Gabriel & Zaykin, Dmitri. (2017). Bayesian prediction intervals for assessing P-value variability in prospective replication studies. Translational Psychiatry. 7.
DOI:10.1038/s41398-017-0024-3.
[15] Hardwicke, Tom & Ioannidis, John. (2019). Petitions in scientific argumentation: Dissecting the request to retire statistical significance. European Journal of Clinical Investigation. 49.
DOI:10.1111/eci.13162.
[16] Voelkl, Bernhard & Würbel, Hanno & Krzywinski, Martin & Altman, Naomi. (2021). The standardization fallacy. Nature Methods. 18. 5-7.
DOI:10.1038/s41592-020-01036-9.
[17] False Positive Risk Web Calculator, version 1.7 Longstaff,C. and Colquhoun D, http://fpr-calc.ucl.ac.uk/ Last accessed 2021-12-03
[18] Colquhoun, D. (2019b) A response to critiques of "The reproducibility of research and the misinterpretation of p-values". Royal Society Open Science http://fpr-calc.ucl.ac.uk
[19] Young, Michael. (2019). Modern statistical practices in the experimental analysis of behavior: An introduction to the special issue: MODERN STATISTICAL PRACTIES. Journal of the Experimental Analysis of Behavior. 111. 149-154.
DOI:10.1002/jeab.511.
[20] Amrhein, Valentin & Korner-Nievergelt, Fränzi & Roth, Tobias. (2017). The earth is flat (p>0.05): Significance thresholds and the crisis of unreplicable research.
DOI:10.7287/peerj.preprints.2921v1.
[21] McManus, Kevin. (2021). Replication and Open Science in Applied Linguistics Research. Open science in applied linguisticsPublisher: John Benjamins
[22] Cumming, Geoff. (2013). The New Statistics: A How-To Guide. Australian Psychologist. 48.
DOI:10.1111/ap.12018.
[23] Amrhein, Valentin & Greenland, Sander & McShane, Blake. (2019). Retire statistical significance. Nature. 567. 305-307.
DOI:10.1038/d41586-019-00857-9.
[24] Lemos Correia, Luis & Oliveira Bagano, Gabriela & de Melo, Milton. (2020). Should we retire statistical significance?. Brazilian Journal Of Pain. 3.
DOI:10.5935/2595-0118.20200199.
[25] Mohammad, Farhan & Ho, Joses & Woo, Jia & Lim, Chun & Poon, Dennis & Lamba, Bhumika & Claridge-Chang, Adam. (2016). Concordance and incongruence in preclinical anxiety models: Systematic review and meta-analyses. Neuroscience & Biobehavioral Reviews. 68.
DOI:10.1016/j.neubiorev.2016.04.011.
[26] Systematic review and stratified meta-analysis of the efficacy of interleukin-1 receptor antagonist in animal models of stroke. J Stroke Cerebrovasc Dis. 2009 Jul-Aug;18(4):269-76.
DOI: 10.1016/j.jstrokecerebrovasdis.2008.11.009.
[27] Ashkarran, Ali Akbar & Swann, Jennifer & Hollis, Leah & Mahmoudi, Morteza. (2021). The File Drawer Problem in Nanomedicine. Trends in Biotechnology. 39.
DOI:10.1016/j.tibtech.2021.01.009.
[28] Fox, Jean-Paul & Mulder, Joris & Sinharay, Sandip. (2017). Bayes Factor Covariance Testing in Item Response Models. Psychometrika (link http://rdcu.be/vpb0 ). 82.
DOI:10.1007/s11336-017-9577-6.
[29] Schoot, Rens & Depaoli, Sarah & King, Ruth & Kramer, Bianca & Märtens, Kaspar & Tadesse, Mahlet & Vannucci, Marina & Gelman, Andrew & Veen, Duco & Willemsen, Joukje & Yau, Christopher. (2021). Bayesian statistics and modelling. Nature Reviews Methods Primers. 1.
DOI:10.1038/s43586-020-00001-2.
[30] Muff, Stefanie & Nilsen, Erlend & O'Hara, Bob & Nater, Chloé. (2021). Rewriting results sections in the language of evidence. Trends in Ecology & Evolution.
DOI:10.1016/j.tree.2021.10.009.
[31] Kim, Jae. (2021). Moving to a world beyond p-value < 0.05: a guide for business researchers. Review of Managerial Science. 1-27.
DOI:10.1007/s11846-021-00504-6.
[32] Thirumoorthy, Pradeep. (2019). Application of 3R Principles in construction Project – A Review. International Journal of Industrial and Systems Engineering. 2. 1-3.
[33] Murphy, Kevin & Myors, Brett & Wolach, Allen. (2014). Statistical Power Analysis.
DOI:10.4324/9781315773155.
[34] Garrido, Mario & Hansen, Scott & Yaari, Rami & Hawlena, Hadas. (2021). A model selection approach to structural equation modelling: A critical evaluation and a road map for ecologists. Methods in Ecology and Evolution.
DOI:10.1111/2041-210x.13742.
[35] Schönbrodt, Felix & Wagenmakers, Eric-Jan & Zehetleitner, Michael & Perugini, Marco. (2015). Sequential Hypothesis Testing With Bayes Factors: Efficiently Testing Mean Differences. Psychological methods. 22.
DOI:10.1037/met0000061.
[36] Brooks, Daniel. (2012). Akaike Information Criterion Statistics. Technometrics. 31. 270-271.
DOI:10.1080/00401706.1989.10488538.
[37] Korner-Nievergelt, Fränzi & Roth, Tobias & von Felten, Stefanie & Guélat, Jérôme & Almasi, Bettina & Korner, Pius. (2015). Model Selection and Multimodel Inference.
DOI: 10.1016/B978-0-12-801370-0.00011-3.
[38] Dykstra, Richard. (2005). Kullback–Leibler Information.
DOI:10.1002/0470011815.b2a15065.
[39] STEIDL, ROBERT. (2009). Model Selection, Hypothesis Testing, and Risks of Condemning Analytical Tools. Journal of Wildlife Management. 70. 1497-1498.
DOI:10.2193/0022-541X(2006)70[1497:MSHTAR]2.0.CO;2.
[40] Beltrán, Diego & Shultz, Allison & Parra, Juan. (2021). Speciation rates are positively correlated with the rate of plumage color evolution in hummingbirds. Evolution. 75.
DOI:10.1111/evo.14277.
Autores:
Eduardo Ochoa Hernández
Nicolás Zamudio Hernández
Berenice Yahuaca Juárez
Erasmo Cadenas Calderón
Abraham Zamudio Durán
Lizbeth Guadalupe Villalon Magallan
Pedro Gallegos Facio
Gerardo Sánchez Fernández
Rogelio Ochoa Barragán
Monica Rico Reyes